
Циклические коды
Циклические коды [4, 6, 7, 9, 12, 13] названы так потому, что в них часть комбинаций кода либо все комбинации могут быть получены путем циклического сдвига одной или нескольких комбинаций кода. Циклический сдвиг осуществляется справа налево, причем крайний левый символ каждый раз переносится в конец комбинации. Циклические коды, практически[13], все относятся к систематическим кодам, в них контрольные и информационные разряды расположены на строго определенных местах. Кроме того, циклические коды относятся к числу блочных кодов. Каждый блок (одна буква является частным случаем блока) кодируется самостоятельно. Идея построения циклических кодов базируется на использовании неприводимых в поле[14] двоичных чисел многочленов. Неприводимыми называются многочлены, которые не могут быть представлены в виде произведения многочленов низших степеней с коэффициентами из того же поля, так же, как простые числа не могут быть представлены произведением других чисел. Иными словами, неприводимые многочлены делятся без остатка только на себя или на единицу. Неприводимые многочлены в теории циклических кодов играют роль образующих (генераторных, производящих) многочленов. Если заданную кодовую комбинацию умножить на выбранный неприводимый многочлен, то получим циклический код, корректирующие способности которого определяются неприводимым многочленом. Предположим, требуйся закодировать одну из комбинаций четырехзначного двоичного кода. Предположим также, что эта комбинация -
Это делается для того, чтобы впоследствии на месте этих нулей можно было бы записать корректирующие разряды. Значение корректирующих разрядов находят по результатуотделения на
или
Таким образом,
или в общем виде
где Так как в двоичной арифметике Таким образом, выражение (75) можно записать как
что в случае нашего примера даст
или
Многочлен 1101001 и есть искомая комбинация, где 1101 - информационная часть, а 001 - контрольные символы. Заметим, что искомую комбинацию мы получили бы и как в результате умножения одной из комбинаций полного четырехзначного двоичного кода (в данном случае 1111) на образующий многочлен, так и умножением заданной комбинации на одночлен, имеющий ту же степень, что и выбранный образующий многочлен (в нашем случае таким образом была получена комбинация 1101000) с последующим добавлением к полученному произведению остатка от деления этого произведения на образующий многочлен (в нашем примере остаток имел вид 001). Таким образом, мы уже знаем два способа образования комбинаций линейных систематических кодов, к которым относятся и интересующие нас циклические коды. Эти способы явились теоретическим основанием для построения кодирующих и декодирующих устройств. Шифраторы циклических кодов, в том или ином виде, построены по принципу умножения двоичных многочленов. Кодовые комбинации получаются в результате сложения соседних комбинаций по модулю два, что, как мы увидим ниже, эквивалентно умножению первой комбинации на двучлен Итак, комбинации циклических кодов можно представлять в виде многочленов, у которых показатели степени
Циклический сдвиг кодовой комбинации аналогичен умножению соответствующего многочлена нах:
Если степень многочлена достигает разрядности кода, то происходит «перенос» в нулевую степень при
т. е. существует принципиальная возможность получения любой кодовой комбинации циклического кода путем умножения соответствующим образом подобранного образующего многочлена на некоторый другой многочлен. Однако мало построить циклический код. Надо уметь выделить из него возможные ошибочные разряды, т. е. ввести некоторые опознаватели ошибок, которые выделяли бы ошибочный блок из всех других. Так как циклические коды - блочные, то каждый блок должен иметь свой опознаватель. И тут решающую роль играют свойства образующего многочлена. Методика построения циклического кода такова, что образующий многочлен принимает участие в образовании каждой кодовой комбинации, поэтому любой многочлен циклического кода делится на образующий без остатка. Но без остатка делятся только те многочлены, которые принадлежат данному коду, т. е. образующий многочлен позволяет выбрать разрешенные комбинации из всех возможных. Если же при делении циклического кода на образующий многочлен будет получен остаток, то значит либо в коде произошла ошибка, либо это комбинация какого-то другого кода (запрещенная комбинация), что для декодирующего устройства не имеет принципиальной разницы. По остатку и обнаруживается наличие запрещенной комбинации, т. е. обнаруживается ошибка. Остатки от деления многочленов являются опознавателями ошибок циклических кодов. С другой стороны, остатки от деления единицы с нуляминаобразующий многочлен используются для построения циклических кодов (возможность этого видна из выражения (76)). При делении единицы с нулями на образующий многочлен следует помнить, что длина остатка должна быть не меньше числа контрольных разрядов, поэтому в случае нехватки разрядов в остатке к остатку приписывают справа необходимое число нулей. Например,
