Гайдамакин Н. А. 12 страница
Технологически в реляционных СУБД техника представлений реализуется через введение в язык SQL-конструкций, позволяющих аналогично технике «событий-правил-процедур» создавать именованные запросы-представления: CREAТЕ VIEW ИмяПредставленият AS SELECT... FROM... ...; В данных конструкциях после имени представления и ключевого слова AS размещается запрос на выборку данных, собственно и формирующий соответствующее представление какого-либо объекта базы данных. Авторизация представлений осуществляется применением команд (директив) GRANT, присутствующих в базовом перечне инструкций языка SQL (см. п. 4.1) и предоставляющих полномочия и привилегии пользователям: GRANT SELECTON ИмяПредставления TO ИмяПользователя1, ИмяПользователя2,...; Соответственно директива REVOKE отменяет уставленные ранее привилегии. Несмотря на простоту и определенную изящность идеи «представлений», практическая реализация подобной технологии построения и функционирования распределенных систем встречает ряд серьезных проблем. Первая из них связана с размещением системного каталога базы данных, ибо при формировании для пользователя «представления» распределенной базы данных ядро СУБД в первую очередь должно «узнать», где и в каком виде в действительности находятся данные. Требование отсутствия центральной установки приводит к выводу о том, что системный каталог должен быть на любой локальной установке. Но тогда возникает проблема обновлений. Если какой-либо пользователь изменил данные или их структуру в системе, то эти изменения должны отразиться во всех копиях системного каталога. Однако размножение обновлений системного каталога может встретить трудности в виде недоступности (занятости) системных каталогов на других установках в момент распространения обновлений. В результате может быть не обеспечена непрерывность согласованного состояния данных, а также возникнуть ряд других проблем. Решение подобных проблем и практическая реализация распределенных информационных систем осуществляется через отступление от некоторых рассмотренных выше принципов создания и функционирования распределенных систем. В зависимости оттого, какой принцип приносится в «жертву» (отсутствие центральной установки, непрерывность функционирования, согласованного состояния данных и др.) выделились несколько самостоятельных направлений в технологиях распределенных систем — технологии «Клиент-сервер», технологии реплицирования, технологии объектного связывания. Реальные распределенные информационные системы, как правило, построены на основе сочетания всех трех технологий, но в методическом плане их целесообразно рассмотреть отдельно. Дополнительно следует также отметить, что техника представлений оказалась чрезвычайно плодотворной также и в другой сфере СУБД—защите данных. Авторизованный характер запросов, формирующих представления, позволяет предоставить конкретному пользователю те данные и в том виде, которые необходимы ему для его непосредственных задач, исключив возможность доступа, просмотра и изменения других данных. 5.2. Технологии и модели «Клиент-сервер» Системы на основе технологий «Клиент-сервер» исторически выросли из первых централизованных многопользовательских автоматизированных информационных систем, интенсивно развивавшихся в 70-х годах (системы main frame), и получили, вероятно, наиболее широкое распространение в сфере информационного обеспечения крупных предприятий и корпораций. В технологиях «Клиент-сервер» отступают от одного из главных принципов создания и функционирования распределенных систем — отсутствия центральной установки. Поэтому можно выделить две основные идеи, лежащие в основе клиент-серверных технологий: • общие для всех пользователей данные на одном или нескольких серверах; • много пользователей (клиентов) на различных вычислительных установках, совместно (параллельно и одновременно) обрабатывающих общие данные. Иначе говоря, системы, основанные на технологиях «Клиент-сервер», распределены только в отношении пользователей, поэтому часто их не относят к «настоящим» распределенным системам, а считают отдельным, уже упоминавшимся классом многопользовательских систем. Важное значение в технологиях «Клиент-сервер» имеют понятия сервера и клиента. Под сервером в широком смысле понимается любая система, процесс, компьютер, владеющие каким-либо вычислительным ресурсом (памятью, временем, производительностью процессора и т. д.). Клиентом называется также любая система, процесс, компьютер, пользователь, запрашивающие у сервера какой-либо ресурс, пользующиеся каким-либо ресурсом или обслуживаемые сервером иным способом. В своем развитии системы «Клиент-сервер» прошли несколько этапов, в ходе которых сформировались различные модели систем «Клиент-сервер». Их реализация и, следовательно, правильное понимание основаны на разделении структуры СУБД на три компонента: • компонент представления, реализующий функции ввода и отображения данных, называемый иногда еще просто как интерфейс пользователя (см. рис. 2.1); • прикладной компонент, включающий набор запросов, событий, правил, процедур и других вычислительных функций, реализующий предназначение автоматизированной информационной системы в конкретной предметной области; • компонент доступа к данным, реализующий функции хранения, извлечения, физического обновления и изменения данных (машина данных). Исходя из особенностей реализации и распределения (расположения) в системе этих трех компонентов различают четыре модели технологий «Клиент-сервер»:* • модель файлового сервера (File Server — FS); • модель удаленного доступа к данным (Remote Data Access—RDA); • модель сервера базы данных (DataBase Server — DBS); • модель сервера приложении (Application Server — AS). * Ладыженский Г.М. Системы управления базами данных — коротко о главном//СУБД.—№№1-4.—1995.
