Гайдамакин Н. А. 17 страница
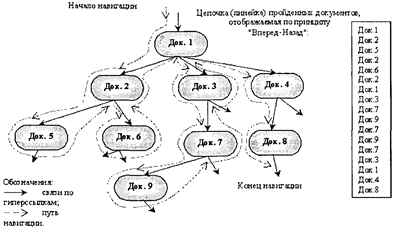
При наличии только иерархических связей между пройденными документами отработанным приемом отображения структуры ассоциативной цепочки пройденных документов может быть способ отображения файловой структуры информационных ресурсов компьютера, используемый в программах типа «Проводник» операционной системы MS Windows 95.
Рис. 6.13. Навигация по гипертекстовой базе документов и отображение цепочек пройденных документов Однако гипертекстовые сети документов, как будет рассмотрено ниже, являются не иерархическими, а гетерогенными. В гетерогенных сетях могут существовать как одноуровневые и межуровневые связи, так и обратные связи (отсылки), что вырождает само понятие иерархии в таких сетях. Наглядно такие структуры можно представить в виде неограниченной совокупности объемно переплетенной паутины узлов, хотя в отдельных сегментах таких структур могут в определенной степени сохраняться иерархические отношения. Отсюда, видимо, и родилось соответствующее название для распределенной гипертекстовой среды сети Интернет. «Блуждание» по подобным «лабиринтам» может образовывать столь запутанные «следы», что их визуально-наглядное отображение весьма затруднительно. Вместе с тем визуализация информационного поиска документов является чрезвычайно актуальной задачей, так как может предоставлять пользователям дополнительные аспекты анализа информации при аналитических исследованиях. Определенные методологические подходы к решению таких задач могут быть найдены на основе анализа семантической природы гетерогенных сетей гипертекстовых документов. 6.4.3. Модель организации данных в гипертекстовых ИПС К сожалению, несмотря на интенсивное развитие и всеобщее распространение в последнее десятилетие гипертекстовых технологий, к настоящему времени еще не проработана полностью формализованная модель организации гипертекстовых данных, которая бы обеспечивала формализованные процедуры синтеза (разработки, проектирования) и анализа (использования) гипертекстовых ИПС. Причина этого заключается, как и в целом для всех типов документальных систем, в пока непреодолимых сложностях в формализованном описании смысла текстов на естественном языке. Тем не менее в научной литературе имеется ряд работ, посвященных формальным моделям гипертекстовых структур.* Среди них можно выделить теорию паттернов, разработанную американским математиком У. Гренандером и развитую впоследствии для гипертекста Л. В. Шуткиным, тензорную модель А.В. Нестерова и подход логико-смыслового моделирования, представленный в работах М. М. Субботина, а также ряд других подходов. * См., например, Купер И. Р. Обзор отечественных гипертекстовых технологии // Теория и практика общественно-научной информации. — Вып. 13. — 1997.
Первые два подхода основываются на формализации отдельных текстов специальными математическими конструкциями. В теории паттернов текст рассматривается как сложноор-ганизованная совокупность отдельных тем, каждая из которых может выражаться фрагментом текста с минимальным размером в виде одной строки. Для описания гипертекста в теории паттернов вводятся также специальные объекты — кнопки (аналог гиперссылки) и связи с идентификаторами и дополнительными параметрами (тип, направленность и т. д.). В результате размеченный гипертекст можно описывать теми или иными паттерновыми конфигурациями. Вместе с тем теория паттернов не содержит средств синтеза обычного текста в гипертекст. Тензорный подход основывается на идеологии ранее рассматривающейся фасетной классификации, которая позволяет формализовано описать смысловую структуру текста в виде тензора,* а гипертекстовую структуру в виде ансамбля тензоров. Таким образом, сильной стороной тензорного подхода является возможность создания формализованных процедур анализа исходных текстов для создания гипертекстовых структур. * В упрощенном виде тензор можно трактовать как математический объект, завершающий иерархически усложняющуюся цепочку—«скаляр—вектор—тензор», т. е. как многокомпонентный объект в многомерном пространстве с заданным линейным преобразованием его компонент при переходе от одной системы координат к другой.
