Гайдамакин Н. А. 15 страница
Идеи координации понятий, т. е. использования операций над классами, активно развивались в 40-с—50-с гг. в первых механизированных системах организации поиска документов (уже упоминавшиеся карты У. Баттена на основе оптического совпадения, система «Зато-кодирования» К. Муэрса и система унитермов М. Тауба). При этом определилось два направления координации понятий — предкоординация и посткоординация (см. рис. 6.3). Предкоординация понятий предусматривает использование операций над классами при индексировании документов.Иначе говоря, индекс документа представляет собой конструкцию из исходных понятии (классов) классификатора, построенную на основе логических операций. В системах на основе посткоординации понятий логические операции над классами осуществляются при поиске документов, т. е. в процессе формирования поискового образа запроса. Технология и механизм поиска при этом включают предварительный отбор всех документов с индексами классов (рубрик), входящих в логическую конструкцию запроса, с последующим осуществлением собственно логических операций над отобранными совокупностями (множествами) документов. 6.2.3. Информационно-поисковые тезаурусы Особую роль в развитии информационно-поисковых систем сыграли работы Мортимера Тауба, разработавшего в 1951 году систему унитермов. В системе Тауба содержание документа индексируется совокупностью терминов в виде однословных обозначений — унитермов. Например, документ по теории информационного поиска может быть проиндексирован двумя унитермами — «Информационный», «Поиск». В качестве унитермов чаще всего выступают элементы словаря ключевых терминов по определенной предметной области. В системе Тауба первоначально не предполагалось какой-либо связи или отношений между унитермами и, следовательно, ее можно отнести к чисто дескрипторным системам. Вместе с тем сразу же проявились и такие специфические проблемы дескрипторных систем, как ложная координация понятий. Явление ложной координации заключается в такой координации понятий (классов, терминов), которые хотя по отдельности и присутствуют в содержании документа, но комбинируются по смыслу с другими понятиями (терминами, классами). Так, например, в содержании документа, в котором речь идет об информационном обеспечении поисковых бригад при ликвидации чрезвычайных происшествий и последствий стихийных бедствий, также присутствуют в числе прочих унитермы — «Информационный» и «Поиск», и, следовательно, он совершенно неправильно может быть выдан на запрос по теории информационного поиска. Другой проблемой в системах на основе унитермов являются синонимичность и омонимичность * некоторых терминов, что приводит к неоднозначности индексирования документов. Для преодоления ложной координации и других проблем стали вводить составные термины, указатели связи и ролей терминов («род— вид», «средство действия» и т. п.), заново открывая в некотором смысле предметную иерархическую рубрикацию со связями, и внося тем самым в чисто дескрипторную систему элементы семантики. Так появилось отдельное направление информационно-поисковых систем, получившее название тезаурусов. * Синонимы — одинаковые или близкие по смыслу слова, омонимы — слова, одинаковые в написании и звучании, но имеющие разный смысл — ключ (в замке), ключ (источник воды).
Тезаурус (с греч. «хранилище», «запас», «сокровищница») в узком смысле представляет собой специальный словарь-справочник, в котором перечислены ключевые слова-дескрипторы определенной предметной области, указаны синонимичные им ключевые слова, установлены способы устранения cинонимии, омонимии, полисемии, определены родо-видовые и ассоциативные связи дескрипторов.* * Строгое определение информационно-поискового тезауруса (нормативный словарь дескрипторного ИПЯ с зафиксированными в нем парадигматическими отношениями лексических единиц) приведено в ГОСТ 7.74-96 СИБИД. Информационно-поисковые языки.—М.: Изд-во стандартов, 1997.