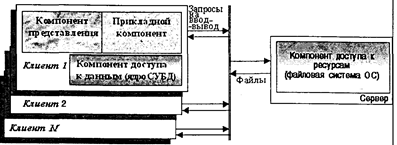
5.2.1. Модель файлового сервера Модель файлового сервера является наиболее простой и характеризует собственно не столько способ образования фактографической информационной системы, сколько общий способ взаимодействия компьютеров в локальной сети. Один из компьютеров сети выделяется и определяется файловым сервером, т. е. общим хранилищем любых данных. Суть FS-модели иллюстрируется схемой, приведенной на рис. 5.2.
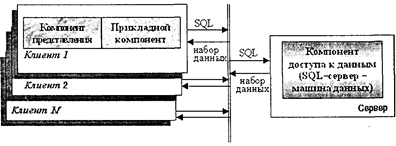
Рис. 5.2. Модель файлового сервера В FS-модели все основные компоненты размещаются на клиентской установке. При обращении к данным ядро СУБД, в свою очередь, обращается с запросами на ввод-вывод данных за сервисом к файловой системе. С помощью функций операционной системы в оперативную память клиентской установки полностью или частично на время сеанса работы копируется файл базы данных. Таким образом, сервер в данном случае выполняет чисто пассивную функцию. Достоинством данной модели являются ее простота, отсутствие высоких требований к производительности сервера (главное — требуемый объем дискового пространства). Следует также отметить, что программные компоненты СУБД в данном случае не распределены, т. е. никакая часть СУБД на сервере не инсталлируется и не размещается. С другой стороны также очевидны и недостатки такой модели. Это, прежде всего, высокий сетевой трафик, достигающий пиковых значений особенно в момент массового вхождения в систему пользователей, например в начале рабочего дня. Однако более существенным с точки зрения работы с общей базой данных является отсутствие специальных механизмов безопасности файла (файлов) базы данных со стороны СУБД. Иначе говоря, разделение данных между пользователями (параллельная работа с одним файлом данных) осуществляется только средствами файловой системы ОС для одновременной работы нескольких прикладных программ с одним файлом. Несмотря на очевидные недостатки, модель файлового сервера является естественным средством расширения возможностей персональных (настольных) СУБД в направлении поддержки многопользовательского режима и, очевидно, в этом плане еще будет сохранять свое значение. 5.2.2. Модель удаленного доступа к данным Модель удаленного доступа к данным основана на учете специфики размещения и физического манипулирования данных во внешней памяти для реляционных СУБД. В RDA-модели компонент доступа к данным в СУБД полностью отделен от двух других компонентов (компонента представления и прикладного компонента) и размещается на сервере системы. Компонент доступа к данным реализуется в виде самостоятельной программной части СУБД, называемой SQL-сервером, и инсталлируется на вычислительной установке сервера системы. Функции SQL-сервера ограничиваются низкоуровневыми операциями по организации, размещению, хранению и манипулированию данными в дисковой памяти сервера. Иначе говоря, SQL-сервер играет роль машины данных. Схема RDA-модели приведена на рис. 5.3.