начиная с восьмого, остатки будут повторяться. Остатки от деления используют для построения образующих матриц, которые, благодаря своей наглядности и удобству получения производных комбинаций, получили широкое распространение для построения циклических кодов. Построение образующей матрицы сводится к составлению единичной транспонированной и дополнительной матрицы, элементы которой представляют собой остатки от деления единицы с нулями на образующий многочлен Однако не все остатки от деления единицы с нулями на образующий многочлен могут быть использованы в качестве элементов дополнительной матрицы. Использоваться могут лишь те остатки, вес которых где Строки образующей матрицы представляют собой первые комбинации искомого кода. Остальные комбинации кода получаются в результате суммирования по модулю 2 всевозможных сочетаний строк образующей матрицы[16]. Описанный выше метод построения образующих матриц не является единственным. Образующая матрица может быть построена в результате непосредственного умножения элементов единичной матрицы на образующий многочлен. Это часто бывает удобнее, чем нахождение остатков от деления. Полученные коды ничем не отличаются от кодов, построенных по образующим матрицам, в которых дополнительная матрица состоит из остатков от деления единицы с нулями на образующий многочлен. Образующая матрица может быть построена также путем циклического сдвига комбинации, полученной в результате умножения строки единичной матрицы ранга на образующий многочлен. В заключение предлагаем еще один метод построения циклических кодов. Достоинством этого метода является исключительная простота схемных реализации кодирующих и декодирующих устройств. Для получения комбинаций циклического кода в этом случае достаточно произвести циклический сдвиг строки образующей матрицы и комбинации, являющейся ее зеркальным отображением. При построении кодов с, Число ненулевых комбинаций, получаемых в результате суммирования по модулю 2 всевозможных сочетаний строк образующей матрицы,
где Число ненулевых комбинаций, получаемых в результате циклического сдвига любой строки образующей матрицы и зеркальной ей комбинации,
где При числе информационных разрядов Ошибки в циклических кодах обнаруживаются и исправляются при помощи остатков от деления полученной комбинации на образующий многочлен. Остатки от деления являются опознавателями ошибок, но не указывают непосредственно на место ошибки в циклическом коде. Идея исправления ошибок базируется на том, что ошибочная комбинация после определенного числа циклических сдвигов “ подгоняется ” под остаток таким образом, что в сумме с остатком она дает исправленную комбинацию. Остаток при этом представляет собой не что иное, как разницу между искаженными и правильными символами, единицы в остатке стоят как раз на местах искаженных разрядов в подогнанной циклическими сдвигами комбинации. Подгоняют искаженную комбинацию до тех пор, пока число единиц в остатке не будет равно числу ошибок в коде. При этом, естественно, число единиц может быть либо равно числу ошибок, исправляемых данным кодом (код исправляет 3 ошибки и в искаженной комбинации 3 ошибки), либо меньше s (код исправляет 3 ошибки, а в принятой комбинации - 1 ошибка). Место ошибки в кодовой комбинации не имеет значения. Если то после определенного количества сдвигов все ошибки окажутся в зоне “разового” действия образующего многочлена, т. е. достаточно получить один остаток, вес которого, и этого уже будет достаточно для исправления искаженной комбинации. В этом смысле коды БЧХ (о них мы будем говорить ниже) могут исправлять пачки ошибок, лишь бы длина пачки не превышала s. Построение и декодирование конкретных циклических кодов I. Коды, исправляющие одиночную ошибку, 1. Расчет соотношения между контрольными и информационными символами кода производится на основании выражений (59) - (69). Если задано число информационных разрядов
Общее число символов кода
Если задана длина кода