Наиболее развитым в практическом плане является подход, основанный на логико-смысловом моделировании человеческого мышления, позволяющий на основе семантической близости текстовых фрагментов связывать их в цельный осмысленный текст — семантическую сеть. Математическим аппаратом для описания структуры гипертекста выступает теория графов. Критерием для связывания текстов или их фрагментов в семантическую сеть является возможность установления между ними логических связок типа «есть», «является условием», «является причиной» и т. д. Построение на основе анализа текста таких связываний образует формализованные «высказывания», комбинируя которые можно получать определенные выводы или, как говорят, новые знания, или подтверждать истинность (доказывать) составных высказываний. В наиболее развитом виде такой подход реализуется в так называемых базах знаний, составляющих основу особой ветви информационных систем, называемых экспертными системами. Таким образом, при логико-смысловом моделировании структура гипертекста представляет (точнее, должна представлять) систему семантических связей между когнитивными элементами (понятиями, высказываниями) определенной предметной области. В результате сильной стороной такого подхода является возможность автоматизации создания (разметки) гипертекстовых структур на основе распознавания и соотнесения документов или их фрагментов к тем или иным узлам семантической сети. Если вернуться к структуре гипертекстовой ИПС (рис. 6.12), то ее центральным элементом является гипертекстовая база документов. По принципу формирования и управления гипертекстовыми базами их можно разделить на открытые (физически распределенные, или децентрализованные) и замкнутые (локально сосредоточенные). В замкнутых базах гипертекстовые документы находятся в едином локально-сосредоточенном и централизованно управляемом хранилище (файле или группе файлов со специальным (форматом). Такое хранилище образует замкнутую семантическую сеть документов, гипертекстовые связи которых не выходят за пределы хранилища. Соответственно внесение в базу новых документов или удаление документов производится непосредственно в месте расположения такой локальной базы. В открытых базах гипертекстовые документы не образуют единое локально размещенное хранилище, а располагаются автономно в любых элементах (узлах) информационной среды. При этом информационная среда может ограничиваться файловой структурой одного компьютера (диски, каталоги, подкаталоги), локальной или глобальной информационной сетью. В открытых базах семантическая гипертекстовая сеть документов не управляется из одного центра (узла), а совместно строится и поддерживается всеми пользователями, работающими в узлах информационной среды (сети). Несмотря на полную децентрализацию создания и функционирования, при определенных соглашениях (протоколах) об установлении и поддержании связей-гиперссылок, такие открытые семантические структуры тем не менее представляют единый развивающийся по определенным закономерностям организм. В настоящее время техника гиперссылок, применяемая в гипертекстовых системах, предполагает лишь однонаправленные связи, позволяющие осуществлять навигацию только в прямом направлении. «Вернуться» обратно в исходный документ можно только по запомненной цепочке пройденных документов, т. е. по схеме «Вперед-Назад». При этом прямой переход по гиперссылке осуществляется из определенного места, точнее контекста исходного документа, а возврат осуществляется обратно в документ в целом, т. е. фактически в его начало, что может разрывать контекст (сюжетно-тематический поток) анализа информации. В ранних гипертекстовых системах (проект Xanadu) предполагался двунаправленный характер гиперссылок, но практическая реализация такого подхода существенно усложняет протоколы навигации, так как требует более детального координатного адресования объектов и субъектов гиперссылок, идентифицирования пользователей и поддержания устойчивости документов (в смысле координатной структуры). В результате модель организации дачных в гипертекстовых базах описывается ориентированными невзвешенными графами с петлями и циклами. По определению граф G представляет структуру, состоящую из множества вершин
Рис. 6.14. Пример невзвешенного графа с петлями и циклами Для алгебраического задания графов, позволяющего эффективно алгоритмизировать машинное представление и оперирование графами, используются матрицы смежности и инциденций. Элементы
Матрица смежности полностью определяет структуру графа. В частности, для графа, приведенного на рис. 6.14, матрица смежности выглядит следующим образом:
Матрица инциденций
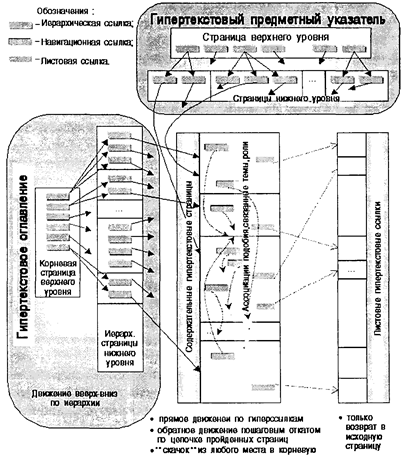
