Демонстрационные примеры 2 страница
Построение графиков пи-подобной, трапециевидной, треугольной и сигмоидной функций принадлежности на интервале [0, 10].
В оглавление \ К следующему разделу \ К предыдущему разделу
Синтаксис: [V, M, obj_fcn] = fcm(X, c) [V, M, obj_fcn] = fcm(X, c, options) Описание: На основе нечеткого c-means алгоритма выполняет кластеризацию данных. Этот алгоритм кластеризации предложил Джеймс Бэздэк (James Bezdek) в 1981 году. Задача нечеткой кластеризации ставится следующим образом. Дано:
Необходимо каждому элементу множества X поставить в соответствие степени принадлежности с классам. Элементы одного кластера должны быть так близки каждый каждому, как это только возможно, и, одновременно, кластеры должны быть на наибольшем удалении друг от друга. Для обеспечения управляемости процесса кластеризации необходимо использовать меру близости, в качестве которой обычно определяют расстояние между двумя объектами (точками в p-мерном пространстве)
Дополнительно, если функция Любое разбиение множества Обозначим через
В отличие от четкого, при нечетком c-разбиении любой объект одновременно принадлежит к различным кластерам, но с разной степенью. Условия (2) и (3) требуют только, чтобы сумма степеней принадлежности объекта ко всем кластерам была нормализована к 1, а также, чтобы количество кластеров, к которым принадлежит объект, не превышало Обозначим центры кластеров, т. е. точки в p-мерном пространстве, вокруг которых сконцентрированы соответствующие объекты, через При использовании эвклидового расстояния задача нечеткой кластеризации состоит в нахождении такой матрицы степеней принадлежности
где Значение экспоненциального веса устанавливается до начала кластеризации. Экспоненциальный вес Аналитического решения задачи нахождения оптимальных координат центров кластеров и матрицы степеней принадлежности не существует, поэтому она решается численно. Один из итерационных алгоритмов решения этой задачи реализован в функции fcm. Функция fcm может иметь три входных аргумента:
options(1) – значения экспоненциального веса (значение по умолчанию – 2.0); Алгоритм кластеризации останавливается когда выполнено максимальное количество итераций или когда улучшение значения целевой функции за одну итерацию меньше указанного минимально допустимого значения. Функция fcm имеет три выходных аргумента:
Примечание: при описании нечеткого c-means алгоритма использована книга Zimmermann H.-J. Fuzzy Set Theory - and Its Applications.3rd ed.- Kluwer Academic Publishers, 1996.- 435p. Пример. Проводится кластеризация объектов, образующих фигуру типа “бабочка”. Результаты кластеризации приведены ниже на рисунке. Центры кластеров указаны маркером ‘+’. Размер маркера ‘o’ пропорционален степени принадлежности объекта кластеру. Расположенный в центре объект имеет одинаковые степени принадлежности к красному и к синему кластерам. Это обеспечивает симметричное разбиение объектов по кластерам, что невозможно при четкой кластеризации. X=[1 1; 1 4; 1 7; 3 2; 3 4; 3 6; 5 4; 7 4; 9 4; 11 2; 11 4; 11 6; 13 1; 13 4; 13 7];
В оглавление \ К следующему разделу \ К предыдущему разделу
Синтаксис: rownum = findrow (str, strmat) Описание: Функция findrow возвращаетномер строки матрицы strmat, содержащую стринг, заданный аргументом str. Если таких строк несколько, то функция findrow возвратит номера всех строчек. Функция findrow не связана с нечеткими множествами и нечеткой логикой, она используются для выполнения алгоритмов обработки информации, необходимых для других функций Fuzzy Logic Toolbox. Пример: rownum = findrow('два ', ['один'; 'два '; 'три ']) =================================================================== Функция возвращает значения 2, которое означает, что стринг 'два ' содержится во второй строке матрицы ['один'; 'два '; 'три ']. В оглавление \ К следующему разделу \ К предыдущему разделу
