Гайдамакин Н. А. 3 страница
Другой важной функцией СУБД является организация и поддержание физической структуры данных во внешней памяти. Эта функция включает организацию и поддержание внутренней структуры файлов базы данных, иногда называемой форматом файлов базы дачных, а также создание и поддержание специальных структур (индексы, страницы) для эффективного и упорядоченного доступа к данным. В этом плане эта функция тесно связана с третьей функцией СУБД — организацией доступа к данным. Организация и поддержание физической структуры данных во внешней памяти может производиться как на основе штатных средств файловых систем, так и на уровне непосредственного управления СУБД устройствами внешней памяти. Организация доступа к данным и их обработка в оперативной и внешней памяти осуществляется через реализацию процессов, получивших название транзакций. Транзакцией называют последовательную совокупность операций, имеющую отдельное смысловое значение по отношению к текущему состоянию базы данных. Так, например, транзакция по удалению отдельной записи в базе данных последовательно включает определение страницы файла данных, содержащей указанную запись, считывание и пересылку соответствующей страницы в буфер оперативной памяти, собственно удаление записи в буфере ОЗУ, проверку ограничений целостности по связям и другим параметрам после удаления и, наконец, «выталкивание» и фиксацию в файле базы данных нового состояния соответствующей страницы данных. Транзакции принято разделять на две разновидности — изменяющие состояние базы данных после завершения транзакции и изменяющие состояние БД лишь временно, с восстановлением исходного состояния данных после завершения транзакции. Совокупность функций СУБД по организации и управлению транзакциями называют монитором транзакций. Транзакции в теории и практике СУБД по отношению к базе данных выступают внешними процессами, отождествляемыми с действиями пользователей банка данных. При этом источником, инициатором транзакций может быть как один пользователь, так и несколько пользователей сразу. По этому критерию СУБД классифицируются на однопользовательские (или так называемые «настольные») и многопользовательские («тяжелые», «промышленные») СУБД. Соответственно в многопользовательских СУБД главной функцией монитора транзакций является обеспечение эффективного совместного выполнения транзакций над общими данными сразу от нескольких пользователей. Непосредственная обработка и доступ к данным в большинстве СУБД осуществляется через организацию в оперативной памяти штатными средствами операционной системы или собственными средствами системы буферов оперативной памяти, куда на время обработки и доступа помещаются отдельные компоненты файла базы данных (страницы). Поэтому другой составной частью функций СУБД по организации доступа и обработки данных является управление буферами оперативной памяти. Еще одной важной функцией СУБД с точки зрения организации доступа и обработки данных является так называемая журнализация всех текущих изменений базы данных. Журнализация представляет собой основное средство обеспечения сохранности данных при всевозможных сбоях и разрушениях данных. Во многих СУБД для нейтрализации подобных угроз создается журнал изменений базы данных с особым режимом хранения и размещения. Вместе с установкой режима периодического сохранения резервной копии БД журнал изменений* при сбоях и разрушениях данных позволяет восстанавливать данные по произведенным изменениям с момента последнего резервирования до момента сбоя. Во многих предметных областях АИС (например, БД с финансово-хозяйственными данными) такие ситуации сбоя и порчи данных являются критическими и возможности восстановления данных обязательны для используемой СУБД. * Резервная копия БД и журнал изменений, как правило, размещаются на отдельных от основного файла БД носителях.
Исходя из рассмотренных функций, в структуре СУБД в современном представлении можно выделить следующие функциональные блоки: • процессор описания и поддержания структуры базы данных; • процессор запросов к базе данных; • монитор транзакций;* • интерфейс ввода данных; • интерфейс запросов; • интерфейс выдачи сведений; • генератор отчетов. * Как правило, в однопользовательских СУБД монитортранзакций в виде отдельного функционального элемента СУБД не реализуется и не выделяется.
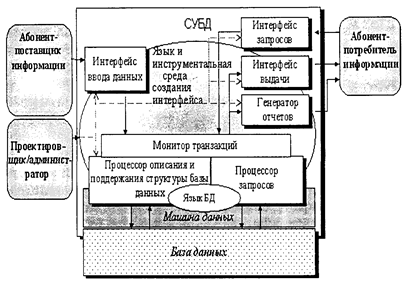
Схематично взаимодействие компонент СУБД представлено на рис. 2.1.
