Гайдамакин Н. А. 11 страница
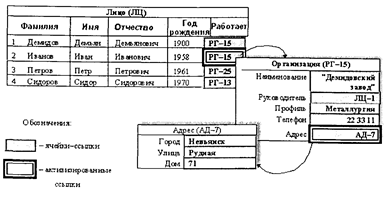
4.3.4. Особенности обработки данных в СУБД с сетевой моделью организации данных Основные принципы и способы обработки данных, рассмотренные для реляционных СУБД, также характерны и для немногих сохранившихся, и продолжающих развиваться СУБД с сетевой моделью организации данных. В сетевых СУБД подобным же образом, как и в реляционных СУБД, реализуются операции поиска, фильтрации и сортировки данных. Распространенность и популярность языка SQL реляционных СУБД привели к тому, что подобные языки для реализации запросов к базам данных были разработаны или просто «внедрены» в сетевые СУБД. При этом так же, как и реляционные СУБД, современные сетевые СУБД предоставляют пользователю и специальные диалогово-наглядные средства формирования запросов. Также в сетевые СУБД встраиваются специальные макроязыки для формирования сложных последовательностей взаимосвязанных запросов (аналог процедур), хранящихся вместе с базой данных. Вместе с тем обработка данных в СУБД с сетевой моделью организации данных, как уже отмечалось, характеризуется уже упоминавшейся принципиальной особенностью, которой нет в реляционных СУБД. Это непосредственная «навигация» по связанным данным (по связанным записям) в разных информационных объектах (аналоги таблиц в реляционных СУБД). Как уже отмечалось, возможность непосредственной навигации обусловлена тем, что в сетевых СУБД ссылки-связи между записями различного типа (различных таблиц) задаются не через внешние ключи, а через специальные указатели на физические адреса расположения связанных записей. Просматривая, к примеру, в сетевой СУБД записи объекта «Лицо» и выбрав запись «Иванов» (т. е. поместив табличный курсор на соответствующую запись), можно через активизацию поля «Работает» вызвать на экран поля связанной записи в объекте «Организация» и просмотреть соответствующие данные, а далее, при необходимости, через активизацию поля «Адрес» в записи по объекту «Организация» вызвать и просмотреть данные по дислокации места работы сотрудника «Иванов» и т. д. (см. рис. 4.27).
Рис. 4.27. Навигация по связанным записям в сетевых СУБД В реляционных СУБД для реализации такого просмотра понадобилось бы создать и выполнить запрос на выборку данных из трех таблиц на основе внутреннего (INNER JOIN) соединения при условии отбора соответствующей фамилии сотрудника: SELECT Лицо.*, Организация.*, Адрес.* FROM (Лицо INNERJOIN (Адрес INNERJOIN Организация ON Адрес.№№=Организация.Адрес) ON (((Лицо.Работает = Организация.Наименование) WHERE (((Лицo.Фaмилия)=»Ивaнoв»)); При этом, если пользователю необходимо посмотреть те же данные, но для другого сотрудника, то необходимо изменить условия отбора по фамилии и заново выполнить запрос. В сетевых же СУБД для этого достаточно лишь «вернуться» в исходный объект «Лицо», переместить курсор на другую запись и повторить навигацию. Данный пример показывает, что навигационные возможности сетевых СУБД позволяют пользователю реализовывать свои информационные потребности («беседовать» с базой данных) более естественным интерактивным способом, шаг за шагом уточняя свои потребности, и тем самым более глубоко и наглядно анализировать (изучать) данные. Навигационный подход к анализу и просмотру данных, естественный уже для ранних сетевых СУБД, впоследствии (в конце 80-х годов) был реализован в технике гипертекста, и в созданной на его основе новой разновидности документальных информационных систем — гипертекстовых информационно-поисковых систем. Вместе с тем навигация по связанным данным порождает и ряд своих специфических проблем, таких как «потеря ориентации» и трудности с визуализацией цепочек «пройденных» информационных объектов (записей). Схемы баз данных, отражающих сложные предметные области, могут насчитывать десятки различных информационных объектов и еще большее количество связей между ними. В результате такие базы данных представляют сложное многомерное информационное пространство из множества разнотипных наборов записей, пронизанных и опутанных порой несметным количеством связей. «Путешествуя» в таком клубке, легко «сбиться с пути», потерять общую картину состояния данных.* При этом следует иметь в виду, что особенности человеческого мышления таковы, что человек способен удержать в представлении с полным отслеживанием всех связей и нюансов не более 3-4 сложных объектов.** * То есть оказаться в ситуации, которая образно выражается известной поговоркой «За деревьями леса не видно». ** Этим, кстати, еще из древности определяется троичная система организации структуры воинских подразделений для эффективного управления ситуацией на поле боя.
