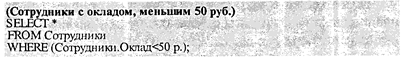Гайдамакин Н. А. 10 страница
Для примера приведем запросы по добавлению в таблицу «Сотрудники» нового поля «Оклад», добавлению нового индекса «ОкладСотрудники», удалению поля «Оклад», добавлению внешнего ключа «№_Отдела» и удалению внешнего ключа: ALTER TABLE Сотрудники ADD COLUMN Оклад CURRENCY; ALTER TABLE Coтрудники АDD CONSTRAINT OкладCoтрудники Оклад; ALTER TABLE Сотрудники DROPCOLUMN Oклад; ALTER TABLE Сотрудники ADD CONSTRAINT Работа FOREIGN KEY (№_Отдела) REFERENCES Подразделения (№_Отдела); ALTER TABLE Сотрудники DROP CONSTRAINT Работа; Запросы на удаление таблицы или индекса реализуются SQL-инструкцией DROP TABLE с указанием имени удаляемой таблицы или индекса. Следующий пример иллюстрирует удаление из базы данных таблицы «Сотрудники» и удаление индекса «ОкладСотрудники»: DROPTABLE Сотрудники; DROPINDEX ОкладСотрудники ON Сотрудники; Запросы на создание индекса реализуются SQL-инструкцией CREAТЕINDEX с использованием зарезервированного слова UNIQUE для запрета повтора значений в индексируемом поле и необязательного предложения WITH с параметрами DISALLOW NULL и IGNORE NULL для запрета/разрешения нулевых (пустых) значений в индексируемом поле. Зарезервированное слово PRIMARY позволяет определить создаваемый индекс ключом таблицы (при этом создаваемый индекс по умолчанию является уникальным, т.е. повторы значений не допускаются). В следующем примере в таблице «Сотрудники» создастся уникальный индекс «ИндексСотрудника» по полю «Таб_№» с запретом пустых значений: CREAТЕ UNIQUE INDEX ИндексСотрудника ON Сотрудники (Таб_№) WITH DISALLOW NULL; 4.3.2.4. Подчиненные (сложные) запросы Как уже отмечалось, источником данных для запросов могут быть результаты выполнения других запросов. Возможны два варианта построения таких запросов. Первый вариант реализуется через указание в SQL-инструкциях в качестве имен таблиц и имен полей имен запросов и полей запросов. Синтаксис таких запросов ничем не отличается от обычных запросов, а его исполнение осуществляется в две фазы. По запуску основного запроса сначала неявно запускается запрос, формирующий источник данных, и по завершению его исполнения запускается основной (внешний) запрос. Второй вариант реализуется через включение в тело внешней (главной) SQL-инструкции внутренней инструкции SELECT. При этом результат исполнения внутренней инструкции SELECT используется для формирования условия отбора записей в главном (внешнем) запросе или в качестве выражения для нового вычисляемого поля. Такие запросы называются подчиненными. Использование внутренней инструкции SELECT для формирования условий отбора записей во внешнем запросе возможно одним из трех способов: • через предикаты сравнения «для некоторых/для всех» — ANY, SOME, ALL; • через предикат вхождения IN; • через предикат существования EXISTS. В первом способе конструкция запроса может выглядеть следующим образом: SELECT.. FROM...WHERE Выражениеà[ ANY|SOME|ALL ] (SELECT...); где à — оператор сравнения. Как правило, выражение включает поле из списка полей внешней SQL-инструкции или функцию от этих полей. Внутренняя инструкция SELECT должна возвращать набор данных по одному полю или по вычисляемому полю, при принципиальной сравнимости с выражением во внешней SQL-инструкции (главным образом по типу данных). Предикаты ANY и SOME («для некоторых»), являющиеся синонимами, используются для отбора в главной SQL-инст-рукции тех записей, которые удовлетворяют сравнению с какой-либо записью (т. е. хотя бы с одной), из отобранных во внутренней инструкции SELECT. Для примера на рис. 4.23, а приведен запрос по отбору из таблицы «Заявки» тех записей, которые могут быть удовлетворены в соответствии с данными по таблице «Квартиры», т. е. тех записей из таблицы «Заявки», которые удовлетворяют сравнению по полям «КолКомп», «Площадь» и «Этаж» хотя бы с некоторыми (ANY) записями из таблицы «Квартиры», выбираемыми при условии «Продано=Нет».