Соотношение числа контрольных и информационных символов для кодов с приведены в табл. 3 приложения 9. 2. Выбор образующего многочлена производится по таблицам неприводимых двоичных многочленов. Образующий многочлен 3. Выбор параметров единичной транспонированной матрицы происходитиз условия, что число столбцов (строк) матрицы определяется числом информационных разрядов, т. е. ранг единичной матрицы равен. 4. Определение элементов дополнительной матрицы производится по остаткам от деления последней строки транспонированной матрицы (единицы с нулями) на образующий многочлен. Полученные остатки должны удовлетворять следующим требованиям: а) число разрядов каждого остатка должно быть равно числу контрольных символов, следовательно, число разрядов дополнительной матрицы должно быть равно степени образующего многочлена; б) число остатков должно быть не меньше числа строк единичной транспонированной матрицы, т. е. должно быть равно числу информационных разрядов в) число единиц каждого остатка, т. е. его вес, должно быть не менее величины, где г) количество нулей, приписываемых к единице с нулями при делении ее на выбранный неприводимый многочлен, должно быть таким, чтобы соблюдались условия а), б), в). 5. Образующая матрица составляется дописыванием элементов дополнительной матрицы справа от единичной транспонированной матрицы либо умножением элементов единичной матрицы на образующий многочлен. 6. Комбинациями искомого кода являются строки образующей матрицы и все возможные суммы по модулю 2 различных сочетаний строк образующей матрицы. 7. Обнаружение и исправление ошибок производится по остаткам от деления принятой комбинации на образующий многочлен а) принятую комбинацию делят на образующий многочлен и б) подсчитывают количество единиц в остатке (вес остатка). Если в) производят циклический сдвиг принятой комбинации влево на один разряд. Комбинацию, полученную в результате циклического сдвига, делят на. Если в результате этого повторного деления то делимое суммируют с остатком, затем г) производят циклический сдвиг вправо на один разряд комбинации, полученной в результате суммирования последнего делимого с последним остатком. Полученная в результате комбинация уже не содержит ошибок. Если после первого циклического сдвига и последующего деления остаток получается таким, что его вес, то д) повторяют операцию пункта в) до тех пор, пока не будет. В этом случае комбинацию, полученную в результате последнего циклического сдвига, суммируют с остатком от деления этой комбинации на образующий многочлен, а затем е) производят циклический сдвиг вправо ровно на столько разрядов,на сколько была сдвинута суммируемая с последним остатком комбинация относительно принятой комбинации. В результате получим исправленную комбинацию[18]. II. Коды, обнаруживающие трехкратные ошибки, 1. Выбор числа корректирующих разрядов производитсяиз соотношения
или
2. Выбор образующего многочлена производят, исходя из следующих соображений: для обнаружения трехкратной ошибки
поэтому степень образующего многочлена не может быть меньше четырех; многочлен третьей степени, имеющий •число ненулевых членов больше или равное трем, позволяет обнаруживать все двойные ошибки, многочлен первой степени обнаруживает любое количество нечетных ошибок, следовательно, многочлен четвертой степени, получаемый в результате умножения этих многочленов, обладает их корректирующими свойствами: может обнаруживать две ошибки, а также одну и три, т. е. все трехкратные ошибки. 3. Построение образующей матрицы производят либо нахождением остатков от деления единицы с нулями на образующий многочлен, либо умножением строк единичной матрицы на образующий многочлен. 4. Остальные комбинации корректирующего кода находят суммированием по модулю 2 всевозможных сочетаний строк образующей матрицы. 5. Обнаружение ошибок производится по остаткам от деления принятой комбинации на образующий многочлен Пример: Исходная кодовая комбинация - 0101111000, принятая - 0001011001 (т. е. произошел тройной сбой). Показать процесс обнаружения ошибки, если известно, что комбинации кода были образованы при помощи многочлена 101111. Решение:
Остаток не нулевой, комбинация бракуется. Указать ошибочные разряды при трехкратных искажениях такие коды не могут. III. Циклические коды, исправляющие две и большее количество ошибок, Методика построения циклических кодов с Построение образующего многочлена зависит, в основном, от двух параметров: от длины кодового слова п. и от числа исправляемых ошибок s. Остальные параметры, участвующие в построении образующего многочлена, в зависимости от заданных и Для исправления числа ошибок
при этом п всегда будет нечетным числом. Величина h определяет выбор числа контрольных символов