В более общем плане в тезаурусе выделяют классификационную схему и алфавитный перечень дескрипторов-ключевых слов. Классификационная схема определяет систематизацию дескрипторов по уровням иерархии исходя из «родо-видовых» или ролевых отношений. Алфавитный перечень содержит словарный фонд дескрипторов для индексирования документов. Внешним отличием информационно-поисковых тезаурусов от информационно-поисковых каталогов на основе предметной иерархической рубрикации со связями и ролевыми отношениями является то, что в тезаурусах помимо классификационной схемы присутствуют сами ключевые слова и дескрипторы, объединяемые под названием классов, рубрик и т. д. В каталогах же присутствуют только лишь обозначения (названия) классов, понятий и т. д., но не определены и нет самих ключевых терминов, им соответствующих. Главная идея информационно-поисковых тезаурусов заключается в повышении эффективности и автоматизации индексирования документов в рамках дескрипторного подхода. Иначе говоря, в системах на основе информационно-поисковых тезаурусов ПОД представлен набором дескрипторов (ключевых терминов). Однако в процессе индексирования документов учитываются семантические (родо-видовые, ролевые, синонимичные, омонимичные, полисемичные и ассоциативные) отношения между дескрипторами, что, в конечном счете, обеспечивает более адекватный содержанию ПОД и повышает эффективность поиска документов (по точности, полноте и шуму). Разработка тезаурусов и их внедрение в информационно-поисковые системы интенсивно осуществлялись в 60-е и 70-е годы. При этом в соответствии с тематическим профилем выделились многоотраслевые, отраслевые и узкотематические тезаурусы. Первым многоотраслевым тезаурусом за рубежом явился «Тезаурус технических и научных терминов», вышедший в декабре 1967 г. в США. В 1972 г. под редакцией Ю. И. Шемакина был разработан первый отечественный многоотраслевой «Тезаурус научно-технических терминов». В семидесятые годы тезаурусы были разработаны практически для всех отраслей деятельности, а также создано большое количество узкотематических специализированных тезаурусов. На основе практики разработки и использования информационно-поисковых тезаурусов были также разработаны специальные представления тезаурусов, закрепленные в нашей стране в соответствующих ГОСТах.* Согласно ГОСТ 18383-73 форма представления тезауруса включает алфавитное перечисление статей по каждому дескриптору (термину) в следующем виде:** ... РЕФЕРАТ с резюме в СВЕРТЫВАНИЕИНФОРМАЦИИ н РЕФЕРАТАВТОРСКИЙ РЕФЕРАТГРАФИЧЕСКИЙ РЕФЕРАТИНФОРМАТИВНЬШ РЕФЕРАТ«ТЕЛЕГРАФНОГОСТИЛЯ» РЕФЕРАТУКАЗАТЕЛЬНЫЙ РЕФЕРИРОВАНИЕ а АННОТАЦИЯ ... где в качестве буквенных обозначений выступают следующие: с — термины-синонимы; в — термины, подчиняющие заглавный термин, т.е. выше по иерархии; н — термины, подчиненные заглавному, т. е. ниже по иерархии; а — термины, ассоциированные с заглавным термином. * ГОСТ 18383-73. Тезаурус информационно-поисковый. Общие положения. Форма представления. ** Пример позаимствован из работы: Соколов А.В. Информационно-поисковые системы: Учеб. пособие для вузов/Под ред. А. Б. Рябова.—М.: Радио и связь, 1981.
Еще одной особенностью тезаурусов является применяемая на практике возможность расширения словарной базы новыми ключевыми терминами, появляющимися при накоплении документов в ходе эксплуатации системы. В этом плане различают базовые и рабочие тезаурусы. Базовые тезаурусы выступают в качестве нормативных пособий по лексике в той или иной отрасли знаний или предметной области. Рабочие тезаурусы в стартовом виде строятся на основе базовых тезаурусов и дополняются в процессе индексирования и анализа появления в документах новых или специфичных терминов (так называемые профессионализмы, иногда жаргонные термины и т. д.). В результате возникает еще один специфический компонент эксплуатации соответствующих ИПС, называемый ведением тезауруса. 6.2.4. Автоматизация индексирования документов Важным в практическом плане аспектом информационно-поисковых систем являются технологии, принципы и механизмы индексирования документов применительно к той или иной классификационной схеме. Развитие теории информационного поиска документов, создание первых механизированных информационно-поисковых систем поначалу не предполагали какой-либо автоматизации (механизации) индексирования документов. Индексирование осуществлялось специально подготовленными специалистами-экспертами в предметной области ИПС, которые могли осуществлять многоаспектный и глубокий анализ смыслового содержания документа и относить его (индексировать) к тем или иным классам, рубрикам, ключевым терминам. Такой подход обусловливал высокие накладные расходы на создание и ведение документальных информационно-поисковых систем, так как требовал наличия в организационном штате высококвалифицированных специалистов-индексаторов. Кроме того, в процесс индексирования при этом вносился человеческий фактор (субъективность поисковых образов одного документа, проиндексированного разными специалистами и т. п.). Поэтому в теории информационного поиска в 50-х-60-х годах выделилось отдельное направление исследований, связанное с вопросами автоматизации индексирования документов. Идеи и начало этих исследований были инициированы появлением уже упоминавшейся системы унитермов Тауба. Индексирование документов набором однословных дескрипторов-терминов (унитермов), имеющихся в тексте документа, позволило снизить профессиональные требования к индексаторам и, фигурально выражаясь, механистицировать* процесс индексирования. * Иначе в некотором смысле приблизить к чисто механической работе по выявлению в тексте унитермов.