Рис. 4.23, а. Пример подчиненного запроса на основе предиката ANY Предикат ALL (для всех) используется для отбора в главном запросе только тех записей, которые удовлетворяют сравнению одновременно со всеми записями, отобранными в подчиненном запросе. Пример выполнения запроса с предикатом ALL приведен на рис. 4.23, б.
Рис. 4.23, б. Пример подчиненного запроса па основе предиката ALL Принцип действия запроса по второму способу заключается в поиске среди результирующего набора записей внешней SQL-инструкции тех записей, для которых значение определенного выражения входит в список записей, отбираемых внутренней инструкцией SELECT. Конструкция запроса с предикатом IN выглядит следующим образом: SELECT... FROM... WHERE Выражение [ NOT ] IN (SELECT...); В качестве примера на рис. 4.24 приведен запрос по тем же исходным данным (таблицы «Сотрудники» и «Премирование») для отбора записей только тех сотрудников, записи которых по премиям были в списке премий, равных или превышающих 100%.
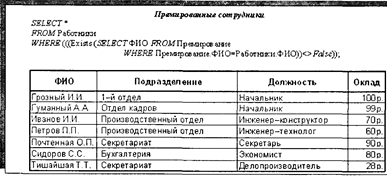
Рис. 4.24. Пример с подчиненным запросом на основе предиката IN Следует добавить, что предикат NOT IN используется для отбора во внешней SQL-инструкции только тех записей, которые содержат значения, не совпадающие ни с одним из отобранных внутренней инструкцией SELECT. В третьем способе построения подчиненного запроса предикат EXISTS (с необязательным зарезервированным словом NOT) используется в логическом выражении для определения того, должен ли подчиненный запрос возвращать какие-либо записи. Исходя из этого, каждая запись, отбираемая во внешней SQL-инструкции, идет в итоговый набор данных только тогда, когда при ее условиях отбирается (существует) хотя бы одна запись по внутренней инструкции SELECT. Конструкция запроса в этом случае может выглядеть следующим образом: SELECT...FROM..WHERE ([NOT] Exists (SELECT...)); В следующем примере на рис. 4.25 по таблицам, представленным на рис. 4.24, иллюстрируется запрос по отбору записей сотрудников, премированных хотя бы один раз, т.е. таких, у которых существует запись в списке премированных.
Рис. 4.25. Пример с подчиненным запросом на основе предиката EXISTS Следует заметить, что использование предиката NOT EXISTS сформирует список ни разу не премированных сотрудников. В последнем примере можно также увидеть, что альтернативным решением для реализации такого запроса является использование запроса на внутреннее соединение (INNER JOIN). Внутренняя инструкция SELECT может также использоваться в качестве выражения для вычисляемого поля внешней SQL-инструкции. Конструкция запроса в этом случае может выглядеть следующим образом: SELECT... (SELECT... ИмяВычПоля FROM..WHERE...; Обязательным условием при этом является то, чтобы внутренняя инструкция SELECT для каждой отбираемой по внешней SQL-инструкции записи возвращала не более чем одну запись но не более чем одному полю. Приведем пример подобного запроса, отбирающего все записи по полю «Марка» из таблицы «Товары», с формированием дополнительного поля «Категория», значения которого возвращаются внутренней инструкцией SЕLЕСТ из таблицы «ТипыТоваров» при условии совпадения значения поля «КодТипа» из таблицы «Товары» для текущей записи внешней SQL-инструкции с аналогичным полем «КодТипа» в записях таблицы «ТипыТоваров»: SELECT Товары.Марка, (SELECT ТипыТоваров.Категория FRОМ Типы WHERE (Товары.КодТипа=ТипыТоваров.КодТипа);) AS Категория FROM Товары; Нетрудно заметить, что целью использования в данном примере внутренней инструкции SELECT является формирование в наборе данных, отбираемых из таблицы на стороне «Многие», дополнительного поля по значению какого-либо поля из связанной таблицы на стороне «Один». Исходя из этого, альтернативным способом решения данной задачи может быть использование запроса на внутреннее соединение: SELECT Товары.Марка,ТипыТоваров.Категория FROM Товары INNER JOINT ТипыТоваров ON Товары.Код-Типа = ТипыТоваров.КодТипа; В тех случаях, когда отбор данных внешней SQL-инструкцией осуществляется из таблицы на стороне «Один», внутренняя инструкция SELECT может использоваться для дополнительного поля, формируемого на основе групповой операции по группам соответствующих связанных записей в таблице на стороне «Многие». Приведем пример отбора записей по полю «Категория» из таблицы «ТипыТоваров» с дополнительным полем «СредняяЦена», формируемым на основе статистической функции AVG по полю «Цена» для групп связанных записей в таблице «Товары»: SELECT ТипыТоваров.