С другой стороны, число контрольных символов определяется образующим многочленом и равно его степени. При больших значениях h длина кода п становится очень большой, что вызывает вполне определенные трудности при технической реализации кодирующих и декодирующих устройств. При этом часть информационных разрядов порой остается неиспользованной. В таких случаях для определения h удобно пользоваться выражением
где Соотношения между
Например, при h = 10 длина кодовой комбинации может быть равна и 1023 и 341 (С = 3), и 33 (С =31), и 31 (С = 33), понятно, что п не может быть меньше Величина С влияет на выбор порядковых номеров минимальных многочленов, так как индексы первоначально выбранных многочленов умножаются на С. Построение образующего многочлена
Порядок многочлена используется при определении числа сомножителей. Например, если s = 6, то. Так как для построения
а старшая степень
( Степень образующего многочлена, полученного в результате перемножения выбранных минимальных многочленов,
В общем виде
Декодирование кодов БЧХ производится по той же методике, что и декодирование циклических кодов с
Сжатие информации представляет собой операцию, в результате которой данному коду или сообщению ставится в соответствие более короткий код или сообщение[19]. Сжатие информации имеет целью - ускорение и удешевление процессов механизированной обработки, хранения и поиска информации, экономия памяти ЭВМ. При сжатии следует стремиться к минимальной неоднозначности сжатых кодов при максимальной простоте алгоритма сжатия. Рассмотрим наиболее характерные методы сжатия информации. Сжатие информации делением кода на части, меньшие некоторой наперед заданной величины А, заключается в том, что исходный код делится на части, меньшие А, после чего полученные части кода складываются между собой либо по правилам.двоичной арифметики, либо по модулю 2. Например, исходный код 101011010110; A = 4
Сжатие информации с побуквенным сдвигом в каждом разряде [5], как и предыдущий способ, не предусматривает восстановления сжимаемых кодов, а применяется лишь для сокращения адреса либо самого кода сжимаемого слова в памяти ЭВМ. Предположим, исходное слово «газета» кодируетсякодом, в котором длина кодовой комбинации буквы l = 8: Г - 01000111; а - 11110000; з - 01100011; е - 00010111; т - 11011000. Полный код слова «Газета» 010001111111000001100011000101111101100011110000. Сжатие осуществляется сложением по модулю 2 двоичных кодов букв сжимаемого слова с побуквенным сдвигом в каждом разряде.
Допустимое количество разрядов сжатого кода является вполне определенной величиной, зависящей от способа кодирования и от емкости ЗУ. Количество адресов, а соответственно максимальное количество слов в выделенном участке памяти машины определяется из следующего соотношения
где
где k - число побуквенных сдвигов; Так как сдвигаются все буквы, кроме первой, то и число сдвигов, где L - число букв в слове. Тогда
В русском языке наиболее длинные слова имеют 23 - 25 букв. Если принять, с условием осуществления побуквенного сдвига с каждым шагом ровно на один разряд, для n и l могут быть получены следующие соотношения
Если значение Например, если для предыдущего примера со словом “Газета”, сжатый код будет иметь вид:
Метод сжатия информации на основе исключения повторения в старших разрядах последующих строк, массивов одинаковых элементов старших разрядов предыдущих строк массивов основан на том, что в сжатых массивах повторяющиеся элементы старших разрядов заменяются некоторым условным символом. Очень часто обрабатываемая информация бывает представлена в виде набора однородных массивов, в которых элементы столбцов или строк массивов расположены в нарастающем порядке. Если считать старшими разряды, расположенные левее данного элемента, а младшими - расположенные правее, то можно заметить, что во многих случаях строки матриц отличаются друг от друга в младших разрядах. Если при записи каждого последующего элемента массива отбрасывать все повторяющиеся в предыдущем элементы, например в строке стоящие подряд элементы старших разрядов,то массивы могут быть сокращены от 2 до 10 и более разрядов [2]. Для учета выброшенных разрядов вводится знак раздела, который позволяет отделить элементы в свернутом массиве. В случае полного повторения строк записывается соответствующе количество Для примера рассмотрим следующий массив:
Свернутый массив будет иметь вид:
Расшифровка (развертывание) происходит с конца массива. Переход на следующую строку происходит по двум условиям: либо по заполнению строки, либо при встрече.