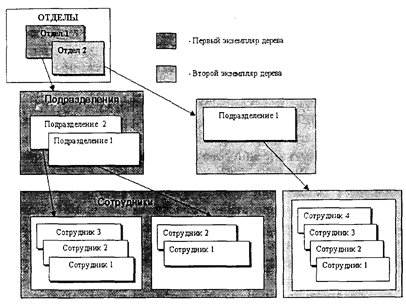
Рис. 2.1. Структура и взаимодействие компонент СУБД ЯдромСУБД является процессор описания и поддержания структуры базы данных. Он реализует модель организации данных, средствами которой проектировщик строит логическую структуру (схему) базы данных, соответствующую инфологической схеме предметной области АИС, и обеспечивает построение и поддержание внутренней схемы базы данных. Процессором описания и поддержания структуры данных в терминах используемой модели данных (иерархическая, сетевая, реляционная) обеспечиваются установки заданной логической структуры базы данных, а также трансляция (перевод) структуры базы данных во внутреннюю схему базы данных (в физические структуры данных). В АИС на базе реляционных СУБД процессор описания и поддержания структуры базы данных реализуется на основе языка базы данных, являющегося составной частью языка структурированных запросов (SQL). Интерфейс ввода данных СУБД реализует входной информационный язык банка данных, обеспечивая абонентам-поставщикам информации средства описания и ввода данных в информационную систему. Одной из современных тенденций развития СУБД является стремление приблизить входные информационные языки и интерфейс ввода к естественному языку общения с пользователем в целях упрощения эксплуатации информационных систем так называемых «неподготовленными» пользователями. Данная проблема решается через применение диалоговых методов организации интерфейса и использование входных форм. Входные формы, по сути, представляют собой электронные аналоги различного рода анкет, стандартизованных бланков и таблиц, широко используемых в делопроизводстве и интуитивно понятных большинству людей (неподготовленных пользователей). Интерфейс ввода при этом обеспечивает средства создания, хранения входных форм и их интерпретацию в терминах описания логической структуры базы данных для передачи вводимых через формы сведений процессору описания и поддержания структуры базы данных. Интерфейс запросов совместно с процессором запросов обеспечивает концептуальную модель использования информационной системы в части стандартных типовых запросов, отражающих информационные потребности пользователей-абонентов системы. Интерфейс запросов предоставляет пользователю средства выражения своих информационных потребностей. Современной тенденцией развития СУБД является использование диалогово-наглядных средств в виде специальных «конструкторов» или пошаговых «мастеров» формирования запросов. Процессор запросов интерпретирует сформированные запросы в терминах языка манипулирования данными и совместно с процессором описания и поддержания структуры базы данных собственно и исполняет запросы. В реляционных СУБД основу процессора запросов составляет язык манипулирования данными, являющийся основной частью языка SQ L. Тем самым на базе процессора запросов и процессора описания и поддержания структуры базы данных образуется низший уровень оперирования данными в СУБД, который иногда называют машиной данных. Стандартные функции и возможности машины данных используют компоненты СУБД более высокого порядка (см. рис. 2.1), что позволяет разделить и стандартизировать компоненты СУБД и банка данных на три уровня —логический уровень, машина данных и собственно сами данные. Функции монитора транзакции, как уже отмечалось, заключаются в организации совместного выполнения транзакций от нескольких пользователей над общими данными. При этом дополнительной функцией, неразрывно связанной, в том числе и с основной функцией, является обеспечение целостности данных и ограничений над данными, определяемыми правилами предметной области АИС. Интерфейс выдачи СУБД получает от процессора запросов результаты исполнения запросов (обращений к базе данных) и переводит эти результаты в форму, удобную для восприятия и выдачи пользователю-абоненту информационной системы. Для отображения результатов исполнения запросов в современных СУБД используются различные приемы, позволяющие «визуализировать» данные в привычной и интуитивно понятной неподготовленному пользователю форме. Обычно для этого применяются