Категория, (SELECT Avg(Toвары.Цена) AS СредняяЦена FROM Товары GROUPВY Товары.КодТипа НАVING (ТипыТоваров.КодТипа=Товары.КодТипа);) АS СредняяЦена FROM ТипыТоваров; Опять-таки отметим, что альтернативным решением по данному примеру может быть использование следующего запроса на внутреннее соединение: SELECT ТипыТоваров.Категория, Avg(Toвapы.Цена) AS СредняяЦена FROM ТипыТоваров INNER JOINT Товары ON ТипыТоваров.КодТипа=Товары.КодТипа GROUP ВY ТипыТоваров.Категория; 4.3.2.5. Оптимизация запросов Как уже отмечалось, запросы, являющиеся предписаниями по обработке данных, интерпретируются (или компилируются, т. е. переводятся) машиной данных СУБД в машинные коды и выполняются. При этом, однако, декларативный характер языка SQL («что сделать») приводит к неоднозначности в определении конкретной схемы и конкретного порядка обработки данных (наличию нескольких вариантов «как сделать»). Под оптимизацией запросов понимается такой способ обработки запросов, когда по начальному представлению запроса вырабатывается процедурный план его выполнения, наиболее оптимальный при существующих в базе данных управляющих структурах.* Оптимизация осуществляется в соответствии с критериями, заложенными в оптимизатор процессора запросов СУБД (см. рис. 2.1). * Кузнецов С.Д. Введение в СУБД. // СУБД. — № 4. — 1995. — С. 98.
В общей схеме обработки запроса выделяют: • лексический и синтаксический разбор запроса; • логическую оптимизацию; • семантическую оптимизацию; • построение процедурных планов выполнения запросов и выбор оптимального; • непосредственное выполнение запроса. Лексический и синтаксический разбор запроса формируют внутреннее представление запроса, содержащее вместо имен таблиц, полей и связей базы данных их истинные внутренние идентификаторы и указатели, находящиеся в системном каталоге базы данных. Логическая оптимизация запроса может включать различные эквивалентные преобразования, «улучшающие» представление запроса. Такие преобразования можно разбить на три группы: • преобразования предикатов сравнения; • преобразования порядка реляционных операций (соединения, объединения, выборки); • приведение запросов с подчиненными запросами к запросам на соединение (JOIN). Преобразования предикатов сравнения, улучшающие в целях оптимизации представление запроса, в свою очередь, разделяются на: • приведение предикатов сравнения к каноническому виду; • приведение логического условия сравнения к каноническому виду. Каноническим называется такой вид предикатов сравнения, который содержит сравнение простых выражений. Можно выделить три типа таких сравнений: • Имя поля Операция сравнения Константное арифметическое выражение; • Имя поля Операция сравнения Арифметическое выражение; • Арифметическое выражение Операция сравнения Константное арифметическое выражение. В первом типе под «Константным арифметическим выражением» понимается такое выражение, которое содержит константы и так называемые объемлющие переменные, в любой момент имеющие одинаковое значение в отношении всех
где МРОТ — объемлющая переменная, определяющая величину минимального размера оплаты труда. На этом примере легко понять суть последующей оптимизируемости канонических представлений. Правая часть такого сравнения одинакова для всех просматриваемых записей-кортежей и определяется (вычисляется) один раз для всех. В исходном выражении помимо собственно операции сравнения необходимо при выборке каждого кортежа производить арифметические вычисления, что существенно увеличивает количество операций при выполнении соответствующего запроса. Во втором типе под «Арифметическим выражением» понимается такое выражение, в котором может присутствовать имя поля другой таблицы, полностью раскрыты скобки, произведено приведение и упорядочение членов. Примером приведения предиката сравнения ко второму оптимизируемому каноническому виду является следующее выражение (сотрудники, оклад которых с учетом вычетов по болезни больше величины минимальной оплаты труда):
где КолДней — переменная, равная количеству рабочих дней в данном месяце. Примером приведения предиката сравнения к третьему оптимизируемому каноническому виду является следующее выражение (сотрудники, чей оклад после вычета подоходного налога с учетом льгот на иждивенцев в десять раз превышает величину минимальной оплаты труда):