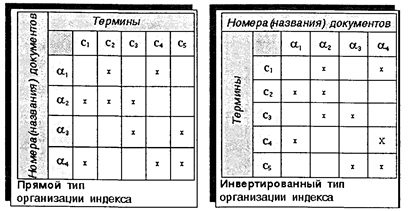
С применением и все более широким использованием вычислительной техники в информационно-поисковых документальных системах эти подходы трансформировались в задачи и технологии автоматического, т.е. без участия специалистов, индексирования документов. Огромную роль в исследовании и последующем развитии теории информационного поиска документов сыграли результаты Кренфилдского (I и II) проекта, проводившегося в конце 50-х — начале 60-х годов Английской ассоциацией специальных библиотек и информационных бюро. В ходе экспериментальных исследований эффективности нескольких различных по типу информационно-поисковых систем (система на основе УДК, фасетная система, система унитермов и некоторые их разновидности), проведенных в ходе реализации Кренфилдского проекта, выявились факторы противоречивого влияния некоторых семантических показателей классификационных ИПС (глубина уровней классов при индексировании, объем словарной базы и др.) на полноту и точность информационного поиска. Выявилась общая принципиальная закономерность—при повышении полноты поиска на основе использования тех или иных семантических методов при индексировании происходит снижение точности поиска и наоборот. Еще одним «неожиданным» результатом явилось небольшое отличие в показателях эффективности поиска документов в системах с развитой семантикой индексирования и в системах на основе неконтролируемой лексики. Последний результат активизировал в дальнейшем внимание к более простым и менее дорогим дескрипторным системам с неконтролируемой или слабоконтролируемой лексикой (унитермы, полнотекстовые системы), в которых на основе посткоординации при обработке запросов удается достичь вполне приемлемых показателей полноты и точности поиска. Этими же обстоятельствами был обусловлен импульс исследованиям технологий автоматического индексирования и уже на новом уровне возродилась идея полной механизации (точнее, уже автоматизации) индексирования документов. Сформировалось два, хотя и близких, но различных по содержанию подхода автоматическому индексированию. Первый подход основан на использовании словаря ключевых слов (терминов) и применяется в системах на основе информационно-поисковых тезаурусов. Индексирование в таких системах осуществляется путем последовательного автоматического поиска в тексте документа каждого ключевого термина. На этой основе строится и поддерживается индекс системы, собственно и реализующий поисковое пространство документов. Применяется два типа образования индекса — прямой и инвертированный (см. рис. 6.8).
Рис. 6.8. Прямой и инвертированный типы организации индекса Прямой тип индекса строится по схеме «Документ-термины». Поисковое пространство в этом случае представлено в виде матрицы размерностью NxM (N — количество документов, М —количество ключевых терминов). Строки этой матрицы представляют поисковые образы документов. Инвертированный тип индекса строится по обратной схеме— «Термин —документы». Поисковое пространство соответственно представлено аналогичной матрицей только в транспонированной форме. Поисковыми образами документов в этом случае являются столбцы матрицы. На основе автоматического индексирования документов по ключевым терминам могут решаться также и задачи автоматической классификации документов, т. е. автоматического отнесения документов к тем или иным классификационным рубрикам. Такие задачи особенно актуализировались в связи с интенсивным развитием в 90-х годах глобальных информационных сетей, появлением «электронной» периодики, книг и огромных массивов прочей неструктурированной текстовой информации в компьютерной форме. Автоматическое распознавание в больших объемах текстовой информации документов по определенной тематике позволяет существенно снизить затраты на предварительный отбор информации из внешних источников для пополнения базы документов ИПС по соответствующей предметной области. Принцип решения таких задач аналогичен решению задач информационного оповещения (см. рис. 6.2). Для конкретного класса документов (рубрики) строится поисковый образ, который в системах на основе индексирования по ключевым терминам может быть представлен набором определенных терминов или их сочетаний. Поисковые образы документов из внешних источников сравниваются по определенному критерию с поисковым образом py6pики, и на этой основе принимается решение о внесении документов в базу, т. е. об отнесении содержания документа к предметной области ИПС. Второй подход к автоматическому индексированию применяется в полнотекстовых системах. В процессе индексирования «на учет», т. е. в индекс заносится информация обо всех словах текста документа (отсюда, как уже отмечалось, и название «полнотекстовые»). Более подробно особенности полнотекстового индексирования рассматриваются в следующем параграфе. 