Иногда объектом анализа являются не конкретные реквизиты связанных записей, а сама схема связанных записей, т. е. визуализированная цепочка имен связанных от исходного информационного объекта записей. Использование множественного типа значений в полях информационных объектов сетевых СУБД позволяет реализовывать все типы связей, что приводит к «пучковости» исходящих или входящих связей типа «один-ко-многим», «многие-ко-многим». Визуализация таких цепочек на двумерном экране компьютера может представлять существенные графические сложности. На рис. 4.28 для примера приведен вариант изображения цепочки связанных записей с корневой записью «Иванов» объекта «Лицо». Такая визуализация позволяет быстро составить общее представление о полученном образовании, трудовой деятельности и проживании данного лица. При этом длина цепочки ограничена тремя последовательно связанными записями, но, как видно из рисунка, и в этом, в общем-то простом для многих жизненных ситуаций случае, достаточно сложно отобразить общую схему связей, не «запутывая» ее восприятие.
Рис. 4.28. Пример визуализации цепочки связанных записей Навигация по связанным записям в реляционных СУБД открывает новые возможности анализа данных на основе иных, нежели реляционные, семантических принципах. В частности, становится возможным реализация процедур поиска и построения смысловых окрестностей какой-либо записи по ее связям в базе данных, применение различных процедур информационного анализа на основе алгоритмов поиска на графах и т. п. Одним из направлений развития современной теории и техники СУБД является линия объектно-ориентированных СУБД, которые на витке наработанных в конце 70-х и в 80-х годах решений по реляционным СУБД, обеспечивают новые возможности по обработке данных на основе методов навигации и визуализации, впервые представленных в сетевых СУБД. 4.4. Вывод данных Результаты обработки данных должны использоваться в том порядке и в тех формах, которые приняты в предметной области АИС. Решение этой задачи обеспечивается комплексом функций СУБД, определяемым термином «вывод данных». В более узком плане под выводом данных понимается комплекс функций СУБД по предоставлению пользователю результатов обработки, хранения и накопления данных в наиболее удобном для восприятия виде, документирования выводимой информации, а также по передаче данных в другие (внешние) системы и форматы. Вывод данных осуществляется: • через выходные (выводные) формы; • через «отчеты»; • через экспорт данных. Выходные формы по смыслу аналогичны входным формам, т. е. формам для ввода, просмотра и редактирования данных. При этом, как правило, базовым источником дачных для форм являются не таблицы данных, а результаты выполнения запросов. Таким образом, главной функцией выводных форм является предоставление пользователю результатов выполнения запросов в наиболее удобном и привычном «бланковом» виде. В отличие от входных, особенностью выводных форм как экранных объектов является то, что помимо надписей и полей с данными в них присутствуют так называемые элементы управления— кнопки, переключатели, поля-списки, которые используются для задания пользователем тех или иных параметров выполнения запросов. В развитых СУБД запросы с параметрами реализуются через технику форм, в которых пользователь через элементы управления определяет конкретные условия отбора. На рис. 4.29 приведен пример формы для отображения запроса, формирующего список командировок сотрудников, в зависимости от выбранного пользователем через переключатели года и в соответствующем списке месяца.
