
И проведения социологического мониторинга.
Министерство здравоохранения и социального развития РФ
В качестве основного признака изучается показатель общей заболеваемости (по обращаемости) по отдельным группам заболеваний в различных возрастных, социальных и профессиональных группах населения, административных территориях. При проведении выборочного изучения заболеваемости необходимо обеспечить условие репрезентативности выборки.
Объем выборочной совокупности n рассчитывается по следующему алгоритму: 1. 2.
3. 4. 5. Рассчитываются значения оценки s: · по пробной выборке объема n 1 , меньшего предполагаемого; · по данным предыдущих исследований; · согласно каким-либо предположениям о структуре совокупности
6. Объем выборки для заданной надежности
При достаточно больших N:
7. Вычисление объема выборки n по частости
При достаточно больших N (тогда) формула выглядит следующим образом:
Таблица 1. Объем выборочной совокупности при максимально возможной величине дисперсии.
Пример: Генеральная совокупность (1) – жители Новгородской области. Примем объем этой генеральной “совокупности n(1) = 700 000. Уровень охвата обязательным медицинским страхованием населения Новгородской области медицинской страховой организацией составляет 98%. Таким образом, объем генеральной совокупности будет n(2) = N(1) * 0.98 = 700000 * 0.98 = 686000.
В таблице 2 для некоторых объемов выборок при надёжности
Таблица 2. Оценка точности вычислений вероятности р при надёжности в зависимости от объёма выборки
При оцениваемой вероятности · на 0,018594 (т.е. 1,8594%) при объеме выборки 1000 наблюдений; · на 0,013148 (т.е. 1,3148%) при объеме выборки 2000 наблюдений; · на 0,008316 (т.е. 0,8316%) при объеме выборки 5000 наблюдений и т.д. Фактические значения точности оценок вероятности окажутся заведомо меньше (лучше) приведенных, так как указанные в таблице 2 значения рассчитаны, исходя из верхней границы соответствующего интервала и генеральной совокупности бесконечного объема. Существенное увеличение объема выборочной совокупности требует фактически пропорционального объема финансовых и материальных затрат, но при этом, как видим из приведенной таблицы, не приводит к радикальному увеличению точности оценок. Например, при Основываясь на указанных в таблице значениях, рекомендуется не ставить самоцелью повышения точности оценок за счет неоправданного увеличения объема выборки, а найти разумный компромисс между приемлемой точностью и объемом выборочной совокупности (в исследовании, проводимом в Новгородской области, объем выборки равен 10000 наблюдений). Для обеспечения качества выборочной совокупности в данной методике используются методы серийного, многоступенчатого и случайного (механического) отбора, при этом отбор респондентов в выборку проводится по следующему алгоритму: 1. Производится экономико-географическое зонирование территории (север, юг, запад, восток). С учетом географического расположения и характера региональных транспортных сетей (основные железнодорожные и автотранспортные магистрали), выделяются условно близкие по площади географические зоны с равным количеством муниципальных районов. 2. Внутри каждой зоны проводится отбор одного района, который характеризуется наиболее близкими (к средним в своей зоне) значениями следующих показателей государственной статистики: · численность сельского населения; · средняя плотность сельского населения; · коэффициент, выражающий соотношение численности групп населения, занятых в индустриальном и аграрном секторах экономики. 3. Проводится внутрирайонная выборка поселений, являющихся основными базами для организации выборочного исследования. 4. В отобранных поселениях, на основе реестров застрахованных уточняются данные о населении. Лица, попавшие в выборку, должны быть идентифицированы по БД заболеваемости медицинских страховых организаций. Для формирования выборочной совокупности, объема n, из списка населения региона (БД “Реестр застрахованных” СМО или ТО ФОМС, либо любая другая БД, содержащая региональный список населения) с помощью компьютерных методик (генератор случайных чисел) формируется выборочная персонифицированная БД. Кроме того, формируется “резервная выборка” (резервная выборочная персонифицированная БД) с использованием тех же алгоритмов. В случае отсутствия индивидуума по месту прописки, отказа индивидуума от прохождения медосмотра и т.п., из этой резервной выборки отбираются индивидуумы взамен выбывшего (из той же половозрастной группы), т.е. производится “ремонт” выборки. Сформированная таким образом выборочная совокупность репрезентативна в отношении всего населения региона. Полученная выборка (в виде персонифицированной базы данных) используется для проведения медицинских осмотров и изучения физического состояния населения, для проведения социологического мониторинга.
|
 На первом этапе расчета выборочной совокупности устанавливаются желательные пределы ошибки выборки
На первом этапе расчета выборочной совокупности устанавливаются желательные пределы ошибки выборки  и приблизительные характеристики распределения исследуемого показателя.
и приблизительные характеристики распределения исследуемого показателя. На практике задается не величина абсолютной ошибки, а величина относительной погрешности, выраженная в процентах.
На практике задается не величина абсолютной ошибки, а величина относительной погрешности, выраженная в процентах.