табличные способы представления структурированных данных, а также специальные формы выдачи данных, представляющие также, как и формы ввода, электронные аналоги различных стандартизованных бланков и отчетов в делопроизводстве. Формы выдачи лежат также и в основе формирования так называемых «отчетов», выдающих результаты поиска и отбора информации из БД в письменной форме для с формализованного создания соответствующих текстовых документов, т. е. для документирования выводимых данных. Для подобных целей в состав современных СУБД включаются генераторы отчетов. В заключение по структуре и составу СУБД следует также добавить, что современные программные средства, реализующие те или иные СУБД, представляют собой совокупность инструментальной среды создания и использования баз данных в рамках определенной модели данных (реляционной, сетевой, иерархической или смешанной) и языка СУБД (языкописания данных, язык манипулирования данными, язык и средства создания интерфейса). На основе программных средств СУБД проектировщики строят в целях реализации конкретной информационной системы (инфологическая схема предметной области, задачи и модель использования, категории пользователей и т. д.) автоматизированный банк данных, функционирование которого в дальнейшем поддерживают администраторы системы и услугами которого пользуются абоненты системы. 2.2. Модели организации данных 2.2.1. Иерархическая и сетевая модели организации данных В иерархической модели объекты-сущности и отношения предметной области представляются наборами данных, которые имеют строго древовидную структуру, т. е. допускают только иерархические (структурные) связи-отношения. Иерархическая модель данных была исторически первой, на основе которой в конце 60-х-начале 70-х годов были разработаны первые профессиональные СУБД-СУБД IMS (Information Management System) фирмы IBM, СУБД Total для компьютеров НР3000. К иерархическим СУБД также относятся отечественные промышленные СУБД 70-80-х годов «ОКА» и «ИНЭС». База данных с иерархической моделью данных состоит из упорядоченного набора экземпляров структуры типа «дерево», что иллюстрируется примером на рис. 2.2. В приведенном примере информационный объект «Отделы» является предком информационного объекта «Подразделения», который, в свою очередь, является предком информационного объекта «Сотрудники». Объект «Подразделения» является потомком объекта «Отделы», а объект «Сотрудники» потомком объекта «Подразделения». Экземпляры потомка с общим предком называются близнецами.
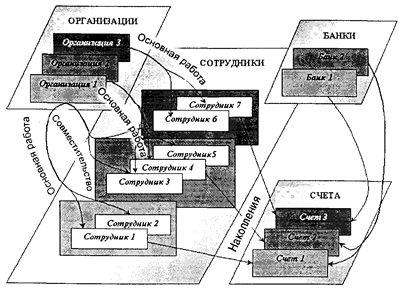
Рис. 2.2. Пример иерархической организации данных В иерархической модели устанавливается строгий порядок обхода дерева (сверху-вниз, слева-направо) и следующие операции над данными: • найти указанное дерево (например, отдел № 3); • перейти от одного дерева к другому; • перейти от одной записи к другой (например, от отдела к первому подразделению); • перейти от одной записи к другой в порядке обхода иерархии; • удалить текущую запись. Основное внимание в ограничениях целостности в иерархической модели уделяется целостности ссылок между предками и потомками с учетом основного правила: никакой потомок не может существовать без родителя. Сетевая модель является расширением иерархической и широко применялась в 70-е годы в первых СУБД, использовавшихся крупными корпорациями для создания информационных систем (СУБД IDMS — Integrated Database Management System компании Cullinet Software Inc., СУБД IDS, отечественные СУБД «СЕТЬ», «БАНК», «СЕТОР»). Одним из идеологов концепции сетевой модели являлся Ч. Бахман. Эталонный вариант сетевой модели данных, разработанный с участием Бахмана, был описан в проекте «Рабочей группы по базам данных» КОДАСИЛ (DBTG CODASY L). В отличие от иерархической, в сетевой модели объект-потомок может иметь не одного, а вообще говоря, любое количество объектов-предков. Тем самым допускаются любые связи-отношения, в том числе и одноуровневые. В результате сущности и отношения предметной области АИС представляются графом любого (не только древовидного) типа. Пример такой организации данных приведен на рис. 2.3.