Рис. 4.29. Пример формы для реализации и отображения результатов запроса с параметрами Отчеты решают задачу документирования выводимых данных, т. е. представления результатов обработки и накопления данных в форме текстового документа, который можно распечатать или приобщить к другому текстовому документу. Отчеты во многом аналогичны выводным формам и, по сути, представляют печатные формы для результатов накопления и обработки данных. Отличительной особенностью отчетов является то, что они строятся по правилам текстовых документов, т. е. отображаемые данные разделяются на страницы и разделы с соответствующими элементами (поля, колонтитулы) и параметрами форматирования (шрифт, отступы, выравнивание). Так же как и в формы, в отчеты могут помещаться элементы управления, среди которых особое значение имеют вычисляемые поля, т. е. поля, содержимое которых формируется на основе вычисления определенных статистических функций по помещаемым в отчет данным. Для примера на рис. 4.30 приведен отчет для вывода данных по командировкам сотрудников. Поля с надписями «ИТОГО» являются как раз вычисляемыми элементами через функцию «Сумма» поданным в поле «Аванс». Помимо полей с данными и вычисляемых полей в отчеты могут внедряться различные графические объекты для формирования логотипов и других поясняющих рисунков и, кроме того, такие средства наглядного отображения табличных данных, как диаграммы. На рис. 4.30 во втором разделе отчета приведена диаграмма, отображающая распределение итогового аванса на командировочные расходы сотрудников известной конторы по месяцам первого квартала.
Рис. 4.30. Пример отчета Экспорт данных решает технологические задачи резервирования, архивирования данных или передачи накопленных в АИС данных во внешние системы и форматы и реализуется через уже рассмотренные запросы на добавление данных и запросы на создание таблицы. Таблицы-приемники в этом случае находятся во внешних файлах баз данных, созданных под управлением СУБД того же типа или СУБД, поддерживающей протокол ODBC. Некоторые СУБД обеспечивают экспорт данных в текстовые файлы. При этом табличные данные в строках текстовых файлов размещаются последовательно по строкам и ячейкам экспортируемой таблицы, т. е. слева направо, сверху вниз, отделяясь друг от друга специальными разделителями, например символом «\».* Такой порядок размещения табличных данных в текстовых файлах получил название «унифицированного формата обмена данными» (УФОД). Соответственно, как уже отмечалось при рассмотрении вопроса по вводу данных, многие СУБД имеют специальные режимы не только экспорта, но и импорта данных их текстовых файлов, построенных на основе УФОД-формата. * Слэш налево.
Вопросы и упражнения 1. Кем и в каких целях применяется язык SQL в реляционных СУБД? 2. Какова структура и каковы функции структурных элементов SQL-ииструкций? 3. Что включают и в каких целях используются «включающие» языки? 4. Поясните процесс «открытия» таблиц и форм. Что происходит при этом с данными? 5. В чем преимущества и недостатки представления и отображения данных в табличном виде и в виде экранных форм? 6. В текстовых и табличных редакторах изменения данных (корректировка, добавление, удаление) фиксируются во внешней памяти в момент закрытия файлов (если не было явной предварительной команды «Сохранить»). Каков порядок фиксации изменений данных в таблицах СУБД? 7. В чем сходства и различия фильтрации данных и запросов на выборку данных? 8. Постройте запрос по формированию списка студентов 1980 года рождения с реквизитами — ФИО, Уч. Группа, Дата рождения, из таблицы «Студенты» (№№, ФИО, Уч. Группа, Дата рождения, Год поступления). К какому типу относится данный запрос? 9. Постройте запрос по формированию списка сотрудников руководящего звена не старше 35 лет, с окладом свыше 1000 р. и с полным набором реквизитов из таблицы «Сотрудники» (Таб.№, ФИО, Должность — Начальник отдела, Зам. начальника отдела, Начальник сектора, Ведущий инженер. Старший инженер, Инженер, Техник, Оклад, Дата Рождения). К какому типу относится данный запрос? 10. Интерпретируйте на естественном языке следующую SQL-инструкцию: SELEСТСотрудники.Таб. —№,Сотрудиики.Фамилия,Сотрудники.Имя FRОМ Сотрудники WHERE ((Сотрудники.Должность=«Инженep» Or Сотрудники.—Должность=«Методист») AND (Сотрудники.Оклад> 100р.)); 11. Постройте запросы по формированию списка организационных форм, списка профилей деятельности и списка сочетаний организационной формы с профилем деятельности организаций из таблицы «Организации»—Код, Код ОКПО, Наименование, Условное наименование, Профиль деятельности (Производственный, Коммерческий, Посреднический, Научно-производственный), Организационная форма (ЗАО, ОАО, и т. д.). 12. Интерпретируйте на естественном языке следующие SQL-инструкции: SELECT Квартиры.№, Здания.№_Дома, Здания. Улица FROM Квартиры INNER JOIN Здания ON Квартиры.№№_Здания = Здания. №№ WHERE (((Квартиры.Кол Комнат=1) Or (Квартиры. КолКомнат=4)) AND ((Квартиры.Этаж >=4) AND (Квартиры-.Этаж<=6))); SELECT Сотрудники.Таб_№. Сотрудники. ФИО, Подразделения. Наименование, Sum(Нетрудоспособность. ДатаОкончания Нетрудоспособность.Дата Начала) AS ОбщКолНетр FROM (Сотрудники INNER JOIN Подразделения ON Сотрудники.№_Подразделения = Подразделения.№№)INNERJOIN Нетрудоспособность ON Нетрудоспособность. №_Сотрудника = Сотрудники. Ta6_№) WHERE (Нетрудоспособность.ДатаНачала>=#01.01.1999#) AND(Нетрудоспособность.ДатаНача.1а<=#31.12.1999#) AND способность.ДатаОкончания<=#31.12.1999#) GROUP BY Нетрудоспособность. №_Сотрудника; 13. Постройте запрос по формированию списка категорий фильмов видеотеки с группировкой по кинокомпаниям, и вышедших в 90-х годах из таблицы «Фильмы»—№№, Название, Режиссер, Год выхода, Кинокомпания, Категория (Комедия, Психологическая драма. Боевик, Триллер, Детектив, Мистика), Инв.№№ видеокассеты. 14. В базе данных с таблицами «Подразделения»—№№, Наименование, Руководитель; «Сотрудники»— Таб№, ФИО, №№ подразделения, Должность, «Материальные средства» — Инв.№, Наименование, Тип, №№ Подразделения, Таб № мат. ответственного сотрудника. Начальная стоимость, % амортизации, Построите запрос по формированию списка материально ответственных сотрудников со следующим набором реквизитов — Таб. №, ФИО, Наименование подразделения. Должность. 15. В базе данных с таблицами из предыдущего примера построите запрос по формированию перечня всех подразделений с данными по их средствам вычислительной техники при следующем наборе реквизитов—№№ подразделения. Наименование, Руководитель, Инв.№ мат. средства. Наименование мат. средства, Тип мат. средства, ФИОмат. ответственного сотрудника. 16. В базе данных с таблицами «Лицо» —№№. ФИО, Дата рождения, Месторождения, Паспортные данные; «Владение» — Код владения, №№ Лица. №№ имущества. Вид (Единоличное, Совместное), Доля, Дата приобретения. Данные документа. Дата окончания владения; «Имущество» — №№ имущества, Категория (Недвижимость, Автотранспорт, Акции, Ювелирные изделия. Художественные произведения. Бытовая техника. Земельный надел), Описание. Стоимость, постройте запрос по формированию списка лиц (ФИО, Дата рождения. Месторождения, Паспортные данные), имеющих в единоличном владении недвижимость на сумму свыше 10 000 минимальных размеров оплаты труда. 17. В базе данных с таблицами из предыдущего примера постройте запросы по формированию списка лиц (№№, ФИО, Дата рождения, Месторождения, Паспортные данные), имеющих в совместном владении земельные наделы, и дополнительными реквизитами —Доля и Стоимость доли, а также запрос по формированию сведений о самой высокой стоимости имущества по всем возможным категориям. 18. Постройте запрос по формированию списка всех запасных частей, относящихся к ходовой части со всеми реквизитами из таблицы «Запчасти» — Код, Код автомобиля. Наименование, Тип (Двигатель, Кузов, Ходовая часть. Электрооборудование, Аксессуары), Марка, Количество на складе. Цена единицы, Поставки прекращены, с дополнительным реквизитом Общая стоимость. 19. Постройте запрос по формированию набора записей со всеми реквизитами из таблицы «Преподаватели»—№№, ФИО, Уч. степень, Уч. звание. Пед. стаж. Специализация, для которых имеются вакансии по прикладной математике в таблице «Вакансии» со следующим набором реквизитов—№№, Вуз, Должность, Треб. пед. стаж. Специализация. К какому типу относится данный запрос? 20. Постройте запрос для формирования набора записей со всеми реквизитами по оборудованию из таблицы «Оборудование»—Зав.№, Производитель, Марка, Сырье, Производительность, которое может применяться на всех предприятиях, использующих в качестве сырья очищенное зерно, данные по которым приведены в таблице «Предприятие» — Наименование. Треб. производительность и,. Используемое сырье. К какому типу относится данный запрос? 21. Постройте запрос по формированию списка сотрудников с полным набором реквизитов из таблицы «Сотрудники» — Таб_№, ФИО, Должность, Подразделение, Телефон, которые входят по таблице «Штатное расписание» — Наименование должности. Категория, Оклад, в пятерку наиболее оплачиваемых должностей. К какому типу относится данный запрос? 22. Интерпретируйте на естественном языке следующие SQL-инструкции: SELECT Автомобили. * FROM Автомобили WHERE ((Автомобили.Код) = Any (SELECT Запчасти.Код_автомобиля FROM ((Запчасти INNER JOIN Поставки ON Запчасти. Код = Поставки.Код_запчасти) INNER JOIN Поставщики ON Поставки. Код_поставщика = Поставщики.Код) WHERE (Поставщики.Город=«Саратов») AND (Зап- части.Тип=«Стеклооборудование»);); SELECT Клиенты. * FROM Клиенты INNER JOIN Счета ON Клиенты.Код = Счета.КодКлиента WHERE (Счета.Остаток>= All (SELECT Товары.Стоимость FROM Товары WHERE Тoвapы.Kaтeгopия= «Бытовая техника»);); 23. Постройте запрос по переименованию производителя автомобилей завода «ИжМаш» в «ИжVWMaш» в таблице «Автомобили» (Код, Производитель, Модель, ГодНачалаПроизводства, ГодПрекр Производства, Фото. 24. Оптимизируйте следующие условия отбора записей по таблицам «Имущество» и «Сотрудники»: когда налог превышает тысячу единиц минимального размера оплаты труда (МРОТ) — Имущество. Стоимость * СтавкаНалога — 1000*МРОТ > 0 когда десятикратная стоимость с учетом амортизации больше оклада сотрудников — 10*(Имущество. Стоимость — Имущество. Стоимость* Имущество. %Износа) — Сотрудники. Оклад > 0 25. Оптимизируйте следующее условие по отбору записей по таблицам «Сотрудники» и «Премирование»: сотрудники, премированные на величину более должностного оклада, равного 1000 р. — (Премирование.Сумма > Сотрудники. Оклад) AND (Сотрудники. Оклад = 1000р.) 26. Согласно одному из проектов закона о декларировании расходов все операции по оплате приобретении или услуг гражданами, стоимостью свыше 1000 МРОТ, должны осуществляться только безналичным расчетом через банки, а данные по таким операциям автоматически сообщаться в налоговые органы. В базе данных АИС финансово-кредитной организации имеется и ведется таблица «Проводки» (№№, Дата/Время, Сумма, №Счета, Приход/ расход). Предложите на основе технологии «События-Правила-Процедуры» вариант построения схемы обработки данных при принятии и вступлении в силу подобного закона. 5. Распределенные информационные системы В некомпьютерных информационных технологиях информационные ресурсы организаций и предприятий, с одной стороны, разделены и распределены логически (по различным подразделениям, службам) и физически (находятся в различных хранилищах, картотеках, помещениях). С другой стороны, информационные ресурсы создаются и используются своей определенной частью или в целом коллективно или индивидуально. Иначе говоря, с одними и теми же документами, картотеками и прочими информационными массивами могут в рамках общего проекта или в своей части одновременно работать несколько сотрудников и подразделений. Первоначальные подходы к созданию баз данных АИС заключались в сосредоточении данных логически и физически в одном месте — на одной вычислительной установке. Однако такая организация информационных ресурсов чаще всего является не совсем естественной с точки зрения традиционных («бумажных») информационных технологий конкретного предприятия (организационной структуры) и при внедрении АИС происходит «ломка» привычных информационных потоков и структур.* Все информационные ресурсы предприятия, организации сосредотачиваются централизованно в одном месте, что требует определенных технологических, кадровых и материальных затрат и может порождать ряд новых проблем и задач. Следует отметить, что такому подходу также способствовала и господствующая на начальном этапе автоматизации предприятий и организаций в 70-х годах тогдашняя парадигма вычислительных систем — общая мощная вычислительная установка (main frame) и групповая работа пользователей с удаленных терминалов через системы разделения времени. * В данном контексте более понятен сам термин — «внедрение», предполагающий сопротивление.
Опыт внедрения автоматизированных систем управления в различных организационных структурах в 70-е— 80-е гг. показал не всегда высокую эффективность подобной автоматизации, когда новые технологические информационно-управленческие подразделения (отдел автоматизации, отдел АСУ, информационная служба и т. п.) и новые электронные информационные потоки зачастую функционировали вместе с сохраняющимися традиционными организационными структурами, а также вместе с традиционными («бумажными», «телескопными») информационными потоками. Осознание подобных проблем постепенно стало приводить к мысли о распределенных информационных системах. 5.1. Понятие распределенных информационных систем, принципы их создания и функционирования
Впервые задача об исследовании основ и принципов создания и функционирования распределенных информационных систем была поставлена известным специалистом в области баз данных К. Дейтом в рамках уже не раз упоминавшегося проекта System R, что в конце 70-х — начале 80-х годов вылилось в отдельный проект создания первой распределенной системы (проект System R*). Большую роль в исследовании принципов создания и функционирования распределенных баз данных внесли также и разработчики системы Ingres. Собственно в основе распределенных АИС лежат две основные идеи: • много организационно и физически распределенных пользователей, одновременно работающих с общими данными — общей базой данных (пользователи с разными именами, в том числе располагающимися на различных вычислительных установках, с различными полномочиями и задачами); • логически и физически распределенные данные, составляющие и образующие тем не менее единое взаимосогласованное целое — общую базу данных (отдельные таблицы, записи и даже поля могут располагаться на различных вычислительных установках или входить в различные локальные базы данных). Крис Дейт сформулировал также основные принципы создания и функционирования распределенных баз данных. К их числу относятся: • прозрачность расположения данных для пользователя (иначе говоря, для пользователя распределенная база данных должна представляться и выглядеть точно так же, как и нераспределенная); • изолированность пользователей друг от друга (пользователь должен «не чувствовать», «не видеть» работу других пользователей в тот момент, когда он изменяет, обновляет, удаляет данные); • синхронизация и согласованность (непротиворечивость) состояния данных в любой момент времени. Из основных вытекает ряд дополнительных принципов: • локальная автономия (ни одна вычислительная установка для своего успешного функционирования не должна зависеть от любой другой установки); • отсутствие центральной установки (следствие предыдущего пункта); • независимость от местоположения (пользователю все равно где физически находятся данные, он работает так, как будто они находятся на его локальной установке); • непрерывность функционирования (отсутствие плановых отключений системы в целом, например для подключения новой установки или обновления версии СУБД); • независимость от фрагментации данных (как от горизонтальной фрагментации, когда различные группы записей одной таблицы размещены на различных установках или в различных локальных базах, так и от вертикальной фрагментации, когда различные поля-столбцы одной таблицы размещены на разных установках); • независимость от реплицирования (дублирования) данных (когда какая-либо таблица базы данных, или ее часть физически может быть представлена несколькими копиями, расположенными на различных установках, причем «прозрачно» для пользователя); • распределенная обработка запросов (оптимизация запросов должна носить распределенный характер — сначала глобальная оптимизация, а далее локальная оптимизация на каждой из задействованных установок); • распределенное управление транзакциями (в распределенной системе отдельная транзакция может требовать выполнения действий на разных установках, транзакция считается завершенной, если она успешно завершена на всех вовлеченных установках); • независимость от аппаратуры (желательно, чтобы система могла функционировать на установках, включающих компьютеры разных типов); • независимость от типа операционной системы (система должна функционировать вне зависимости от возможного различия ОС на различных вычислительных установках); • независимость от коммуникационной сети (возможность функционирования в разных коммуникационных средах); • независимость от СУБД* (на разных установках могут функционировать СУБД различного типа, на практике ограничиваемые кругом СУБД, поддерживающих SQL). * Данное свойство характеризуют также термином «интероперабельность».
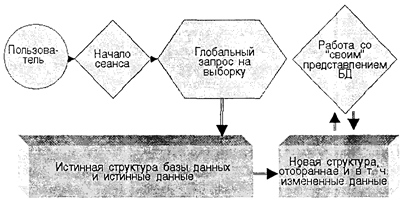
В обиходе СУБД, на основе которых создаются распределенные информационные системы, также характеризуют термином «Распределенные СУБД», и, соответственно, используют термин «Распределенные базы данных». Важнейшую роль в технологии создания и функционирования распределенных баз данных играет техника «представлений» (Views). Представлением называется сохраняемый в базе данных авторизованный глобальный запрос на выборку данных. Авторизованность означает возможность запуска такого запроса только конкретно поименованным в системе пользователем. Глобальность заключается в том, что выборка данных может осуществляться со всей базы данных, в том числе из данных, расположенных на других вычислительных установках. Напомним, что результатом запроса на выборку является набор данных, представляющий временную на сеанс открытого запроса таблицу, с которой (которыми) в дальнейшем можно работать, как с обычными реляционными таблицами данных. В результате таких глобальных авторизованных запросов для конкретного пользователя создается некая виртуальная база данных со своим перечнем таблиц, связей, т. е. со «своей» схемой и со «своими» данными. В принципе, с точки зрения информационных задач, в большинстве случаев пользователю безразлично, где и в каком виде находятся собственно сами данные. Данные должны быть такими и логически организованы таким образом, чтобы можно было решать требуемые информационные задачи и выполнять установленные функции. Схематично идея техники представлений проиллюстрирована на рис. 5.1.
Рис. 5.1. Основная идея техники представлений При входе пользователя в распределенную систему ядро СУБД, идентифицируя пользователя, запускает запросы его ранее определенного и хранимого в базе данных представления и формирует ему «свое» видение базы данных, воспринимаемое пользователем как обычная (локальная) база данных. Так как представление базы данных виртуально, то «настоящие» данные физически находятся там, где они находились до формирования представления. При осуществлении пользователем манипуляций с данными ядро распределенной СУБД по системному каталогу базы данных само определяет, где находятся данные, вырабатывает стратегию действий, т. е. определяет, где, на каких установках целесообразнее производить операции, куда для этого и какие данные необходимо переместить из других установок или локальных баз данных, проверяет выполнение ограничений целостности данных. При этом большая часть таких операций прозрачна (т. е. невидима) для пользователя, и он воспринимает работу в распределенной базе данных, как в обычной локальной базе.
|