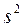
 Рассчитывается дисперсия генеральной совокупности. В реальных зада-чах, вместо, обычно используют исправленную выборочную дисперсию.
Рассчитывается дисперсия генеральной совокупности. В реальных зада-чах, вместо, обычно используют исправленную выборочную дисперсию.


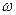 (
( )следует так, чтобы произведение принимало наибольшее значение. Если относительная частота даже приблизительно не известна, можно провести примерный расчет выборки, вводя в расчет максимальную величину дисперсии доли, равную 0,25 (т.е. при = 0,5). В случаях, когда заведомо меньше 0,5 значение можно уменьшить, и, тем самым уменьшится необходи-мый объем выборки.
)следует так, чтобы произведение принимало наибольшее значение. Если относительная частота даже приблизительно не известна, можно провести примерный расчет выборки, вводя в расчет максимальную величину дисперсии доли, равную 0,25 (т.е. при = 0,5). В случаях, когда заведомо меньше 0,5 значение можно уменьшить, и, тем самым уменьшится необходи-мый объем выборки. , гарантирующий определяемую заранее точность, определяется следующим образом:
, гарантирующий определяемую заранее точность, определяется следующим образом:
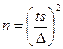 .
. представлена выражением
представлена выражением  . Объем выборки n вычисляется по формуле:
. Объем выборки n вычисляется по формуле: .
.

 .
.
 При максимальной величине дисперсии доли равной =0,25 (т.е. при =0,5), при заданной величине предельной ошибки объем необходимой выборки находится по таблице 1:
При максимальной величине дисперсии доли равной =0,25 (т.е. при =0,5), при заданной величине предельной ошибки объем необходимой выборки находится по таблице 1: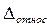 , %
, %
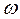
 Расчет выборочной дисперсии по пробной выборке объема n1 , меньшего предполагаемого или по данным предыдущих исследований может быть затруднителен в виду отсутствия такой информации. Поэтому дальнейший расчет поведем по частости, характеризующей долю общей заболеваемости по обращаемости по данным государственной статистики.
Расчет выборочной дисперсии по пробной выборке объема n1 , меньшего предполагаемого или по данным предыдущих исследований может быть затруднителен в виду отсутствия такой информации. Поэтому дальнейший расчет поведем по частости, характеризующей долю общей заболеваемости по обращаемости по данным государственной статистики. В общем случае рассчитываем объем выборки, вводя максимальную величину дисперсии доли, равную 0,25.
В общем случае рассчитываем объем выборки, вводя максимальную величину дисперсии доли, равную 0,25.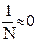
 Задаем величину предельной ошибки =1%, т.е. величина абсолютной предельной ошибки выборки будет = 0,01. Предполагая, что n>120 и задавая надежность
Задаем величину предельной ошибки =1%, т.е. величина абсолютной предельной ошибки выборки будет = 0,01. Предполагая, что n>120 и задавая надежность 

 С резервом выборки 5%, итоговый объем выборки будет равен 10850 единиц. При других значениях и, значения необходимого объема выборки представлены в таблице 1.
С резервом выборки 5%, итоговый объем выборки будет равен 10850 единиц. При других значениях и, значения необходимого объема выборки представлены в таблице 1. представлены оценки точности
представлены оценки точности  (предельной ошибки выборки).
(предельной ошибки выборки).
 с надежностью 0,95 относительная частота
с надежностью 0,95 относительная частота  отличается от истинного (генерального) значения
отличается от истинного (генерального) значения  не более чем:
не более чем: ; объем выборки 20000 гарантирует точность оценки
; объем выборки 20000 гарантирует точность оценки 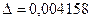 ; объем выборки 100000 гарантирует точность оценки
; объем выборки 100000 гарантирует точность оценки 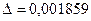 .
.