Рис. 5.3. Модель удаленного доступа к данным (RDA -модель) В файле (файлах) базы данных, размещаемом на сервере системы, находится также и системный каталог базы данных, в который помещаются в том числе и сведения о зарегистрированных клиентах, их полномочиях и т. п. На клиентских установках инсталлируются отделенные программные части СУБД, реализующие интерфейсные и прикладные функции. Пользователь, входя в клиентскую часть системы, регистрируется через нее на сервере системы и начинает обработку данных. Прикладной компонент системы (библиотеки запросов, процедуры обработки данных) полностью размещается и выполняется на клиентской установке. При реализации своих функций прикладной компонент формирует необходимые SQL-инструкции, направляемые SQL-серверу. SQL-сервер, представляющий специальный программный компонент, ориентированный на интерпретацию SQL-инструкций и высокоскоростное выполнение низкоуровневых операций с данными, принимает и координирует SQL-инструкции от различных клиентов, выполняет их, проверяет и обеспечивает выполнение ограничений целостности данных и направляет клиентам результаты обработки SQL-инструкции, представляющие как известно наборы (таблицы) данных. Таким образом, общение клиента с сервером происходит через SQL-инструкции, а с сервера на клиентские установки передаются только результаты обработки, т. е. наборы данных, которые могут быть существенно меньше по объему всей базы данных. В результате резко уменьшается загрузка сети, а сервер приобретает активную центральную функцию. Кроме того, ядро СУБД в виде SQL-сервера обеспечивает также традиционные и важные функции по обеспечению ограничений целостности и безопасности данных при совместной работе нескольких пользователей. Другим, может быть неявным, достоинством RDA-модели является унификация интерфейса взаимодействия прикладных компонентов информационных систем с общими данными. Такое взаимодействие стандартизовано в рамках языка SQL уже упоминавшимся специальным протоколом ODBC* (Open Database Connectivity), играющим важную роль в обеспечении интероперабельности, т. е. независимости от типа СУБД на клиентских установках в распределенных системах. Иначе говоря, специальный компонент ядра СУБД на сервере (так называемый драйвер ODBC) способен воспринимать, обрабатывать запросы и направлять результаты их обработки на клиентские установки, функционирующие под управлением реляционных СУБД других, не «родных» типов. Такая возможность существенно повышает гибкость в создании распределенных информационных систем на базе интеграции уже существующих в какой-либо организации локальных баз данных под управлением настольных или другого типа реляционных СУБД. Специальные драйверы ODBC могут обеспечить возможность использования настольной СУБД в качестве клиента SQL-сервера «тяжелой» многопользовательской клиент-серверной СУБД. * Стандартный протокол доступа к данным на серверах баз данных SQL.
К недостаткам RDA-модели можно отнести высокие требования к клиентским вычислительным установкам, так как прикладные программы обработки данных, определяемые спецификой предметной области АИС, выполняются на них. Другим недостатком является все же существенный трафик сети, обусловленный тем, что с сервера базы данных клиентам направляются наборы (таблицы) данных, которые в определенных случаях могут занимать достаточно существенный объем. 5.2.3. Модель сервера базы данных Развитием RDA-модели стала модель сервера базы данных. Ее сердцевиной является рассмотренный ранее механизм хранимых процедур. В отличие от RDA-модели, определенные для конкретной предметной области АИС события, правила и процедуры, описанные средствами языка SQL, хранятся вместе с данными на сервере системы и на нем же выполняются. Иначе говоря, прикладной компонент полностью размещается и выполняется на сервере системы. Схематично DBS-модель приведена на рис. 5.4.