Графовая модель организации гипертекстовых данных является мощным инструментом, так как предоставляет ряд отработанных в теории графов алгоритмов для решения задач анализа и синтеза структур гипертекстовых баз данных, навигации и документального поиска в такого рода структурах. Вместе с тем, как показала практика развития гипертекстовых структур, модель ориентированных невзвешенных графов с петлями и циклами является лишь приближенным средством отражения реального процесса восприятия и анализа человеком документальной текстовой информации, не учитывая ряда гносеологических и семантических аспектов. Анализ работы человека с документальными источниками информации показывает, что ассоциативный ряд восприятия фрагментов и документов не однороден. Ассоциативные отношения выражаются в нескольких формах, в качестве основных из которых можно отметить: (a) сноски (переходы к ним используются с целью пояснения какого-либо термина, факта и т. д. с обязательным и скорым возвратом, т. е. без прерывания контекста восприятия основного повествования, мысли, идеи); (b) примеры (переходы по ним используются для иллюстрации частных проявлений объектов, процессов, явлений, и также с обязательным и скорым возвратом без прерывания основного контекста); (c) отступления, параллельные темы (переходы к ним используются для обогащения основной темы с необязательным или нескорым возвратом, что может приводить к прерыванию контекста изложения основной темы); (d) подобие по форме и содержанию (переходы используются для более глубокого уяснения основной темы через анализ других подобных по форме, содержанию, структуре или другим критериям тем, фрагментов, объектов, в том числе для рассмотрения других точек зрения и подходов, с необязательным возвратом, что приводит к длительному прерыванию исходного контекста с возможным формированием нового контекста); (e) особенности (переходы используются для рассмотрения отличий конкретной темы или объекта изложения от подобных по форме или содержанию объектов с обязательным возвратом без прерывания основного контекста); (f) подобие по сущности (переходы используются для построения ассоциативного ряда подобных или однородных объектов, являющихся частными проявлениями одного общего явления процесса, объекта, возврат не обязателен, что приводит к прерыванию исходного контекста, в том числе и для формирования более общего или более широкого контекста). Перечисленные формы ассоциативных отношений определяют необходимость дифференциации типов связей-гиперссылок в гипертекстовых базах документов. По признаку прерывания контекста материала можно выделить два типа гиперссылок: • с прерыванием контекста, назовем их навигационными гиперссылками; • без прерывания контекста, т. е. с обязательным возвратом, назовем их листовыми гиперссылками. Навигационные гиперссылки формируют ассоциативные связи-отношения (с), (d) и (f) типа. Переходы по навигационным связям не имеют каких-либо пространственных и иных ограничений и призваны формировать многоплановый сюжетно-тематический поток. Листовые гиперссылки формируют ассоциативные связи-отношения (а), (b) и (е) типа. Переходы по листовым гиперссылкам ограничиваются единичной длиной к вершинам (узлам), из которых нет другого выхода. Направленность дуг-связей по листовым гиперссылкам является обратной по отношению к навигационным гиперссылкам. Это означает, что прямой переход по ним осуществляется не в конкретное место отсылаемого документа, а в целом на документ (в начало) листовой вершины, и наоборот, возврат в документ исходной вершины происходит адресно, т. е. в место расположения листовой гиперссылки. Кроме ассоциативных отношений при восприятии документальных источников важную роль имеют и классификационные отношения фрагментов и документов в следующих основных формах: i) «родо-видовая» иерархия (переходы используются для углубления, детализации рассмотрения или выбора темы, (фрагмента, сюжета); ii) иерархически-логические соотношения в форме «вводный материал — основной материал — заключительный материал» (переходы используются для построения или изменения логико-тематического повествования); iii) ролевые отношения, например такие, как «Объект-субъект-средство-место-время-участники действия» и др. (переходы используются для формирования или расчленения целостного представления сложных разноплановых явлений, процессов, событий). Реализация дифференцированного подхода к образованию и использованию гиперссылок в открытых децентрализованно развивающихся системах является непростой проблемой, так как требует переработки и усложнения протоколов передачи и использования гипертекста, т. е. массового принятия в сети новых и более сложных правил всеми пользователями и разработчиками информационных узлов распределенной гипертекстовой информационной инфраструктуры. Поэтому подходы, связанные с дифференциацией характера гиперссылок, нашли свое воплощение в первую очередь в закрытых (локальных) гипертекстовых ИПС. В качестве примера развитых в этом смысле гипертекстовых систем можно привести информационно-справочные системы помощи в среде ОС MS Windows. Модель организации данных в гипертекстовых справочных системах Microsoft Windows основана на сочетании дифференциации ассоциативных гиперссылок и иерархического принципа организации фрагментов и документов. Схематично модель организации данных можно отобразить схемой, представленной на рис. 6.15.