Синтаксис: aout = fstrvcat(a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11) Описание: Функция fstrvcat формирует матрицу aout, строки которой содержат вектора a1, a2, a3, …. Для того, чтобы сформировать корректную матрицу, к некоторым векторам добавляется необходимое количество нулевых символов. Количество входных аргументов не должно превышать 11. Входные аргументы функции fstrvcat могут быть заданы как векторами, так и матрицами. Это позволяет формировать выходную матрицу aout пратически любого размера. Функция fstrvcat не связана с нечеткими множествами и нечеткой логикой, она используются для выполнения алгоритмов обработки информации, необходимых для формирования fis-структуры. Пример: aout = fstrvcat ('hi', 'blue', [110 101 101 100 108 101]) =================================================================== Функция fstrvcat возвращает следующую матрицу: aout = строки которой содержат значения входных аргументов в формате ASCII. В оглавление \ К следующему разделу \ К предыдущему разделу
Синтаксис: c = fuzarith(x, a, b, operator) Описание: Выполняет арифметические операции сложения, вычитания, умножения и деления над нечеткими числами. Функция fuzarith имеет четыре входных аргумента:
Выходной переменной функции fuzarith является вектор степеней принадлежности элементов универсального множества x результату выполнения нечеткой арифметической операции. Размерности векторов x, a, b и c должны быть одинаковыми. В функции fuzarith нечеткие арифметические выполняются по следующему алгоритму:
Функция fuzarith использует стандартные процедуры интерполяции для выполнения указанных выше преобразований. Количество Обратим внимание на то, что операция деления не может быть выполнена если универсальное множество содержит как отрицательные, так и положительные числа, что связано с делением на ноль. При выполнении арифметически операций над нечеткими числами, как правило, носитель результирующего нечеткого числа отличен от носителей нечетких операндов. Функция fuzarith выводит степени принадлежности результата только для универсального множества нечетких операндов, т.е. для множества x. Для вывода всего результирующего нечеткого числа необходима простая модификация функции fuzarith – вывод результата в виде нечеткого множества в Пример: Рассчитывается нечеткое число c как произведение нечетких чисел a и b с гауссовскими функциями принадлежности, заданных на универсальном множестве {0, 0.01, …, 1}. Графики функций принадлежности показаны ниже на рисунке. x=0:0.01:1;
В оглавление \ К следующему разделу \ К предыдущему разделу
Синтаксис: y = gauss2mf (x, params) Описание: Функция принадлежности в виде следующей комбинации двух гауссовских функций принадлежности: если c1<c2, то если c1>c2, то Если c1<c2, то параметры функции принадлежности геометрически интерпретируются следующим образом: с1 (с2) – минимальное (максимальное) значение ядра нечеткого множества; Когда c1>c2, нечеткое множество получается субнормальным. Функция gauss2mf применяется для задания гладних ассиметричных функций принадлежности. Функция gauss2mf имеет два входных аргумента:
Функция gauss2mf возвращает выходной аргумент y, содержащий степени принадлежности координат вектора x. Пример: x = 0: 0.1: 10; =================================================================== Построение графиков двухсторонних гауссовских функций принадлежности с различными параметрами на интервале [0, 10].
В оглавление \ К следующему разделу \ К предыдущему разделу
Синтаксис: y = gaussmf (x, params) Описание: Функция gaussmf задает функцию принадлежности в виде симметричной гауссовской кривой. Эта функция задается формулой b – координата максимума функции принадлежности; Функция gaussmf применяется для задания гладних симетричных функций принадлежности. Функция gaussmf имеет два входных аргумента:
Функция gaussmf возвращает выходной аргумент y, содержащий степени принадлежности координат вектора x. Пример: x = 0: 0.1: 10; =================================================================== Построение графиков симметричных гауссовских функций принадлежности с различными коэффициентами концентрации.