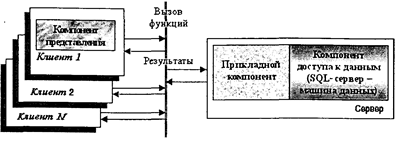
Рис. 5.4. Модель сервера базы данных (DBS-модель) На клиентских установках в DBS-модели размещается только интерфейсный компонент (компонент представления) АИС, что существенно снижает требования к вычислительной установке клиента. Пользователь через интерфейс системы на клиентской установке направляет на сервер базы данных только лишь вызовы необходимых процедур, запросов и других функций по обработке данных. Все затратные операции по доступу и обработке данных выполняются на сервере и клиенту направляются лишь результаты обработки, а не наборы данных, как в RDA-модели. Этим обеспечивается существенное снижение трафика сети в DBS-модели по сравнению с RDA-моделью. Следует, однако, заметить, что на сервере системы выполняются процедуры прикладных задач одновременно всех пользователей системы. В результате резко возрастают требования к вычислительной установке сервера, причем как к объему дискового пространства и оперативной памяти, так и к быстродействию. Это основной недостаток DBS-модели. К достоинствам же DBS-модели, помимо разгрузки сети, относится и более активная роль сервера сети, размещение, хранение и выполнение на нем механизма событий, правил и процедур, возможность более адекватно и эффективно «настраивать» распределенную АИС на все нюансы предметной области системы. Также более надежно обеспечивается согласованность состояния и изменения данных, и, вследствие этого, повышается надежность хранения и обработки данных, эффективно координируется коллективная работа пользователей с общими данными. 5.2.4. Модель сервера приложений Чтобы разнести требования к вычислительным ресурсам сервера в отношении быстродействия и памяти по разным вычислительным установкам, используется модель сервера приложений. Суть AS-модели заключается в переносе прикладного компонента АИС на специализированный в отношении повышенных ресурсов по быстродействию дополнительный сервер системы. Схема AS-модели приведена на рис. 5.5.
Рис. 5.5. Модель сервера приложений (AS-модель) Как и в DBS-модели, на клиентских установках располагается только интерфейсная часть системы, т.е. компонент представления. Однако вызовы функций обработки данных направляются на сервер приложений, где эти функции совместно выполняются для всех пользователей системы. За выполнением низкоуровневых операций по доступу и изменению данных сервер приложений, как в RDA-модели, обращается к SQL-серверу, направляя ему вызовы SQL-процедур, и получая, соответственно, от него наборы данных. Как известно, последовательная совокупность операций над данными (SQL-инструкций), имеющая отдельное смысловое значение, называется транзакцией. В этом отношении сервер приложений от клиентов системы управляет формированием транзакций, которые выполняет SQL-сервер. Поэтому программный компонент СУБД, инсталлируемый на сервере приложений, еще называют также монитором обработки транзакций (Transaction Processing Monitors — TRM), или просто монитором транзакций. AS-модель, сохраняя сильные стороны DBS-модели, позволяет более оптимально построить вычислительную схему информационной системы, однако, как и в случае RDA-модели, повышает трафик сети. В еще не устоявшейся до конца терминологии по моделям и технологиям «Клиент-сервер» RDA-модель характеризуют еще как модель с так называемыми «толстыми», а DBS-модель и AS-модель как модели, соответственно, с «тонкими» клиентами. По критерию звеньев системы RDA-модель и DBS-модель называют двухзвенными (двухуровневыми) системами, a AS-модель трехзвенной (трехуровневой) системой. В практических случаях используются смешанные модели, когда простейшие прикладные функции и обеспечение ограничений целостности данных поддерживаются хранимыми на сервере процедурами (DBS-модель), а более сложные функции предметной области (так называемые «правила бизнеса») реализуются прикладными программами на клиентских установках (RDA-модель) или на сервере приложений (AS-модель). 5.2.5. Мониторы транзакций Сердцевиной и основой эффективности функционирования многопользовательских систем «Клиент-сервер» является эффективное управление транзакциями. Собственно само понятие транзакции возникло именно в процессе исследования принципов построения и функционирования централизованных многопользовательских реляционных СУБД. Транзакции играют важную роль в механизме обеспечения СУБД ограничений целостности базы данных. Ограничения целостности непосредственно проверяются по завершению очередной транзакции. Если условия ограничений целостности данных не выполняются, то происходит «откат» транзакции (выполняется SQL-инструкция ROLLBAСК), в противном случае транзакция фиксируется (выполняется SQL-инструкция COMMIT). Помимо обеспечения целостности данных механизм транзакций оказался чрезвычайно полезным для практической реализации одного из основополагающих принципов распределенных многопользовательских