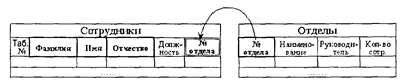
Рис. 2.3. Пример сетевой организации данных Сетевая СУБД состоит из одного или нескольких типов записей (типов информационных объектов) и набора типов связей между ними. Каждый тип записей представлен в БД набором экземпляров записей данного типа. Аналогично каждый тип связи представлен набором экземпляров связей данного типа между конкретными экземплярами типов записей. В приведенном на рис. 2.3 примере типами записей являются «Организация», «Сотрудник», «Банк», «Счет», а типами связей — «Совместительство», «Основная работа», «Вклады», «Накопления». При этом тип записи «Счет» имеет двух предков — «Сотрудник» и «Банк», экземпляр типа записи «Сотрудник» может иметь два предка (по связям «Основная работа» и «Совместительство»), являющихся различными экземплярами типа записи «Организация». Для данного типа связи L между типом записи предка Р и типом записи потомка С выполняются следующие условия: • каждый экземпляр типа Р является предком только в одном экземпляре L, • каждый экземпляр С является потомком не более чем в одном экземпляре L. В рамках сетевой модели возможны следующие ситуации: • тип записи потомка в одном типе связи L 1 может быть типом записи предка в другом типе связи L 2 (как в иерархической модели); • данный тип записи Р может быть типом записи потомка в любом числе типов связи; • может существовать любое число типов связи с одним и тем же типом записи предка и одним и тем же типом записи потомка; • если L 1 и L 2 —два типа связи с одним и тем же типом записи предка Р и одним и тем же типом записи потомкаС, то правила, по которым образуется родство, в разных связях могут различаться; • типы записей Х и Y могут быть предком и потомком одной связи и потомком и предком в другой; предок и потомок могут быть одного типа записи (связь типа «петля»). В сетевой модели устанавливаются следующие операции над данными: • найти конкретную запись (экземпляр) в наборе однотипных записей; • перейти от предка к первому потомку по некоторой связи; • перейти к следующему потомку по некоторой связи; • создать новую запись; • уничтожить запись; • модифицировать запись; • включить в связь; • исключить из связи; • переставить в другую связь. Реализация связей и сведений по ним в виде отдельных записей в БД обеспечивает одну важную отличительную особенность сетевых СУБД - навигацию по связанным данным. Сетевые СУБД обеспечивают возможность непосредственной «навигации» (перехода) от просмотра реквизитов экземпляра одного типа записи (например, «Организация») к просмотру реквизитов экземпляра связанного типа записей (например, «Сотрудник»). Тем самым пользователю предоставляется возможность многокритериального анализа базы данных без непосредственной формализации своих информационных потребностей через формирование запросов на специальном языке, встроенном в СУБД. Поэтому СУБД с сетевой организацией данных иногда еще называют СУБД с навигацией. Другой сильной стороной сетевой модели в немногих примерах современной реализации сетевых СУБД является также использование множественных типов данных для описания атрибутов информационных объектов (записей), что позволяет создавать информационные структуры, которые хорошо отражают традиционную табличную форму представления структурированных данных. К примеру, при описании типа записи «Сотрудник» в сетевой модели можно ввести реквизит «Имена детей», характер значений которого является множественным. Сетевая модель позволяет наиболее адекватно отражать инфологические схемы сложных предметных областей. Вместе с тем, несмотря на появление в конце 70-х годов стандарта по сетевой модели данных КОДАСИЛ, не получила широкого распространения ни одна из попыток создания языковых программных средств, которые позволили бы в разных прикладных информационных системах одинаковым образом описывать данные с сетевой организацией. В результате в сетевых СУБД данные оставались жестко связанными как с самой СУБД, так и с прикладными компонентами АИС, что затрудняло специализацию в развитии программных компонент СУБД сетевого типа и объективно затормаживало процесс их развития. 2.2.2. Реляционная модель организации данных В реляционной модели объекты-сущности инфологической схемы предметной области АИС представляются плоскими таблицами данных. Столбцы таблицы, называемые полями базы данных, соответствуют атрибутам объектов-сущностей инфологической схемы предметной области. Множество атомарных значений атрибута называется доменом. Так доменом для поля «Имя» является множество всех возможных имен. Различные атрибуты могут быть определены на одном и том же домене — например, атрибуты «Год поступления» (в вуз) и «Год окончания» определены на одном и том же домене, являющемся перечнем дат определенного диапазона. Строки таблицы, представляющие собой различные сочетания значений полей из доменов, называются кортежами (в обиходе просто записями) базы данных и соответствуют экземплярам объектов-сущностей инфологической схемы предметной области. Считается, что сильной стороной реляционных баз данных является развитая математическая теория, лежащая в их основе—реляционная алгебра. Само слово «реляционная» происходит от англ. relation — отношение. Но в случае реляционных баз слово «отношение» выражает не взаимосвязь между таблицами-сущностями, а определение самой таблицы как математического отношения доменов.* * Для любителей математики— отношением называется подмножество декартова произведения множеств, роль которых в данном случае играют домены, таким образом таблицы — это отношение доменов, а строки таблицы (кортежи) — элементы отношения доменов. Ключевому атрибуту объекта-сущности, который идентифицирует (определяет, отличает от других) конкретный экземпляр объекта, в таблице соответствует ключевое поле (так называемый ключ таблицы). Примером ключа в таблице «Отделы» может быть поле «Номер отдела» или поле «Наименование отдела». В тех случаях, когда конкретную запись таблицы идентифицирует значение не одного поля, а совокупность значений нескольких полей, тогда все эти поля считаются ключевыми, а ключ таблицы является составным. Примером такой ситуации может служить таблица «Сотрудники», роль составного ключа в которой может играть совокупность полей «Фамилия», «Имя», «Отчество».* * В той ситуации, когда исключается полное совпадение фамилии, имени и отчества у разных сотрудников.
Ключевое поле для созданной записи (заполненной строки таблицы) впоследствии обновиться (изменить значение) уже не может. В некоторых таблицах роль ключа могут играть сразу несколько полей или групп полей. Например, в той же таблице «Сотрудники» может быть определен второй ключ «Номер паспорта», который также может идентифицировать конкретную запись (экземпляр) объекта «Сотрудник». В этих случаях один из ключей объявляется первичным. Значения непервичных ключей, которые называются возможными, в отличие от первичных ключей могут обновляться. Совокупность определенных для таблицы-отношения полей, их свойства (ключи и пр.) составляют схему таблицы-отношения. Две отдельные таблицы-отношения с одинаковой схемой называются односхемными. Как уже отмечалось, таблица в реляционной модели отражает определенный объект-сущность из мифологической схемы предметной области АИС. Отношения-связи объектов-сущностей в реляционной модели устанавливаются через введение в таблицах дополнительных полей, которые дублируют ключевые поля связанной таблицы. К примеру, связь между таблицей «Сотрудники» и таблицей «Отделы» устанавливается через введение копии ключевого поля «Номер отдела» из таблицы «Отделы» в таблицу «Сотрудники» — см. рис. 2.4. Такие поля, дублирующие ключи связанной таблицы, называются внешними ключами.
Рис. 2.4. Пример связи в реляционных таблицах На приведенном рисунке ключевые поля таблиц обведены жирными рамками, а поле с внешним ключом — двойной рамкой. Так как значения первичного ключа уникальны, т. е. не могут повторяться (в таблице «Отделы» может быть только один кортеж по, к примеру, 710-му отделу), а значения других полей и, в частности, внешнего ключа могут повторяться (в таблице «Сотрудники» может быть несколько строк-кортежей сотрудников по 710-му отделу), то такой механизм автоматически обеспечивает связь типа «Один-ко-многим». Отсюда также можно заключить, что связи между таблицами типа «Один-к-одному» в реляционной модели автоматически обеспечиваются при одинаковых первичных ключах, например между таблицей «Сотрудник» с ключом «Таб_№» и таблицей «Паспорт» с таким же ключом. Другой вывод, который следует из анализа данного механизма реализации связей, заключается в том, что реляционная модель не может непосредственно отражать связи типа «Многие-ко-многим», что объективно снижает возможности реляционной модели данных при отражении сложных предметных областей. Таким образом, структурная составляющая реляционной модели определяется небольшим набором базовых понятий — таблица-отношение, схема таблицы-отношения, домен, поле-атрибут, кортеж-запись (строка), ключ, первичный ключ, вторичный ключ, внешний ключ (отсылка). Данный набор понятий позволяет описывать естественным образом, близким к понятийному аппарату диаграмм Бахмана, большинство инфологических схем не слишком сложных предметных областей. Это обстоятельство как раз и способствовало интенсивному развитию реляционных СУБД в 80-х-90-х годах. Ограничения целостности (целостная составляющая) реляционной модели можно разделить на две группы — требование целостности сущностей и требование целостности ссылок. Требование целостности сущностей в общем плане заключается в требовании уникальности экземпляров объектов инфологической схемы, отображаемых средствами реляционной модели. Экземплярам объектов инфологической схемы в реляционной модели соответствуют кортежи-записи таблиц-отношений. Поэтому требование целостности сущностей заключается в требовании уникальности каждого кортежа. Отсюда вытекают следующие ограничения: • отсутствие кортежей дубликатов (данное требование реализуется не через требование отсутствия совпадения значений одновременно по всем полям, а лишь по полям первичных ключей, что обеспечивает определенную гибкость в описании конкретных ситуаций в предметных областях АИС); • отсутствие полей с множественным характером значений атрибута (данное ограничение по отношению к весьма типичным ситуациям при описании реальных предметных областей в реляционной модели обеспечивается так называемой нормализацией таблиц-отношений, т.