Рис. 6.15. Модель организации данных в гипертекстовых справочных системах Microsoft Windows Как видно из представленной схемы, данная модель сочетает апробированные и интуитивно понятные большинству пользователей по аналогии работы с книгой иерархическую навигационную структуру (гипертекстовые оглавление и предметный указатель) с дифференцированными ассоциативными гиперссылками, выражающими рассмотренные выше различные типы ассоциаций при изучении и восприятии текстовой информации. Вместе с тем использование справочных гипертекстовых систем все же не может полноценно заменить традиционные книги и учебники, так как большинство таких систем не обеспечивает привычный пользователю по обычным книгам последовательный повествовательный поток, разрывая его по пространственной или предметной иерархии, и, кроме того, требуют от пользователя новых навыков работы с текстовой информацией и более точного осознания в любой момент своих информационных потребностей. Как и в моделях организации фактографических данных, в модели организации гипертекстовых данных важное значение имеет целостная составляющая. Применительно к гипертекстовым данным целостность и согласованность данных означает, прежде всего, целостность ссылок и выражается следующим принципом — «для каждой гиперссылки должен существовать адресат». Иначе говоря, целостность гипертекстовых данных выражается в отсутствии оборванных, ведущих в «никуда» связей. Контроль целостности ссылок возможен на основе создания и ведения единого централизованного реестра гиперссылок, как это и осуществляется в замкнутых гипертекстовых базах. Специальный компонент программного обеспечения гипертекстовой СУБД при удалениях документов (страниц) по реестру гиперссылок находит имеющиеся в других документах ссылки на удаляемый документ и аннулирует их. В открытых распределенных гипертекстовых системах реализация принципа целостности ссылок встречает существенные трудности, так как децентрализованный принцип функционирования таких систем затрудняет создание и ведение единого реестра гиперссылок. В случае распределенной гипертекстовой среды за информацию на любом узле отвечает отдельный независимый пользователь, вольный по своему усмотрению добавлять или удалять гипертекстовые страницы (документы). Ввиду отсутствия централизованного реестра и однонаправленного* характера гиперссылок, при удалении какой-либо гипертекстовой страницы пользователь не может знать, имеются ли в других документах гиперссылки на удаляемую страницу. В таких ситуациях гиперссылки из других страниц, отсылающие на удаляемые страницы, оказываются оборванными. * То есть гиперссылка находится в источнике отсылки, а на отсылаемом адресате никакой информации по гиперссылке нет.