В оглавление \ К следующему разделу \ К предыдущему разделу
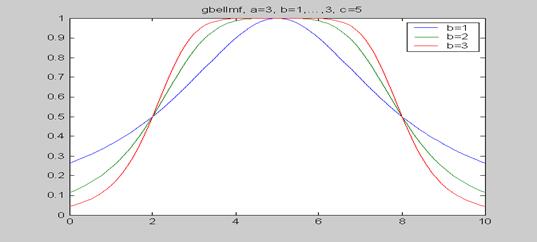
Синтаксис: y = gbellmf (x, params) Описание: Функция gbellmf задает функцию принадлежности в виде симметричной кривой в форме колокола. Эта функция задается формулой a - коэффициент концентрации функции принадлежности; Функция gbellmf применяется для задания гладних симетричных функций принадлежности. Функция gbellmf имеет два входных аргумента:
Функция gbellmf возвращает выходной аргумент y, содержащий степени принадлежности координат вектора x. Пример: x = 0: 0.1: 10; =================================================================== Построение графиков колокообразных функций принадлежности с различными коэффициентами крутизны.
В оглавление \ К следующему разделу \ К предыдущему разделу
Синтаксис: fis = genfis1(data, numMFs, inmftype, outmftype) Описание: Функция genfis1 генерирует из данных систему нечеткого логического вывода типа Сугэно. Функции принадлежностей входных переменных выбираются таким образом, чтобы термы равномерно распределялись внутри диапазона изменения данных. Количество правил базы знаний определяется как произведение мощностей терм-множеств входных переменных, другими словами, функция genfis1 генерирует все возможные правила. Коэффициенты линейного полинома, который связывает входные и выходную переменные в области действия правила, назначаются равными нулю. Это означает, что при любых значениях входных переменных на выходе системы будет нулевое значение. Полученная система нечеткого логического вывода не отражает представленные данными закономерности между входами и выходом. Она является исходной системой для обучения посредством технологии ANFIS, в результате которого закономерности, заложенные в данных, будут идентифицированы. Функция genfis1 может имеет до четырех входных аргументов:
Функция genfis1 возвращает выходной аргумент fis, содержащий систему нечеткого логического вывода типа Сугэно. Пример: data = [rand(10,1) 10*rand(10,1)-5 rand(10,1)]; =================================================================== Генерирование системы нечеткого логического вывода из данных data. Система использует три терма с пи-подобными функция принадлежности для оценки первой входной переменной и семь термов с треугольными функциями принадлежности для оценки второй входной переменной. В оглавление \ К следующему разделу \ К предыдущему разделу
Синтаксис: fis = genfis2(Xin, Xout, radii, xBounds, options) Описание: Функция genfis2 генерирует систему нечеткого логического вывода типа Сугэно из данны с использованием субтрактивной кластеризации. При использовании данных только с одной выходной переменной, результат выполнения функции genfis2 может рассматриваться как исходная система для обучения посредством технологии ANFIS. Экстракция правил из данных в функции genfis2 происходит в два этапа. Вначале используется функция subclust для определения количества правил и мощностей терм-множеств выходных переменных. Затем с помощью метода наименьших квадратов определяется "то-"часть каждого правила. В результате этого получается система нечеткого логического вывода с базой правил, покрывающих все предметную область. Функция genfis2 может иметь до пяти входных аргументов, первые три из которых обязательны:
options – вектор параметров кластерного анализа, информация о которых приведена в описании функции subclust. Пример: x=2*rand(100,2); =================================================================== В первых двух строчка примера задаются 100 пар точек “входы-выход”, связанных зависимостью y=x1^2+2*x2. Затем генерируется система нечеткого логического вывода, которая идентифицирует представленную данными зависимость. На рисунке показано желаемое (сплошная линия) и действительное (красные точки) поведения нечеткой модели. Как видно из рисунка, даже без использования технологии обучения ANFIS, нечеткая модель, синтезированная функцией genfis2, хорошо описывает данные.
В оглавление \ К следующему разделу \ К предыдущему разделу
Синтаксис: mf_param = genparam(data, mf_n, mf_type) Описание: Функция genparam генерирует параметры функций принадлежности таким образом, чтобы центры функций принадлежностей располагались через равные промежутки внутри интервалов изменения данных. Функция genparam может имеет три входных аргумента, первый из которых обязательный:
|

 – объекты, подлежащие кластеризации (n – количество объектов). Каждый объект
– объекты, подлежащие кластеризации (n – количество объектов). Каждый объект  представляет собой точку в p-мерном пространстве признаков (
представляет собой точку в p-мерном пространстве признаков ( );
);  ).