Пропущенные цифры заполняются автоматически по аналогичным разрядам предыдущей строки. Заполнение производится с начала массива. Этот метод можно развить и для свертывания массивов, в которых повторяющиеся разряды встречаются не только с начала строки. Если в строке один повторяющийся участок, то кроме
Если в строке есть два повторяющихся участка,то, используя этот метод, выбрасываем больший. Процесс развертывания массива осуществляется следующим образом: переход на следующую строку происходит при встрече К
Пропущенные цифры заполняются по аналогичным разрядам предыдущей строки начиная с конца массива. Если в строке массива несколько повторяющихся участков, томожно вместо вставлять специальные символы, указывающие на необходимое число пропусков. Например, если обозначить количество пропусков, соответственно, Х - 2; Y - 3; Z - 5, то исходный и свернутый массивы будут иметь вид:
Процесс развертывания массива осуществляется следующим образом: длина строки известна, количество пропусков определяется символами X, Y, Z
Пропущенные цифры заполняются по аналогичным разрядам предыдущей строки. Условием перехода на следующую строку является заполнение предыдущей строки. Метод Г. В. Ливинского основан на том, что в памяти машины хранятся сжатые числа, разрядность которых меньше разрядности реальных чисел. Эффект сжатия достигается за счет того, что последовательности предварительно упорядоченных чисел разбиваются на ряд равных отрезков, внутри которых отсчет ведется не по их абсолютной величине, а от границы предыдущего отрезка. Разрядность чисел, получаемых таким образом, естественно, меньше разрядности соответствующих им реальных чисел [18, 21]. Для размещения в памяти ЭВМ М кодов, в которых наибольшее из кодируемых чисел равно N, необходим объем памяти
С ростом N длина кодовой комбинации будет расти как. Для экономии объема памяти Q, число, где выражение в скобках - округленное значение до ближайшего целого числа, разбивают на L равных частей. Максимальное число в полученном интервале чисел будет не больше
Чтобы найти, при каких L выражение (89) принимает минимальное значение, достаточно продифференцировать его по Lи, приравнять производную к нулю. Нетрудно убедиться, что будет при
Если подставить значение
Для значений
При поиске информации в памяти ЭВМ прежде всего определяют значение и находят величину интервала между двумя границами
Затем определяют, в каком именно из интервалов находится искомое число х
После этого определяется адрес искомого числа как разность между абсолютным значением числа и числом, которое является граничным для данного интервала. [1] Первичный алфавит составлен из m1 символов (качественных признаков), при помощи которых записано передаваемое сообщение. Вторичный алфавит состоит из m2 символов, при помощи которых сообщение трансформируется в код. [2] Строго говоря, объема информации не существует. Мы вкладываем в этот термин то, что привыкли под этим подразумевать, - количество элементарных символов в принятом (вторичном) сообщении. [3] Суть взаимозависимости символов букв алфавита заключается в том, что вероятность появления i-й буквы в любом месте сообщения зависит от того, какие буквы стоят перед ней и после нее, и будет отличаться от безусловной вероятности pi, известной из статистических свойств данного алфавита. ' Рассмотрение семантической избыточности не входит в задачи теории информации. [5] Здесь и далее под термином «оптимальный код» будем подразумевать коды с практически нулевой избыточностью, так как сравниваем длину кодовой комбинации с энтропией источника сообщений, не учитывая взаимозависимость символов. С учетом взаимозависимости символов эффективность кодирования никогда не будет 100 %, т. е.
Кроме того, являясь оптимальным с точки зрения скорости передачи информации, код может быть неоптимальным с течки зрения предъявляемых к нему требований помехоустойчивости. [6] т—-число качественных признаков строящегося оптимального кода. [7] С основной теоремой кодирования для каналов связи без шумов можно ознакомиться в работе К. Шеннона «Работы по теории информации и кибернетике* либо в популярном изложении в работах [18, 22]. [8] Рассмотренный принцип заложен в основу мажоритарного декодирования.-корректирующих кодов и известен как метод Бодо—Вердана. [9] В какой-то мере исключением из этого правила являются рефлексные коды. В этих кодах последующая комбинация отличается от предыдущей одним символом. В таких, в общем-то безызбыточных кодах, одновременное изменение нескольких символов в принятом сообщении говорит о наличии ошибки. Однако обнаруживать ошибку такие коды могут только в том случае, если кодовые комбинации следуют строго друг за другом. На практике это возможно при передаче информации о плавно изменяющихся процессах. [10] В обоих выражениях квадратные скобки означают, что берется округленное значение до ближайшего целого числа в большую сторону. Индекс при показывает количество исправляемых ошибок, а число в круглых скобках при индексе - число обнаруживаемых ошибок. [11] Условие верхней и нижней границ для максимально допустимого числа информационных разрядов может быть записано следующим образом:
[12] ' Оптимальным корректирующим кодом для симметричного канала называется групповой код, при использовании которого вероятность ошибки не больше, чеу при использовании лю5ого другого кода с такими же п„ и Лц [1, 2, б]. У этих кодов критерий оптимальности не имеет ничего общего с критерием оптимальности ОНК. [13] Практически», так как контрольные символы циклических кодов, построенных путем простого перемножения многочленов, могут оказаться в произвольном месте кодовой комбинации. [14] Упрощенно, множество элементов принадлежит к одному полю, если над ними можно производить операции сложения и умножения по правилам данного поля, при этом сложение и умножение должны подчиняться дистрибутивному закону [15] О возможности представления линейного кода в виде единичной и некоторой дополнительной матрицы см., например, [22, с. 408, 409]. [16] Следует сказать, что не все циклические коды могут быть полученытакимпростым способом, однако не будем пока усложнять изложение. [17] можно определятьи по формуле [18] Коды с d0 = 2, обнаруживающие одиночную ошибку, здесь сознательно не рассматриваются, так как они не имеют практического значения. В двоичных кодах всегда проще подобрать контрольный символ 0 или 1 таким образом, чтобы сумма единиц в кодовом слове была четной, чем строить циклический код для получения того же результата. [19] Кодирование от сжатия отличается тем, что коды почти всегда длиннее кодируемых сообщений, так как число качественных признаков вторичного алфавита (кода) обычно не бывает больше числа качественных признаков первичного алфавита (кодируемых сообщений). Говоря «сжатый код», будем иметь в виду комбинацию, представляющую кодируемое понятие после процедуры сжатия.
|
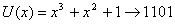 . Пока не обосновывая свой выбор, берем из таблицы неприводимых многочленов (табл. 2, приложение 9) в качестве образующего многочлен. Затем умножим
. Пока не обосновывая свой выбор, берем из таблицы неприводимых многочленов (табл. 2, приложение 9) в качестве образующего многочлен. Затем умножим 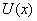 на одночлен той же степени, что и образующий многочлен. От умножения многочлена на одночлен степени п степень каждого члена многочлена повысится на, что эквивалентно приписыванию
на одночлен той же степени, что и образующий многочлен. От умножения многочлена на одночлен степени п степень каждого члена многочлена повысится на, что эквивалентно приписыванию 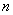 нулей со стороны младших разрядов многочлена. Так как степень выбранного неприводимого многочлена равна трем, то исходная информационная комбинация умножается на одночлен третьей степени:
нулей со стороны младших разрядов многочлена. Так как степень выбранного неприводимого многочлена равна трем, то исходная информационная комбинация умножается на одночлен третьей степени: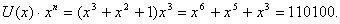
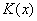 :
: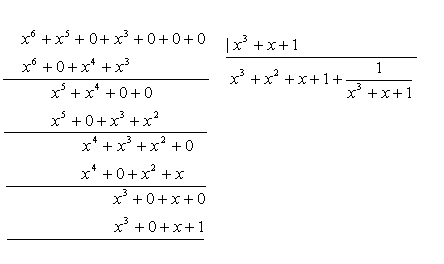

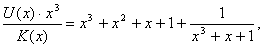
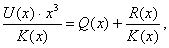 (75)
(75) - частное, a - остаток от деления
- частное, a - остаток от деления 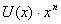 на.
на. , а значит,, то можно при сложении двоичных чисел переносить слагаемые из одной части равенства в другую без изменения знака (если это удобно), поэтому равенство вида
, а значит,, то можно при сложении двоичных чисел переносить слагаемые из одной части равенства в другую без изменения знака (если это удобно), поэтому равенство вида 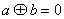 можно записать и как и как
можно записать и как и как 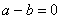 . Все три равенства в данном случае означают, что либо
. Все три равенства в данном случае означают, что либо 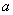 и равны 0, либо а и
и равны 0, либо а и  равны 1, т. е. имеют одинаковую четность.
равны 1, т. е. имеют одинаковую четность. (76)
(76)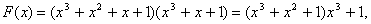
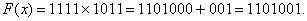
 .