систем — изолированности пользователей. Как уже отмечалось, единичные действия пользователей с базой данных ассоциированы с транзакциями. В том случае, когда от разных пользователей поступают транзакции, время выполнения которых перекрывается, монитор транзакций обеспечивает специальную технологию их взаимного выполнения и изоляции с тем, чтобы избежать нарушений согласованного состояния данных и других издержек совместной обработки. К числу подобных издержек относятся: • потерянные изменения; • «грязные» данные; • неповторяющиеся чтения. Потерянные изменения возникают тогда, когда две транзакции одновременно изменяют один и тот же объект базы данных. В том случае, если в силу каких-либо причин, например, из-за нарушений целостности данных, происходит откат, скажем, второй транзакции, то вместе с этим отменяются и все изменения, внесенные в соответствующий период времени первой транзакцией. В результате первая еще не завершившаяся транзакция при повторном чтении объекта не «видит» своих ранее сделанных изменений данных. Очевидным способом преодоления подобных ситуаций является запрет изменения данных любой другой транзакцией до момента завершения первой транзакции—так называемая блокировка объекта. «Грязные» данные возникают тогда, когда одна транзакция изменяет какой-либо объект данных, а другая транзакция в этот момент читает данные из того же объекта. Так как первая транзакция еще не завершена, и, следовательно, не проверена согласованность данных после проведенных, или вовсе еще только частично проведенных изменений, то вторая транзакция может «видеть» соответственно несогласованные, т. е. «грязные» данные. Опять-таки способом недопущения таких ситуаций может быть запрет чтения объекта любой другой транзакцией, пока не завершена первая транзакция, его изменяющая. Неповторяющиеся чтения возникают тогда, когда одна транзакция читает какой-либо объект базы данных, а другая до завершения первой его изменяет и успешно фиксируется. Если при этом первой, еще не завершенной, транзакции требуется повторно прочитать данный объект, то она «видит» его в другом состоянии, т. е. чтение не повторяется. Способом недопущения подобных ситуаций в противоположность предыдущему случаю является запрет изменения объекта любой другой транзакцией, когда первая транзакция на чтение еще не завершена. Механизм изоляции транзакций и преодоления ситуаций несогласованной обработки данных в общем виде основывается на технике сериализации транзакций. План (способ) выполнения совокупности транзакций называется сериальным, если результат совместного выполнения транзакций эквивалентен результату некоторого последовательного их выполнения. Сериализацией транзакций в этом смысле является организация их выполнения по некоторому сериальному плану. Существуют два различных подхода сериализации транзакций: • синхронизационные захваты (блокировки) объектов базы данных; • временные метки объектов базы данных. В первом подходе определяется два основных режима захватов — совместный режим (Shared) и монопольный режим (exclusive). При совместном режиме осуществляется разделяемый захват, требующий только операций чтения. Поэтому такой захват еще называют захватом по чтению. При монопольном режиме осуществляется неразделяемый захват, требующий операций обновления данных. Такой захват, соответственно, еще называют захватом по записи. Наиболее распространенным вариантом первого подхода является реализация двухфазного протокола синхронизационных захватов (блокировок) объектов базы данных — 2PL (Two-Phase Locks). В соответствии с данным протоколом выполнение транзакции происходит в два этапа. На первом этапе (первая фаза) перед выполнением любой операции транзакция запрашивает и накапливает захваты необходимых объектов в соответствующем режиме. После получения и накопления необходимых захватов (блокировок) осуществляется вторая фаза — фиксация изменений (или откат по соображениям целостности данных) и освобождение захватов. При построении сериальных планов допускается совмещение только захватов по чтению. В остальных случаях транзакции должны «ждать», когда необходимые объекты разблокируются (освободятся). Более изощрённые стратегии сериализации транзакций основываются на «гранулировании» объектов захвата (файл базы данных, отдельная таблица, страница файла данных, отдельная запись-кортеж). Соответственно при этом расширяется номенклатура синхронизационных режимов захватов, например в совместном режиме (по чтению) может быть захвачен и в целом файл и отдельные его страницы, или в другом случае обеспечивается совместный режим захвата файла с возможностью монопольного захвата отдельных его объектов — таблиц, страниц или записей-кортежей). Грануляция синхронизационных блокировок позволяет строить более эффективные планы сериализации транзакций. Существенным недостатком синхронизационных захватов является возможность возникновения