6.3. Полнотекстовые информационно-поисковые системы Процессы массовой компьютеризации и информатизации деятельности предприятий, организаций в конце 80-х и в 90-х годах привели к накоплению огромных массивов неструктурированной текстовой компьютерной информации, с одной стороны, и доступности (всеобщей распространенности и персо-нальности) вычислительной техники, с другой стороны. Возникла потребность в программном инструментарии, который бы обеспечивал эффективный поиск нужных текстовых данных. Семантические подходы к автоматизации такого рода задач (информационно-поисковые каталоги, фасетные и тезаурусные системы) не могли быть в полной мере использованы в массовой персональной автоматизации, т. е. на рабочем месте отдельного пользователя или для небольшой рабочей группы, так как требовали серьезной предварительной проработки соответствующей предметной области.* Потребовались средства, которые бы в максимальной степени освобождали пользователя от необходимости сложной предварительной структуризации предметной области и затратных процедур индексирования при накоплении, получении и агрегировании текстовых данных, но в то же время создавали бы эффективный и интуитивно понятный поисковый инструментарий необходимых документов. * В этом отношении примечательным является следующее замечание — файловые системы ОС ПК предусматривают создание произвольной схемы логических дисков, каталогов, подкаталогов и т.п., которые по логике должны отображать структуру предметной области сведений пользователя ПК и, тем самым, в упрощенном утрированном виде решать задачи систематизации размещения документов-файлов для быстрого и эффективного их нахождения. Однако в большинстве случаев пользователями такая адекватная их потребностям система каталогов не создается из-за недостаточной их квалификации или нетривиальности самой структуры предметной области и данные зачастую размещаются довольно хаотично.
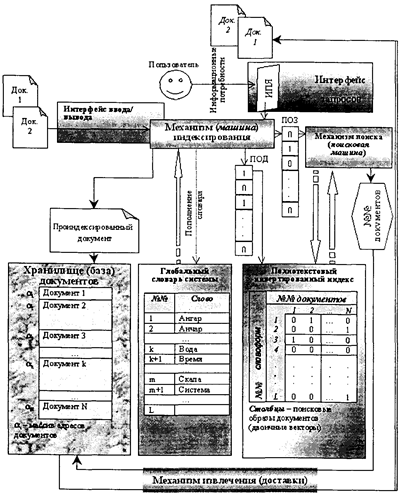
В результате на рынке программных продуктов в конце 80-х годов появились полнотекстовые ИПС и программные средства их создания, называемые иногда полнотекстовыми СУБД. 6.3.1. Информационно-технологическая структура полнотекстовых ИПС Полнотекстовые ИПС строятся на основе информационно-поисковых языков дескрипторного типа. Их информационно-технологическая структура представлена на рис. 6.9 и включает следующие элементы: • хранилище (базу) документов; • глобальный словарь системы; • индекс документов инвертированного типа; • интерфейс ввода (постановки на учет) документов в систему; • механизм (машину) индексирования; • интерфейс запросов пользователя; • механизм поиска документов (поисковую машину); • механизм извлечения (доставки) найденных документов. Хранилище документов может быть организовано как единая локально сосредоточенная информационная структура в виде специального файла (файлов) с текстами документов. Организация такого файла предусматривает указательную конструкцию на основе массива адресов размещения документов. Для компактного хранения документов они могут быть сжаты архиваторами. Другой вариант не предусматривает создания локально сосредоточенного хранилища документов, а ограничивается лишь массивом адресов расположения документов в соответствующей компьютерной информационной инфраструктуре (структура дисков и каталогов отдельного компьютера или локальной информационной сети, информационная инфраструктура глобальной информационной сети). Файлы текстовых документов распределены и размещаются в тех узлах и элементах информационной инфраструктуры, которые соответствуют технологии создания и обработки документов (документообороту). Вместе с тем все они учтены в полнотекстовой ИПС (т.е. проиндексированы по содержанию и зафиксированы по месторасположению) для эффективного поиска и доступа к ним. Такой подход более логичен с точки зрения технологий документооборота или распределенного характера систем (например, система WWW сети Интернет), но недостатком имеет необходимость постоянного отслеживания и учета возможных перемещений документов.
Рис. 6.9. Информационно-технологическая структура полнотекстовых ИПС Одним из наиболее характерных элементов полнотекстовых ИПС является глобальный словарь системы. Глобальные словари могут быть статическими и динамическими. Статические словари не зависят от содержания документов, вошедших в хранилище, а определены изначально в системе. В качестве таких статических словарей в том или ином виде, как правило, выступают словари основных словоформ соответствующего языка (русского, английского, немецкого и т. д.). Динамические словари определяются набором словоформ, имеющихся в накапливаемых в хранилище документах. Изначально такой словарь пуст, но с каждым новым документом в него помещаются новые словоформы, которых еще не было в ранее накопленных документах. Такой подход более экономичен и обеспечивает некоторую настройку словарной базы на предметную область документов. Элементы глобального словаря выступают в качестве дескрипторов ИПЯ системы. Поступающие через интерфейс ввода/вывода документы подвергаются операции индексирования по глобальному словарю. Механизм индексирования в полнотекстовых МПС полностью автоматизируется и заключается в создании специального двоичного вектора, компоненты которого показывают наличие или отсутствие в данном документе слова с соответствующим номером (позицией) из глобального словаря. В результате на «учет» в системе ставятся все слова текста документа, откуда, повторимся, происходит и название — «полнотекстовые ИПС». Важной особенностью, оказывающей существенное влияние на эффективность полнотекстовых ИПС, является наличие либо отсутствие морфологического разбора при индексировании документов и запросов. Морфологический разбор позволяет распознавать как одну общую словоформу все однокоренные слова (вода, водный, водяной), а также лексемы, т. е. одни и те же слова, отличающиеся в тексте различными окончаниями, приставками и суффиксами (водный, водного, водному, воду, воде и т. п.). Такой процесс основывается на нормализации глобального словаря системы, объединяющей в одну словоформу (в одну позицию) все однокоренные слова и лексемы. Кроме того, при морфологическом разборе отбрасываются так называемые неинформативные слова (стоп-слова) — предлоги, союзы, восклицания, междометия и некоторые другие грамматические категории. В большинстве случаев морфологический разбор осуществляется в системах со статическим глобальным словарем. Для русского языка в качестве такого нормализованного глобального словаря используется составленный в 1968 году академиком И. К. Зализняком морфологический словарь русского языка. Он позволяет распознать и соответственно нормализовать более 3 млн. словоформ. В результате индексирования ПОД каждого нового документа представляется набором словоформ из глобального словаря, присутствующих в тексте документа, и поступает в виде соответствующего двоичного вектора для дополнения индекса системы. Индекс строится по инвертированной схеме и в двоичном виде отражает весь (полный) текст учтенных или накопленных документов. При удалении документа из системы соответственно удаляется и поисковый образ документа, т. е. соответствующий столбец индекса. Пользователь языком запросов ИПЯ полнотекстовой ИПС через соответствующий интерфейс запросов выражает свои информационные потребности по поиску документов, которые в общем плане, так же как и документы, индексируются и в виде двоичных векторов поисковых образов запросов поступают на поисковую машину. Механизм поиска основывается на тех или иных алгоритмах и критериях сравнения поискового образа запроса с поисковыми образами документов, образующими индекс системы. Результатом поиска является определение номеров документов, поисковые образы которых соответствуют или близки поисковому образу запроса. Далее специальная подсистема на основе установленных в хранилище документов указательных конструкций извлекает и доставляет соответствующие документы пользователю. Таким образом, программное обеспечение полнотекстовых ИПС обеспечивает полный технологический цикл ввода, обработки, поиска и получения документов. В практическом плане ИПС могут поставляться как готовый информационный продукт, т. е. с уже сформированной базой документов и интерфейсом поиска и доступа к ним.* В других случаях поставляется программная среда, позволяющая такую базу создать и сформировать тем самым документальную информационно-поисковую систему. Такие программные средства иногда называют полнотекстовыми СУБД. * Такими информационными продуктами, основанными в том числе и на полнотекстовых технологиях, являются многочисленные юридические информационно-справочные системы — «Кодекс», «Гарант», «Консультант плюс» и др.
6.3.2. Механизмы поиска документов в полнотекстовых ИПС В полнотекстовых ИПС поиск документов осуществляется по индексу системы через дескрипторный язык запросов с логическими операциями над словоформами, а также через другие механизмы использования поисковых образов документов и запросов. Принцип и механизм поиска документов по индексу системы очевидны. Пользователь должен указать путем перечисления и ввода в систему тех словоформ, набор которых выражает его информационные потребности. К примеру, если пользователю необходимо найти документы, содержание которых касается экспорта редкоземельных элементов, то запрос к системе может выглядеть следующим образом «экспорт редкоземельные элементы». В ответ система по индексу определит номера (группу) документов, где присутствует слово «экспорт», группу документов, где присутствует слово «редкоземельные», и группу документов, где присутствует слово «элементы». Ясно, что полнота и точность такого поиска будут оставлять желать много лучшего, так как в первой группе документов могут присутствовать в том числе и документы, в которых речь идет об экспорте чего-то другого, например леса, или об экспорте вообще. Во второй группе документов могут присутствовать документы, в которых речь идет, в том числе, о добыче или производстве редкоземельных элементов, но не об их экспорте. В третьей группе документов могут присутствовать и документы, в которых речь идет, скажем, о преступных элементах, что, конечно же, совершенно может не соответствовать благим информационным потребностям пользователя. Слабая эффективность подобного способа выражения информационных потребностей преодолевается некоторыми реляиионными дополнениями такого чисто дескрипторного языка запросов на основе посткоординации, только не понятий, а словоформ. В язык запросов вводятся логические операции отношений дескрипторов запроса — операция логического «И», операция логического «ИЛИ», операция логического отрицания «НЕ». Если словоформы запроса из приведенного выше примера объединить операцией логического «И», то система отберет только те документы, в которых одновременно присутствуют словоформы «Экспорт», «Редкоземельные», «Элементы». Несмотря на возможность ложной координации словоформ, такое усовершенствование чисто дескрипторного характера языка запросов приводит к существенному повышению эффективности поиска и предоставляет пользователю более развитые возможности по выражению своих информационных потребностей. Следует также добавить, что подобные принципы построения языка запросов повышают требования к квалификации пользователя, в частности по пониманию и оперированию логическими операциями. Вместе с тем, как показывает практика, большинство так называемых «неподготовленных» пользователей способно самостоятельно осваивать и применять подобные, в общем-то, интуитивно понятные языковые конструкции. На практике язык запросов полнотекстовой ИПС дополняется также операциями работы с датами и в ряде систем возможностями координатного анализа текста документов. Ранее неявно предполагалось, что единичным объектом поиска словоформ и соответственно областью действия логических операторов является документ, а не более мелкие его составляющие — абзацы, предложения. В системах с координатным анализом область действия логических операторов можно сужать вплоть до предложения. Примером таких возможностей является запрос на отыскание таких документов, где словоформы «экспорт», «редкоземельные», «элементы» присутствуют одновременно (операция «И») внутри одного предложения. Координатный анализ позволяет еще более повысить эффективность поиска релевантных документов, но требует более детального индексирования. Для словоформ словаря системы в индексе должны при осуществлении координатного анализа фиксироваться не только номера документов, но номера абзацев, номера предложений и номера соответствующих словоформ в порядке следования слов в соответствующих предложениях. Отличительной особенностью поиска документов по индексу является практическая независимость времени (скорости) поиски от объема базы документов, особенно если используется статический словарь. Для любого запроса, независимо от текущего объема базы документов, выполняется приблизительно одинаковое количество операций, связанных с просмотром строк индексного массива и определением совокупности номеров релевантных документов. Следующей стадией выполнения запроса является собственно извлечение из базы (файла документов) самих документов. Для этого обычно в полнотекстовой ИПС создается специальный массив (см. рис. 6.9) адресов начала расположения документов. В системах с динамически поддерживаемыми словарями время поиска при увеличении объема базы документов сначала также увеличивается (т. к. пропорционально увеличивается объем словаря и, соответственно, объем индекса), а затем так же, как в системах со статическими словарями, перестает зависеть от объема базы документов. Это объясняется тем, что с некоторой границы объема базы документов словарь системы уже набирает практически полный набор словоформ, присущих конкретной предметной области, и вероятность появления в новом документе слова, которого еще не было в словаре системы, резко падает.
|