. соответствуют номерам разрядов, коэффициенты при х равны 0 или 1 в зависимости от того, стоит 0 или 1 в разряде кодовой комбинации, которую представляет данный многочлен. Например,
соответствуют номерам разрядов, коэффициенты при х равны 0 или 1 в зависимости от того, стоит 0 или 1 в разряде кодовой комбинации, которую представляет данный многочлен. Например,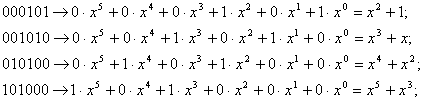

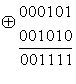

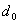 - минимальное кодовое расстояние. Длина остатков должна быть не менее количества контрольных разрядов, а число остатков должно равняться числу информационных разрядов.
- минимальное кодовое расстояние. Длина остатков должна быть не менее количества контрольных разрядов, а число остатков должно равняться числу информационных разрядов.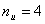 , число комбинаций, получаемых суммированием по модулю 2 всевозможных сочетаний строк образующей матрицы, равно числу комбинаций, получаемых в результате циклического сдвига строки образующей матрицы и зеркальной ей комбинации. Однако этот способ используется для получения кодов с малым числом информационных разрядов. Уже при число комбинаций, получаемых в результате циклического сдвига, будет меньше, чем число комбинаций, получаемых в результате суммирования всевозможных сочетаний строк образующей матрицы.
, число комбинаций, получаемых суммированием по модулю 2 всевозможных сочетаний строк образующей матрицы, равно числу комбинаций, получаемых в результате циклического сдвига строки образующей матрицы и зеркальной ей комбинации. Однако этот способ используется для получения кодов с малым числом информационных разрядов. Уже при число комбинаций, получаемых в результате циклического сдвига, будет меньше, чем число комбинаций, получаемых в результате суммирования всевозможных сочетаний строк образующей матрицы.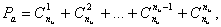 (77)
(77) - число информационных разрядов кода[17].
- число информационных разрядов кода[17]. (78)
(78) число комбинаций от суммирования строк образующей матрицы растет гораздо быстрее, чем число комбинаций, получаемых в результате циклического сдвига строки образующей матрицы и зеркальной ей комбинации. В последнем случае коды получаются избыточными (так как при той же длине кода можно иным способом передать большее количество сообщений), соответственно, падает относительная скорость передачи информации. В таких случаях целесообразность применения того или иного метода кодирования может быть определена из конкретных технических условий.
число комбинаций от суммирования строк образующей матрицы растет гораздо быстрее, чем число комбинаций, получаемых в результате циклического сдвига строки образующей матрицы и зеркальной ей комбинации. В последнем случае коды получаются избыточными (так как при той же длине кода можно иным способом передать большее количество сообщений), соответственно, падает относительная скорость передачи информации. В таких случаях целесообразность применения того или иного метода кодирования может быть определена из конкретных технических условий.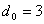 .
. находимиз выражения
находимиз выражения
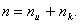
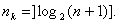
 , где s - допустимое число исправляемых данным кодом ошибок, то принятую комбинацию складывают по модулю 2 с полученным остатком. Сумма даст исправленную комбинацию. Если, то
, где s - допустимое число исправляемых данным кодом ошибок, то принятую комбинацию складывают по модулю 2 с полученным остатком. Сумма даст исправленную комбинацию. Если, то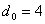 .
.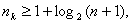
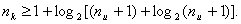
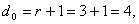
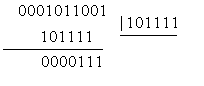
 отличается от методики построения циклических кодов с
отличается от методики построения циклических кодов с  только в выборе образующего многочлена. В литературе эти коды известны как коды БЧХ (первые буквы фамилий Боуз, Чоудхури, Хоквинхем - авторов методики построения циклических кодов с).
только в выборе образующего многочлена. В литературе эти коды известны как коды БЧХ (первые буквы фамилий Боуз, Чоудхури, Хоквинхем - авторов методики построения циклических кодов с).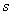 могут быть определены при помощи таблиц и вспомогательных соотношений, о которых будет сказано ниже.
