
Опис реалізації
На паралельних системах стандарт MPI реалізований для мови С++ і Fortran. Наступна програма на мові С ілюструє обчислення числа π за формулою
Перший рядок програми підключає стандартну бібліотеку введення-виведення мови С; у другому рядку підключається бібліотека mpi.h, що реалізує стандарт MPI для С, рядки з четвертого по сьомий містять визначення функції, що інтегрується, а з 9 по 31 – визначення функції main, яка і виконує всю необхідну роботу. В 11-му рядку описуються дійсні змінні, в 12-му – цілі. Рядки 13-15 використовуються для виклику процедур MPI. Процедура MPI_Init(&argc, &argv) ініціалізує бібліотеку MPI, параметри, що їй передаються, служать для вибірки із аргументів командного рядка тих, які відносяться до бібліотеки MPI. Процедура MPI_Comm_rank(MPI_COMM_WORLD, &myrank) визначає номер процесу (він присвоюється змінній myrank) в групі з комунікатором MPI_COMM_WORLD. Цей комунікатор визначає групу всіх процесорів, запущених для розв’язання даної задачі. Процеси в будь-якій групі нумеруються цілими числами від 0 до (число процесорів) – 1. Процедура MPI_Comm_size(MPI_COMM_WORLD, &nprocs) дозволяє визначити число процесів в групі з комунікатором MPI_COM_WORLD (це число присвоюється вихідному параметру nprocs). Воно визначається при запуску програми на виконання за допомогою опції –np і не повинно перевищувати наявного в системі числа процесорів. В рядках 16-20 ініціюється введення числа n доданків в сумі з процесу з номером 0 (нагадаємо, що в MPI привілейованого процесу на існує: роль кореневого може виконувати будь-який процес за бажанням користувача). В рядку 21 працює процедура MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD), яка здійснює розсилку інформації (в даному випадку, числа n) з кореневого процесорами (тобто процесора з номером 0) за всіма процесами групи з комунікатором MPI_COMM_WORLD; тут перший параметр – покажчик на значення, що розсилаються (в даному випадку розсилається число n), другий параметр – кількість значень, що розсилаються (в даному випадку їх кількість дорівнює 1 або розсилається одне число n), третій параметр означає тип значення, що розсилається (тут повинен використовуватися тип, визначений в стандарті MPI: в нашому випадку це MPI_INT; тип повинен бути вказаний, оскільки він визначає розмір відповідного елемента даних і дозволяє правильно пересилати дані вказаного типу між комп’ютерами, які використовують різні представлення для елементарних типів даних), четвертий параметр – номер процесу, що розсилається (в нашому випадку 0), п’ятий параметр – ім’я комунікатора групи (оскільки в даному випадку використовується лише вихідна група паралельних процесів, то тут повинно стояти ім’я вихідного комунікатора, а саме MPI_COMM_WORLD). В 22-му рядку знаходиться число h за формулою h =(b-a)/n. Далі (рядки 23, 24) кожний процес обчислює частину суми, вибираючи доданки, номери яких порівняні за модулем nprocs з його номером (нагадаємо, що nproc – загальне число процесів). В 25-му рядку отримана процесом сума множиться на 4h, таке множення дозволяє своєчасно «нормалізувати» результат обчислень в даному процесі з тим, щоб за можливості він знаходився в середині діапазону чисел з плаваючою комою. В кожному процесі результат отримується в змінній term, що належить йому. Рядок 26 призначений для додавання (отриманих процесами значень змінних з іменем term) частин суми за допомогою процедури MPI_Reduce(&term, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD), де перший параметр представляє собою адресу змінних, що обробляються (в нашому випадку адреса term), другий параметр є адресою змінної, якій присвоюється результат обробки (адреса змінної рі), операція обробки – додавання, рі – ім’я змінної, третій параметр – число даних, що передаються, з кожного процесу (передається по одному даному – по доданку term), четвертий параметр визначає тип даних, що піддаються обробки (у даному випадку MPI_DOUBLE), п’ятий параметр визначає операцію обробки даних (операція додавання, ідентифікована константою MPI_SUM), шостий параметр вказує номер процесу, в якому зберігається результат обробки (в даному випадку вказаний процес з номером 0), сьомий параметр вказує ім’я комунікатора (MPI_COMM_WORLD). Рядки 27-28 містять виведення отриманого значення π. Рядок 29 містить виклик функції MPI_Finalize(), чим завжди завершується робота з бібліотекою MPI, і рядки 30, 31 містять стандартне завершення функції main. ІІ. Практична частина
|
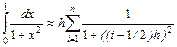 .
.