е. разбиением исходной таблицы на две или более связанные таблицы с единичным характером значений полей-атрибутов). Требование целостности ссылок заключается в том, что для любого кортежа-записи с конкретным значением внешнего ключа (отсылки) должен обязательно существовать кортеж связанной таблицы-отношения с соответствующим значением первичного ключа. Простым примером этого очевидного требования является таблица-отношение «Сотрудники» с внешним ключом «№ отдела» и отсылаемая (связанная) таблица «Отделы» с первичным ключом «№ отдела» (см. рис. 2.4). Если существует кортеж-запись «Иванов», работающий в отделе № 710, то в таблице «Отделы» обязательно должен быть кортеж-запись с соответствующим номером отдела (каждый сотрудник должен обязательно в каком-либо отделе хотя бы числиться). Теоретико-множественный характер реляционных таблиц-отношений требует также отсутствия упорядоченности кортежей и отсутствия упорядоченности полей-атрибутов. Отсутствие упорядоченности записей-кортежей в таблицах-отношениях усложняет поиск нужных кортежей при обработке таблиц. На практике с целью создания условий для быстрого нахождения нужной записи таблицы без постоянного упорядочения (переупорядочения) записей при любых изменениях данных вводят индексирование полей (обычно ключевых). Индексирование полей, или лучше сказать создание индексных массивов, является типовой распространенной операцией практически во всех СУБД, поддерживающих и другие, не реляционные модели данных, и заключается в построении дополнительной упорядоченной информационной структуры для быстрого доступа к записям-кортежам. Все операции над данными в реляционной модели (манипуляционная составляющая) можно разделить на две труппы — операции обновления таблиц-отношений и операции обработки таблиц-отношений. К операциям обновления относятся: • операция ВКЛЮЧИТЬ —добавляет новый кортеж (строку-запись) в таблицу-отношение. Требует задания имени таблицы и обязательного значения ключей. Выполняется при условии уникальности значения ключа. Добавить новую строку-запись со значением ключа, которое уже есть в таблице, невозможно; • операция УДАЛИТЬ — удаляет одну или группу кортежей (строк-записей). Требует задания имени таблицы, имени поля (группы полей) и параметров значений полей, кортежи с которыми должны быть удалены; • операция ОБНОВИТЬ — изменяет значение не ключевых полей у одного или группы кортежей. Требует задания имени таблицы-отношения, имен полей и их значений для выбора кортежей и имен изменяемых полей. Особенностью операций обработки в реляционной модели по сравнению с иерархической и сетевой моделью является то, что в качестве единичного элемента обработки выступает не запись (экземпляр объекта), а таблица в целом, т. е. множество кортежей (строк-записей). Поэтому все операции обновления являются операциями над множествами и их результатом является также множество, т. е. новая таблица-отношение. К операциям обновления относятся следующие операции: • операция ОБЪЕДИНЕНИЕ — выполняется над двумя односхемными таблицами-отношениями. Результатом объединения является построенная по той же схеме таблица-отношение, содержащая все кортежи первой таблицы-отношения и все кортежи второй таблицы-отношения. При этом кортежи-дубликаты в итоговой таблице устраняются; • операция ПЕРЕСЕЧЕНИЕ — выполняется также над двумя односхемными таблицами-отношениями. Результатом является таблица-отношение, построенная по той же схеме и содержащая только те кортежи первой таблицы-отношения, которые входят также в состав кортежей второй таблицы-отношения. Для примера рассмотрим таблицу «Сотрудники» со схемой (полями) «ФИО», «Год рождения», «Национальность» и таблицу «Вкладчики банка «НАДЕЖНЫЙ» с той же схемой. Результатом их пересечения будет новая таблица с той же схемой, содержащая кортежи только тех сотрудников, которые имеют вклады в банке «НАДЕЖНЫЙ», что иллюстрируется примером, приведенным на рис. 2.5; • операция ВЫЧИТАНИЕ — выполняется также над двумя односхемными таблицами-отношениями. Результатом является таблица-отношение, построенная по той же схеме и содержащая только те кортежи первой таблицы-отношения, которых нет в составе кортежей второй таблицы-отношения. Результатом операции вычитания над таблицами в предыдущем примере будет новая таблица стой же схемой, содержащая кортежи только тех сотрудников, которые не имеют вкладов в банке «НАДЕЖНЫЙ»;
|