Еще более сложной проблемой является обеспечение согласованности данных. Применительно к гипертекстовым системам согласованность данных заключается в поддержании адекватности семантики гиперссылок. Говоря иначе, должна обеспечиваться устойчивость смысловых ассоциаций по гиперссылкам. Однако если изменить содержание того документа, на который отсылает гиперссылка из другого документа, то смысловая ассоциация, закладываемая в гиперссылку, может нарушиться, и в отсылаемом документе речь может пойти на совершенно другую тему. Тривиальное решение проблемы согласованности гипертекстовых данных заключается в запрете изменения содержания документов, после внесения их в гипертекстовую базу. Такой подход применяется в некоторых системах на основе замкнутых гипертекстовых баз документов. В открытых системах с децентрализованным характером функционирования такой подход неприемлем. Вместе с тем одним из возможных направлений решения этой проблемы является практикуемая в среде WWW идеология «публикаций». Среда WWW в этом смысле трактуется как гигантское электронное апериодическое издание, на страницах которого каждый желающий может «опубликовать» свои документы. Проблема согласованности данных по гиперссылкам может решаться в такой идеологии через введение в гиперссылки темпоральных параметров существования и соответствующих временных ограничений на содержательную изменчивость гипертекстовых публикаций. Иначе говоря, могут быть определены «времена жизни» гиперссылок, в течение которых гипертекстовые публикации не могут быть изменены. Однако, как и в случае введения двунаправленного характера гиперссылок, такой подход потребует перестройки протоколов и других соглашений в гигантской распределенной информационной инфраструктуре. 6.4.4. Формирование связей документов в гипертекстовых ИПС Еще одним важным элементом в структуре гипертекстовых ИПС является подсистема формирования связей документов (см. рис. 6.12). Как и в случае систем на основе индексирования документов, существует два подхода к формированию связей документов в гипертекстовых ИПС — ручной и автоматизированный. В первом подходе смысловые связи содержания документа с другими документами системы определяются самим пользователем (автором документа, администратором и т. п.). Такой подход имеет свои преимущества, так как пользователь устанавливает смысловые ассоциации нового документа с другими документами базы на основе многоаспектного многокритериального анализа содержания документа, что не может быть в полной мере воспроизведено никакими автоматизированными формальными или эвристическими алгоритмами. Вместе с тем у ручного подхода имеется и ряд существенных недостатков. Человеческие возможности по скорости и объему смыслового анализа текстовых документов ограничены и не могут во многих случаях обеспечить приемлемые временные или организационные расходы на обработку и установление связей при больших потоках поступления документов в систему. В качестве примера можно привести гипертекстовую систему, агрегирующую в реальном масштабе времени поток новостных сообщений информационных агентств и другие тому подобные ситуации. Однако даже если временных или иных ограничений на ввод документов в гипертекстовую ИПС нет, то другой проблемой является ограниченность человеческой памяти пользователя (администратора) по содержанию введенных ранее в систему документов. Иначе говоря, пользователь, устанавливая гипертекстовые ассоциации нового документа, помимо смыслового содержания вводимого документа, одновременно должен представлять и помнить смысловое содержание всех других ранее введенных в систему документов, что, конечно же, без дополнительных классификационных или иных приемов в большинстве случаев нереально. Кроме того, ручной подход, как и в случае индексирования документов, требует определенной квалификации пользователя-анализатора в соответствующей предметной области ИПС, что приводит к дополнительным проблемам. Тем не менее в некоторых областях ручной способ установления гиперссылок сохраняет свое значение или является единственно возможным. Это, прежде всего, касается среды WWW в сети Интернет. Гипертекстовые ссылки публикуемых на Web-узлах документов на другие документы Сети пользователи определяют сами,* исходя из собственных представлений об ассоциации своей страницы с другими публикациями и узлами WWW. Вместе с тем такой подход не может по-настоящему полно и адекватно ассоциировать содержание публикуемой страницы с ресурсами Сети, так как ни один пользователь или Web-мастер, конечно же, не может знать и представлять всех ресурсов Сети. Отчасти эта проблема решается через так называемые поисковые машины, размещающиеся на известных всем пользователям узлах WWW и представляющие собой, как правило, сочетание информационно-поисковых классификационных каталогов и полнотекстовых ИПС, индексирующих все публикации в WWW. В этом случае гипертекстовые ассоциативные цепочки образуются через отсылку на узел поисковой машины, а от него к релевантным документам, располагающимся на других узлах сети. * Совместно с так называемыми Web-мастерами и Web-дизайнерами. Автоматизированный подход к формированию и установлению гипертекстовых связей применяется в развитых замкнутых гипертекстовых ИПС. В основе автоматизации формирования гиперссылок лежит использование принципов поиска релевантных по смыслу документов, применяемых в системах на основе индексирования. На практике применяются две основные технологии автоматизированного установления ассоциативных гипертекстовых связей: • технология поисковых образов документов на основе техники ключевых слов (терминов); • технология полнотекстового индексирования и поиска. Использование технологии ключевых слов имеет несколько разновидностей. Один из вариантов предусматривает предварительное создание для предметной области гипертекстовой ИПС взвешенного словаря ключевых терминов. При вводе нового документа в системе производится его индексирование по словарю ключевых терминов и формируется ПОД. В простейшем случае в качестве ПОД используется суммарный вес терминов, присутствующих в тексте документа. Далее поисковый образ нового документа сравнивается с поисковыми образами ранее введенных документов и при превышении определенного порога «сходства» устанавливаются гипертекстовые связи с соответствующими документами. В другом варианте используется предварительно созданная классификационная рубрикация предметной области. Скаждой рубрикой связывается опять-таки предварительно созданный набор ключевых терминов или их сочетаний. На основе входного индексирования производится соотнесение вводимого документа с той или иной рубрикой и на этой основе устанавливаются гипертекстовые связи с соответствующей группой документов. Полнотекстовые технологии по сути аналогичны технике ключевых слов с учетом только более широкого текстового базиса индексирования и использования тех или иных критериев установления близости поисковых образов документов. В некоторых системах практикуются полуавтоматизированные технологии на основе полнотекстового поиска. В таких системах пользователь-анализатор выделяет из текста документа наиболее характерные по его содержанию фрагменты, которые используются в качестве запроса-образца для сформирования ПОЗ и полнотекстового поиска релевантных документов, с которыми и устанавливаются гипертекстовые связи.