тупиковых ситуаций (Deadlock). Предположим, одна транзакция на первой фазе установила монопольный захват одного объекта, а другая транзакция монопольный захват второго объекта. Для осуществления полного набора своих операций первой транзакции еще требуется совместный захват второго объекта, а второй транзакции, соответственно, совместный захват первого объекта. Ни одна из транзакций не может закончить первую фазу, т. е. полностью накопить все необходимые захваты, так как требуемые объекты уже монопольно захвачены, хотя были свободны к моменту начала осуществления транзакций. Непростой проблемой является автоматическое обнаружение (распознавание) таких тупиковых ситуации и их разрешение (разрушение). Распознавание тупиков основывается на построении и анализе графа ожидания транзакций, состоящего из вершин-транзакций и вершин-объектов захвата. Исходящие из вершин-транзакций дуги к вершинам-объектам соответствуют требуемым захватам, а дуги, исходящие из вершин-объектов к вершинам-транзакциям соответствуют полученным захватам. При тупиковых ситуациях в графе ожидания транзакций наблюдаются петли (циклы), обнаружение которых обеспечивается специальным алгоритмизируемым механизмом редукции графа, подробное изложение которого можно найти в специальной литературе по теории графов. Отметим только, что применение подобного механизма распознавания тупиков требует построения и постоянного поддержания (обновления) графа ожидания транзакций, что увеличивает накладные расходы при выполнении транзакции и снижает производительность обработки данных. Еще одной проблемой является технология, или, лучше сказать, алгоритм разрушения тупиков. В общем плане такие алгоритмы основываются на выборе транзакции-жертвы, которая временно откатывается для предоставления возможности завершения выполнения операций другим транзакциям, что, конечно же, в определенной степени нарушает принцип изолированности пользователей. В качестве «жертвы» выбирается или самая «дешевая» транзакция в смысле затрат на выполнение, или транзакция с наименьшим приоритетом. Более простой альтернативой технике синхронизационных захватов является техника временных меток. Суть этого метода заключается в том, что каждой транзакции приписывается временная метка, соответствующая моменту начала выполнения транзакции. При выполнении операции над объектом транзакция «помечает» его своей меткой и типом операции (чтение или изменение). Если при этом другой транзакции требуется операция над уже «помеченным» объектом, то выполняются действия по следующему алгоритму: • проверяется, не закончилась ли транзакция, первой «пометившая» объект; • если первая транзакция закончилась, то вторая транзакция помечает его своей меткой и выполняет необходимые операции; • если первая транзакция не закончилась, то проверяется конфликтность операций (напомним, что конфликтно любое сочетание, кроме «чтение-чтение»); • если операции неконфликтны, то они выполняются для обеих транзакций, а объект до завершения операций помечается меткой более поздней, т. е. более молодой транзакции; • если операции конфликтны, то далее происходит откат более поздней транзакции и выполняется операция более ранней (старшей) транзакции, а после ее завершения объект помечается меткой более молодой транзакции и цикл действий повторяется. В результате того что при таком алгоритме конфликтность транзакций определяется более грубо, чем при синхронизационных блокировках, реализация метода временных меток вызывает более частые откаты транзакций. Несомненным же достоинством метода временных меток является отсутствие тупиков, и, следовательно, отсутствие накладных расходов на их распознавание и разрушение. СУБД идеологии «Клиент-сервер», называемые иногда в противовес однопользовательским («настольным») «тяжелыми» системами (Oracle, SyBase, Informix, Ingres и др.), составляют одно из наиболее интенсивно развивающихся направлений централизованных многопользовательских систем, охватывая своим управлением сотни тысяч гигабайтов фактографических данных, и в этом отношении еще долгое время будут играть роль фактического стандарта корпоративных информационных систем. 5.3. Технологии объектного связывания данных Унификация взаимодействия прикладных компонентов с ядром информационных систем в виде SQL-серверов, наработанная для клиент-серверных систем, позволила выработать аналогичные решения и для интеграции разрозненных локальных баз данных под управлением настольных СУБД в сложные децентрализованные гетерогенные распределенные системы. Такой подход получил название объектного связывания данных. С узкой точки зрения, технология объектного связывания данных решает задачу обеспечения доступа из одной локальной базы, открытой одним пользователем, к данным в другой локальной базе* (в другом файле), возможно находящейся на другой вычислительной установке, открытой и эксплуатируемой другим пользователем.
|