где ИЖД — имя поля той же таблицы «Сотрудники», с данными по количеству иждивенцев для конкретного сотрудника; названия таблицы «Сотрудники» для краткости опущены. Приведение логических условий сравнения к каноническому виду преследует ту же цель снижения числа операций при выполнении запроса на основе поиска общих предикатов и различных упрощений логических выражений. Для примера можно привести следующее оптимизируемое логическое выражение (научные работы, которые вышли после защиты их авторами диссертаций, защищенными в 1995 г.):
Преобразования порядка реляционных операций также направлены на сокращение возможного количества операций при обработке запросов. Одними из наиболее частых реляционных операций в запросах являются операции соединения (JOIN) и операции ограничения (WHERE restriction). В этом отношении общим правилом оптимизирующего преобразования запросов будет замена последовательности операции соединения с последующими ограничениями на предварительные ограничения с последующим соединением:
где А и В — имена таблиц. Очевидно, что в большинстве случаев количество операций по реализации наиболее затратной операции соединения таблиц будет меньше после предварительно проведенных операций ограничения по отбору записей из исходных таблиц. Особенно данное правило актуально при наличии ограничений на отбор полей при соединении таблиц, связанных отношений «Один-ко-многим». В этом случае перенос ограничений в условиях отбора на таблицу, находящуюся на стороне «многие» до операции JOIN может существенно ускорить выполнение запроса. Одним из проявлений вариантности языка SQL является эквивалентность выражения некоторых подчиненных и сложных запросов с соединениями. При выполнении запросов с подчиненными запросами для каждого кортежа-записи в исходном наборе внешнего запроса выполняется подчиненный запрос. Иначе говоря, всякий раз при вычислении предиката внешнего запроса вычисляется подчиненный запрос. Поэтому резервом для оптимизации подобных запросов является поиск возможных путей сокращения количества операций за счет эквивалентных преобразований, приводящих к совмещению операций формирования набора кортежей-записей внешнего и внутреннего (подчиненного) запроса. Каноническим представлением запроса по данным из n таблиц называется запрос, содержащий n–1 предикат соединения и не содержащий предикатов с подчиненными запросами. Если вернуться к примеру подчиненного запроса с предикатом In на рис. 4.24, то его эквивалентным оптимизируемым выражением будет следующее:
Логическая оптимизация запросов не учитывает семантики конкретной базы данных, проявляемой в ограничениях целостности на значения полей таблиц и связей между ними. В результате ядро СУБД всякий раз при выполнении логически оптимизированного запроса еще и проверяет ограничения целостности. Часть записей-кортежей, сформированных по результатам операций запроса, при этом может быть отвергнута именно по ограничениям целостности. Семантическая оптимизация запросов основывается на слиянии внутреннего представления запроса и ограничений целостности конкретной базы данных до непосредственного выполнения запроса и призвана за счет совместной проверки ограничений целостности и условий запроса сократить количество выполняемых операций. Для примера предположим, что в таблице «Сотрудники» по полю «Оклад» наложено ограничение целостности, заключающееся в том, что оклад не может быть меньшим величины минимального размера оплаты труда МРОТ, равного 84 руб. Предположим также, что нужно сформировать список сотрудников, чей оклад меньше 50 руб. Соответствующий запрос имеет вид:
Без семантической оптимизации данный запрос будет выполняться следующим образом — будет последовательно извлекаться каждая запись в таблице «Сотрудники» и проверяться на выполнение условия отбора. Результатом выполнения запроса будет пустое множество записей. С учетом внутренней семантической оптимизации в ответ на запрос без последовательного перебора всех записей сразу будет выдано пустое множество записей. После логической и семантической оптимизации строится процедурный план выполнения запросов. Процедурным планом запроса называется детализированный порядок выполнения операций доступа к базе данных физического уровня. Уже упоминавшаяся многовариантность способов выполнения SQL-инструкций соответственно приводит к набору альтернативных процедурных планов выполнения запросов, среди которых оптимизатор запросов ядра СУБД должен выбрать оптимальный в соответствии с определенными критериями. Общепринятым критерием оптимальности процедурных планов является минимизация стоимости выполнения запросов. При этом под стоимостью выполнения запроса понимаются вычислительные ресурсы (ресурсы процессора и ресурсы дисковой и оперативной памяти), необходимые для выполнения запросов. Для иллюстрации вариантности процедурных планов рассмотрим запрос по выборке записей из таблицы «Сотрудники» по возрасту не старше 30 лет и с должностным окладом более 100руб.:
Если по полям «Дата_Рожд» и «Оклад» таблицы «Сотрудники» существуют индексы, то возможны три варианта плана выполнения запроса: 1) последовательно без учета индексации просматривать (сканировать) записи таблицы «Сотрудники» и отбирать записи при выполнении требуемых условий; 2) сканировать индекс поля «Дата_Рожд» с условием выборки «>=#01/01/68#», выбирать соответствующие записи из таблицы «Сотрудники» и среди них отбирать те, которые удовлетворяют условию по полю «Оклад»; 3) сканировать индекс поля «Оклад» с условием выборки «>100 руб.», выбирать соответствующие записи из таблицы «Сотрудники» и среди них отбирать те, которые удовлетворяют условию по полю «Дата_Рожд». Стоимость каждого варианта в конечном счете определяется главным образом количеством пересылаемых страниц (блоков) из файла данных в буферы оперативной памяти ввиду того, что, как уже отмечалось, время операций доступа к конкретным записям в оперативной памяти на несколько порядков меньше времени процессов обмена между внешней и оперативной памятью, и тем самым основные затраты приходятся именно на эту операцию. Если количество записей в таблице «Сотрудники» невелико и все они умещаются в одной странице (в одном блоке) файла базы данных, то наименее затратным будет первый вариант. Если записи таблицы «Сотрудники» распределены по множеству страниц, менее затратными являются 2-й и 3-й варианты. При этом различия между ними будут определяться так называемой селективностью значений по полям «Дата_Рожд» и «Оклад». Селективность определяется главным образом характером статистического распределения значений по соответствующим полям. Исходя из мощности (количества записей), вида (равномерное, нормальное) и параметров распределения (среднее значение, максимальное и минимальное значение) можно получить приблизительные оценки количества страниц (блоков) файла базы данных, пересылка которых потребуется в оперативную память в ходе выполнения запроса. Так, если по приведенному примеру имеются некоторые априорные или апостериорные данные о том, что распределение значений по возрасту сотрудников является нормальным со средним значением 27 лет, а распределение величин должностных окладов является равномерным в интервале от 50 руб. до 500 руб., то, очевидно, наименее затратным будет 2-й вариант процедурного плана выполнения запроса, так как потребует меньшего количества пересылок страниц файла базы данных. Стратегии оптимизатора по оценкам стоимости выполнения запросов могут быть упрощенными (когда статистические распределения любых полей являются по умолчанию равномерными) либо более сложными. В сложных стратегиях при ведении базы данных (добавление, удаление, изменение записей) осуществляется мониторинг за параметрами апостериорных статистических распределений значений по полям базы данных (отслеживается минимальное, максимальное, среднее значение и другие параметры). В этом случае оценки стоимости процедурных планов выполнения запросов являются более точными, и тем самым повышается эффективность оптимизации запросов и в целом эффективность обработки данных. 4.3.3. Процедуры, правила (триггеры) и события в базах данных Рассмотренные выше способы обработки данных через запросы, фильтрацию, поиск и сортировку данных реализуют достаточно простые информационные потребности пользователей АИС либо являются лишь отдельными элементами в последовательности взаимоувязанных операций при решении сложных информационных задач в предметной области АИС. План последовательности таких операций, отражающий определенный алгоритм реализации информационных задач, может быть достаточно сложным, и каждый раз при возникновении соответствующей информационной потребности должен создаваться (воспроизводиться) и реализовываться пользователем заново. К примеру, одной из задач АИС по делопроизводству могут быть функции организации, а также контроля за прохождением и отработкой входящих документов. Реализация этой функции может осуществляться по следующему алгоритму: • при появлении новых записей в таблице «документы» с категорией «входящие» сформировать набор записей входящих документов за определенный период времени, скажем за рабочий день; • известить пользователей АИС, имеющих полномочия на принятие резолюций по входящим документам (руководители организации или их секретариаты), и предоставить им доступ к сформированному набору данных; • получить результаты резолюций на входящих документах, известить и предоставить соответствующие документы пользователям-исполнителям, включить контроль на исполнение документов; • получить от пользователей-исполнителей данные по исполнению документа и снять соответствующие документы с контроля либо известить пользователей, наложивших соответствующие резолюции, о не исполнении к установленному сроку их резолюций. Реализация таких сложных алгоритмов обработки данных в ранних СУБД осуществлялась через создание и постоянное выполнение в АИС прикладных программ на языках высокого уровня (Фортран, Кобол, С), которые постоянно опрашивали базу данных на предмет обнаружения соответствующих ситуаций и реализовывали сложные алгоритмы обработки. Как и в случае с простыми запросами до появления языков баз данных, такой подход требует квалифицированных посредников-программистов между пользователем и базой данных и, кроме того, обусловливает значительные вычислительные затраты на функционирование АИС. Разработчиками известной СУБД SyBase был предложен другой оригинальный подход, который можно проиллюстрировать следующей схемой: Функционирование базы данных согласно приведенной схеме осуществляется следующим образом:
Рис. 4.26. Принцип механизма событий, правил и процедур в базах данных 1. В базе данных определяются так называемые события (database events), связанные с изменениями данных — добавление новой записи (ей) в определенную таблицу, изменение записи(ей), удаление записи (ей).* Для реализации механизма событий в языке SQL введены специальные конструкции (Create DBEvent «Имя» — создать событие, Exec SQL Get DBEvent — получить событие и т.д.); 2. Для каждого события в базе данных определяются правила (triggers) по проверке определенных условий состояния данных. Соответственно в SQL введены конструкции для описания правил (Create Rule «Имя» — создать правило); 3. В зависимости от результатов проверки правил в базе данных запускаются на выполнение предварительно определенные процедуры. Процедуры представляют собой последовательности команд по обработке данных, имеющие отдельное смысловое значение, и могут реализовываться на упрощенном макроязыке (последовательность команд запуска запросов или выполнения других действий, например по открытию-закрытию форм, таблиц и т. п.) или на языке 4GL, встроенном в СУБД. * Событиями могут быть также и производные от перечисленных событии, например, событие, заключающееся в том, что какая-либо транзакция (процесс, пользователь) намеревается изменить запись (но еще не изменила)—так называемое событие «До обновления». Аналогично, могут быть определены события «После обновления», «До удаления», «После удаления» и т. п.
В последнем случае процедуры представляют собой подпрограммы для осуществления сложных операций обработки и диалога с пользователем. В язык SQL также введены специальные конструкции описания процедур (Create Procedure «Имя» — создать процедуру). Суть идеи механизма событий, правил и процедур заключается в том, что они после определения хранятся(!!!)* вместе с данными. Соответствующие конструкции введены в стандарт SQL — SQL2. Ядро СУБД при любом изменении состояния базы данных проверяет, не произошли ли ранее «поставленные на учет» события, и, если они произошли, обеспечивает проверку соответствующих правил и запуск соответствующих процедур обработки. * То есть зарегистрировать для автоматической обработки в БД.
В отличие от традиционного подхода, когда специальные прикладные программы постоянно «опрашивают» базу данных для обнаружения ситуаций, требующих обработки, «событийная» техника более экономична и естественна в технологическом плане. Кроме того, SQL-инструкции, реализующие технику «событий-правил-процедур» в некоторых СУБД с развитым интерфейсом, могут быть созданы, так же как и сложные запросы, через специальные конструкторы и мастера, что дает возможность их освоения и использования пользователями-непрограммистами. В настоящее время механизм событий, правил и процедур широко распространен и в той или иной мере реализован практически в любой современной СУБД.
|