могут быть определены при помощи таблиц и вспомогательных соотношений, о которых будет сказано ниже. еще не достаточно условия, чтобы между комбинациями кода минимальное кодовое расстояние
еще не достаточно условия, чтобы между комбинациями кода минимальное кодовое расстояние  . необходимо также, чтобы длина кода удовлетворяла условию
. необходимо также, чтобы длина кода удовлетворяла условию (79)
(79) (80)
(80) (81)
(81)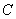 являетсяодним из сомножителей, на которые разлагается число п.
являетсяодним из сомножителей, на которые разлагается число п.
 , которые являются простыми неприводимыми многочленами (см. табл. 2, приложение 9). Образующий многочлен представляет собой произведение нечетных минимальных многочленов и являетсяих наименьшим общим кратным (НОК). Максимальный порядок
, которые являются простыми неприводимыми многочленами (см. табл. 2, приложение 9). Образующий многочлен представляет собой произведение нечетных минимальных многочленов и являетсяих наименьшим общим кратным (НОК). Максимальный порядок 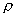 определяет номер последнего из выбираемых табличных минимальных многочленов
определяет номер последнего из выбираемых табличных минимальных многочленов (82)
(82) старший из них имеет порядок. Как видим, число сомножителей
старший из них имеет порядок. Как видим, число сомножителей 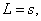 (83)
(83)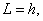 (84)
(84)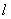 указывает колонку в таблице минимальных многочленов,из которой обычно выбирается многочлен для построения).
указывает колонку в таблице минимальных многочленов,из которой обычно выбирается многочлен для построения).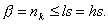 (85)
(85) (86)
(86)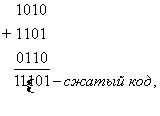

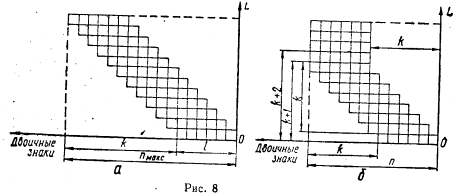
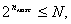 (88)
(88) - максимально допустимая длина (количество двоичных разрядов) сжатого кода; N - возможное количество адресов в ЗУ. Если представить процесс побуквенного сдвига в общем виде, как показано на рис. 1, а, то длина сжатого кода
- максимально допустимая длина (количество двоичных разрядов) сжатого кода; N - возможное количество адресов в ЗУ. Если представить процесс побуквенного сдвига в общем виде, как показано на рис. 1, а, то длина сжатого кода
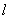 - длина кодовой комбинации буквы.
- длина кодовой комбинации буквы.
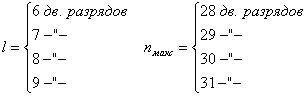




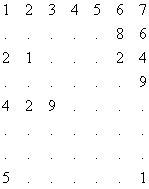


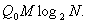
 . Величина определяет разрядность хранимых чисел, объем памяти дляих хранения будет не больше. Если в памяти ЭВМ хранить адреса границ отрезков и порядковые номера хранимых чисел, отсчитываемых от очередной границы, то
. Величина определяет разрядность хранимых чисел, объем памяти дляих хранения будет не больше. Если в памяти ЭВМ хранить адреса границ отрезков и порядковые номера хранимых чисел, отсчитываемых от очередной границы, то 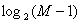 определяет разрядность чисел для выражения номера границы (в последнем интервале должно быть хотя бы одно число); объем памяти для хранения номеров границ будет где
определяет разрядность чисел для выражения номера границы (в последнем интервале должно быть хотя бы одно число); объем памяти для хранения номеров границ будет где 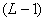 - число границ между отрезками (это число всегда на единицу меньше, чем число отрезков). Общий объем памяти приэтом будет не больше
- число границ между отрезками (это число всегда на единицу меньше, чем число отрезков). Общий объем памяти приэтом будет не больше (89)
(89) [20] (90)
[20] (90) в выражение (89), то получим. значение объема памяти при оптимальном количестве зон, на, которые разбиваются хранимые в памяти ЭВМ числа,
в выражение (89), то получим. значение объема памяти при оптимальном количестве зон, на, которые разбиваются хранимые в памяти ЭВМ числа, (91)
(91) при вычислениях можно пользоваться приближенной формулой
при вычислениях можно пользоваться приближенной формулой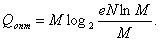 (92)
(92)
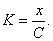

 .
. для всех и
для всех и  .
.