|
 и множества ребер
и множества ребер  , их соединяющих. По ребрам осуществляется движение, переход от одной вершины к другой. Ориентированные ребра, по которым переход возможен только в одном направлении, называются дугами. Применительно к структуре гипертекстовой базы вершины графа соответствуют документам, а дуги гиперссылкам. Невзвешенность означает равнозначность любых дуг по переходу, или, иначе говоря, одинаковую «стоимость» перехода по любой гиперссылке. Петлей называется дуга, начальная и конечная вершины которой совпадают, т. е. применительно к гипертексту внутренняя гипер-ссылка на другой фрагмент того же документа. Путем (или ориентированным маршрутом) называется последовательность дуг, в которой конечная вершина любой дуги, кроме последней, является начальной вершиной следующей дуги. В невзвешенном графе, когда стоимость (вес) всех дуг одинакова, длиной пути является число дуг, входящих в путь. Путь
, их соединяющих. По ребрам осуществляется движение, переход от одной вершины к другой. Ориентированные ребра, по которым переход возможен только в одном направлении, называются дугами. Применительно к структуре гипертекстовой базы вершины графа соответствуют документам, а дуги гиперссылкам. Невзвешенность означает равнозначность любых дуг по переходу, или, иначе говоря, одинаковую «стоимость» перехода по любой гиперссылке. Петлей называется дуга, начальная и конечная вершины которой совпадают, т. е. применительно к гипертексту внутренняя гипер-ссылка на другой фрагмент того же документа. Путем (или ориентированным маршрутом) называется последовательность дуг, в которой конечная вершина любой дуги, кроме последней, является начальной вершиной следующей дуги. В невзвешенном графе, когда стоимость (вес) всех дуг одинакова, длиной пути является число дуг, входящих в путь. Путь 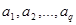 называется замкнутым, если в нем начальная вершина первой дуги
называется замкнутым, если в нем начальная вершина первой дуги 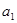 совпадает с конечной вершиной последней дуги
совпадает с конечной вершиной последней дуги  . Если в замкнутом пути любая вершина графа используется не более одного раза (за исключением начальной и конечной, которые совпадают), то такой замкнутый путь называется циклом. Пример графа приведен на рис. 6.14.
. Если в замкнутом пути любая вершина графа используется не более одного раза (за исключением начальной и конечной, которые совпадают), то такой замкнутый путь называется циклом. Пример графа приведен на рис. 6.14.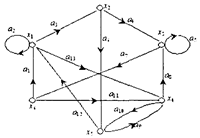
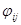 матрицы смежности
матрицы смежности 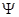 графа G определяются следующим образом:
графа G определяются следующим образом: , если в G существует дуга
, если в G существует дуга  ;
;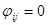 , если в G не существует дуга
, если в G не существует дуга 
 графа G с n вершинами и m дугами представляет собой матрицу размерности nxm и ее элементы
графа G с n вершинами и m дугами представляет собой матрицу размерности nxm и ее элементы  определяются следующим образом:
определяются следующим образом: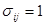 , если вершина
, если вершина  является начальной вершиной дуги
является начальной вершиной дуги 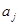 ;
; , если вершина
, если вершина  , если вершина
, если вершина