). 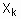 и
и  в виде вещественной функции
в виде вещественной функции  , такой что:
, такой что: ;
; ;
; .
.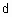 удовлетворяет правилу треугольника, т. е.
удовлетворяет правилу треугольника, т. е. 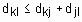 , тогда эта функция является метрикой, хотя выполнения этого свойства не всегда необходимо для задач кластеризации.
, тогда эта функция является метрикой, хотя выполнения этого свойства не всегда необходимо для задач кластеризации. (
( ) может быть полностью описано функцией принадлежности
) может быть полностью описано функцией принадлежности 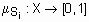 .
. - степень принадлежности объекта
- степень принадлежности объекта  , и через
, и через  - множество всех действительных матриц размером
- множество всех действительных матриц размером  . Тогда нечетким c-разбиением (или матрицей степеней принадлежности) называется матрица
. Тогда нечетким c-разбиением (или матрицей степеней принадлежности) называется матрица  при выполнении следующих условий:
при выполнении следующих условий: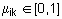 ,
,  ,
, 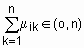 ,
,  .
. ,
, 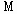 и таких координат центров кластеров
и таких координат центров кластеров  , которые обеспечивают минимум следующего критерия:
, которые обеспечивают минимум следующего критерия: ,
, - центр i-го кластера,
- центр i-го кластера,  - так называемый экспоненциальный вес (
- так называемый экспоненциальный вес ( ).
). она примет вид
она примет вид  , что является очень плохим решением, т. к. все объекты принадлежат ко всем кластерам с одной и той же степенью. Также, экспоненциальный вес позволяет при формировании координат центров кластеров усилить влияние объектов с большими значениями степеней принадлежности и уменьшить влияние объектов с малыми значениями степеней принадлежности. На сегодня не существует теоретически обоснованного правила выбора значения
, что является очень плохим решением, т. к. все объекты принадлежат ко всем кластерам с одной и той же степенью. Также, экспоненциальный вес позволяет при формировании координат центров кластеров усилить влияние объектов с большими значениями степеней принадлежности и уменьшить влияние объектов с малыми значениями степеней принадлежности. На сегодня не существует теоретически обоснованного правила выбора значения  .
.
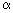 -уровневые нечеткие множества;
-уровневые нечеткие множества;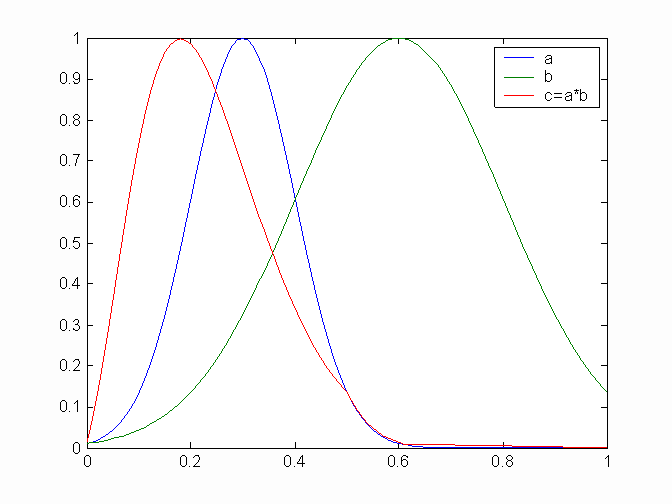
 ;
;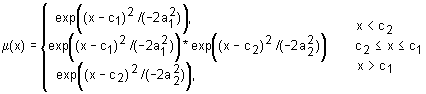 .
.
 , параметры которой геометрически интерпретируются следующим образом:
, параметры которой геометрически интерпретируются следующим образом:
 , параметры которой геометрически интерпретируются следующим образом:
, параметры которой геометрически интерпретируются следующим образом: