Подбор участников исследования
Необходимо разработать четкие, объективные критерии включения в РКИ / исключения из РКИ. Узкие, строгие критерии включения позволяют сфокусировать внимание на тех больных, у которых испытуемое лечение будет наиболее эффективно; при этом вариабельность исходов терапии уменьшится. В то же время, если мы хотим, чтобы полученные результаты можно было экстраполировать на генеральную совокупность лиц с данной патологией, исследуемая выборка должна быть репрезентативной. Вследствие указанного ограничения РКИ часто критикуют за излишнюю «эксклюзивность» (например, из рандомизированных исследований часто исключаются больные с сопутствующей патологией или не говорящие на государственном языке). Кроме того, многие больные могут вообще отказаться от рандомизации из-за личных терапевтических предпочтений. Например, в большинстве исследований, посвященных влиянию статинов на липидный обмен, одним из критериев включения являлся возраст больных, причем обычно исключаются лица моложе 30 и старше 75 лет. При этом в исследование не попадают наиболее пожилые пациенты, у которых вероятность развития атеросклероза наибольшая. Другим примером критериев включения в исследование является РКИ, посвященное сравнению различных схем искусственного вскармливания детей ВИЧ-инфицированных женщин. При этом отбор исследуемых лиц производился среди 16529 беременных женщин, посещающих 4 акушерские клиники в Найроби. Из них 2315 оказались ВИЧ-позитивными, 1708 вернулись, чтобы узнать результаты обследования на ВИЧ, и 425 (18% от общего числа ВИЧ-позитивных женщин) были включены в исследование. Критерии исключения были следующими: нежелание рандомизировать способ вскармливания, нежелание подчиняться приказам исследователей, наличие планов покинуть Найроби после родов, нежелание подвергаться регулярным обследованиям.
4. Разработка метода назначения терапевтических схем (т.е. собственно рандомизация) Рандомизированное назначение терапевтических схем гарантирует, что исследуемые группы будут сбалансированы по основным показателям на большом отрезке времени. Дисбаланс групповых показателей может возникнуть в том случае, если исследуемые группы немногочисленны. Для «выравнивания» небольших групп по отдельным показателям используется т.н. «стратифицированная рандомизация». В этом случае рандомизация проводится в подгруппах, предварительно выделенных из общего пула больных по признаку наличия либо отсутствия какого-либо фактора (факторов), оказывающего существенное влияние на предполагаемый исход исследования. Формируемые путем рандомизации группы должны быть примерно одинаковы по размеру – при этом уменьшается дисперсия значений изучаемых признаков. В то же время требование одинакового размера групп привносит в их формирование некоторую систематическую составляющую, что повышает риск появления систематических ошибок формирования групп – т.н. selection biases. В результате приходится прибегать к компромиссным решениям – т.н. «ограниченным» (restricted) методикам рандомизации.
Различают следующие схемы распределения изучаемых лиц по группам: 1) Статическая – определяется до начала формирования сравниваемых групп, в дальнейшем не меняется. Этот тип распределения используется почти во всех проводимых РКИ. Разновидности: – простая (simple), или полная (complete) рандомизация; – перестановка блоков (permuted blocks); – модель урны для голосования (urn models); – подбрасывание асимметричной монеты (biased coin); – непосредственное назначение (direct assignment).
2) Ковариативная адаптивная (covariate adaptive) – изменяется в зависимости от наблюдаемого соотношения различных существенных признаков (ковариат) у лиц, уже вовлеченных в исследование. Разновидности: – минимизация: распределение по группам с целью в какой-либо степени минимизировать дисперсию либо эффективность. а) метод максимальной энтропии (maximum entropy); б) метод минимального правдоподобия (minimal likelihood).
3) Реактивная адаптивная (response adaptive) – изменяется в зависимости от особенностей реакции уже вовлеченных в исследование лиц на изучаемые воздействия. Разновидности: – «игра на лидера» (play the winner).
Статические схемы нежелательно применять в том случае, если число независимо анализируемых подгрупп (страт) внутри изучаемых групп сравнения сравнимо с количеством больных в каждой из страт; в этом случае лучше работают адаптивные схемы. В том случае, когда наряду с получением информации о сравнительной эффективности различных методов лечения необходимо (с этических позиций) вовремя перевести больных на схему терапии, оказавшуюся наиболее эффективной, реактивная адаптивная схема (т.е. «игра на лидера») вынужденно оказывается более предпочтительной.
Наиболее часто используемые в исследовательской практике схемы рандомизации - полная (complete), простая, перестановка блоков, модель избирательной урны и ковариативная адаптивная. Из указанных схем только полная рандомизация не является ограниченной («restricted»). В случае простой рандомизации, модели избирательной урны и перестановки блоков предполагается предварительное проведение стратификации, что призвано обеспечить баланс частот и выраженности различных признаков в формируемых группах. При этом желателен продуманный, взвешенный подход в выборе признаков для стратификации, иначе размер полученных групп в результате чрезмерно сократится. В то же время ковариативная адаптивная схема исходно адаптирована для получения сбалансированных по всем существенным признакам групп сравнения.
Простая рандомизация (также называемая полной) – рандомизация без ограничений, предполагаемых процессом распределения испытуемых лиц по группам, за исключением предварительного определения общего размера исследуемой выборки. В частности, простая рандомизация имеет место в случае, когда общий размер выборки (n) точно определен заранее, причем схему лечения А получает подгруппа, состоящая из n/2 случайно отобранных индивидуумов, в то время как оставшиеся n/2 больных получают схему лечения Б. Последующее проведение стратификации обеспечивает баланс ковариаций в формируемых группах. Существует много разновидностей простой рандомизации: 1) Бросание монетки («орел или решка»). Позволяет рандомизировать больных в две сравниваемые группы. Образно говоря, перед назначением больного в одну из испытуемых групп исследователь подбрасывает монетку, и если выпадает орел – то больной приписывается к группе А, а если решка – то к группе Б. Метод удовлетворительно работает при больших размерах групп, но на его эффективность могут оказывать влияние случайные факторы - в частности, результат зависит от силы и направления броска, а также от степени симметричности монеты и ее сбалансированности по весу, т.к. при наличии эксцентриситета центра масс вероятность выпадения одной из сторон при равной силы бросках будет значимо выше, чем другой, что будет являться систематически действующим фактором. 2) Бросание игральной кости. Позволяет рандомизировать больных в четное число групп (до шести). При этом определенные выпадающие номера соотносятся с распределением испытуемых в определенную группу (например, четные номера – распределение в группу А, нечетные номера – в группу Б; или номера 1-2 – группа А, 3-4 – группа Б, 5-6 – группа В). Недостатки данного метода такие же, как и у предыдущего – он обеспечивает приблизительно равную численность групп только при их больших размерах, кроме того, возможны систематические ошибки распределения выпадающих номеров в зависимости от силы и направления бросков, а также балансировки кости (это хорошо знают шулеры). В настоящее время методы 1 и 2 имеют лишь историческое значение либо применяются в странах с ограниченными ресурсами. 3) Использование таблицы или последовательности случайных номеров (например, таблицы В13 по Altman или последовательности псевдослучайных чисел, генерируемых программой STATA). Принцип метода такой же, как у вышеперечисленных – определенный пул номеров соотносится с распределением больных в определенную группу. При этом новые номера в таблице считываются в определенной исследователями очередности (скажем, слева направо сверху вниз), один за другим, и сравниваются с заранее заданными интервалами, закрепленными за определенными испытуемыми группами; использованные номера зачеркиваются. Если используется не таблица, а генератор псевдослучайных чисел (ГПСЧ), то новые числа выдаются им последовательно, одно за другим, после чего алгоритм действий такой же (например, если ГПСЧ выдает случайные числа из интервала 0…1, то выпадение числа в интервале 0…0,5 может соответствовать распределению в группу А, а в интервале 0,51…1 – в группу Б, ГПСЧ же запускается при включении в исследование каждого нового больного). Все ГПСЧ продуцируют не случайные, а т.н. псевдослучайные числа, т.к. каждое последующее число отчасти определяется предыдущим. Важнейшей характеристикой ГПСЧ является его «период» – количество итераций, по прошествии которого генератор «зацикливается», т.е. начинает вновь выдавать ранее сгенерированную числовую последовательность. Период разных ГПСЧ различен и составляет от 232 для генератора, встроенного в MS Excel, до 219937–1 для алгоритма «вихрь Мерсенна» (Mersenne twister) [35]. Ранние ГПСЧ грешили коротким периодом (рекорд здесь принадлежит, вероятно, генератору, реализованному на ДВК Basic, который зацикливался через 8192 итерации); естественно, короткий период повторения числовой последовательности является систематически действующим фактором, влекущим за собой ухудшение качества рандомизации. Тем не менее, в настоящее время практически все современные ГПСЧ удовлетворяют требованиям биомедицинских исследований. К числу надежных ГПСЧ относятся, помимо «вихря Мерсенна», AES_OFB, TWOFISH_OFB, Blum-Blum-Shub. 4) Алфавитный метод. Если фамилия (или имя) больного начинается на букву в интервале А-М, он попадает в группу А, а если в интервале Н-Я – то в группу Б; число групп и размеры интервалов могут варьироваться. Ненадежный способ рандомизации, поскольку в обществе могут существенно преобладать всего несколько десятков фамилий – «Иванов, Петров, Сидоров» (на самом деле самые распространенные фамилии в России на текущий момент в порядке убывания – Смирнов (1,86% населения), Иванов (1,33%), Кузнецов (1,0%), Соколов (0,86%), Попов (0,80%). Для имен это еще более справедливо – существенное преобладание всего нескольких имен на протяжении нескольких лет как дань своеобразной моде известно всем. Соответственно, избавиться от систематической ошибки при формировании групп в принципе невозможно, т.к. процесс присвоения имен испытуемым (и наследования фамилий) не находится во власти исследователей и, соответственно, не является случайным. 5) Рандомизация по номеру телефона / социальной страховки. Является вариантом рандомизации по таблице случайных номеров (см. выше), с поправкой на то, что номера телефонов либо страховых свидетельств могут быть неслучайными (например, в некий стационар обращаются в основном жители примыкающих микрорайонов, вследствие чего их номера телефонов принадлежат всего 1-2 пулам и начинаются на одинаковые цифры). Соответственно, пользоваться данным способом рандомизации не рекомендуется, поскольку будет трудно избавиться от систематической ошибки в формировании сравниваемых групп. 6) Последовательная рандомизация. При этом больные, поступившие в течение часа (вариант – до обеда), определяются в группу А, а поступившие в течение следующего часа (соответственно, после обеда) – в группу Б и т.п. Проблема данного метода состоит в том, что время поступления больных может быть неслучайным (ночью и в ранние утренние часы экстренно поступают тяжелые больные, в частности, дети ранних возрастов, с утра до обеда госпитализируются пенсионеры и школьники, после обеда и до позднего вечера – работающие люди и т.д.). Вследствие этого возможны систематические ошибки при формировании исследуемых групп – в группу, набранную до обеда, попадут преимущественно дети и пожилые люди, а после обеда – рабочие и служащие средних лет. Данный метод также не рекомендуется к практическому применению. Все вышеперечисленные методы распределения больных в группы, строго говоря, являются «почти случайными», поскольку несвободны от систематических ошибок. Разница между методами состоит в том, что в некоторых из них влияние систематических ошибок может быть сведено к пренебрежимо малому (например, в методе с применением таблиц или последовательностей случайных номеров – при использовании качественного ГПСЧ с надежным алгоритмом и значительной длиной псевдослучайной последовательности). В остальных случаях систематические ошибки являются неотъемлемой, неконтролируемой и неустранимой чертой описанных методик (неидеальная балансировка монет и игральных костей, неконтролируемо разные сила и направление бросков, преобладание в популяции некоторых имен и фамилий и т.д.), что препятствует их практическому использованию, несмотря на простоту, доступность для понимания (хорошее знание математики среди врачей и биологов – редкость) и дешевизну. Полная (простая) рандомизация – единственная схема, полностью свободная от ограничений, т.о., распределение больных по группам при этом полностью свободно от систематических ошибок. Данный тип рандомизации по умолчанию предполагает, что каждый больной, включенный в исследование, имеет 50% вероятность оказаться в группе А и одновременно - 50% вероятность быть распределенным в группу Б, независимо от каких-либо ранее имевших место дисбалансов в распределении схем лечения. Таким образом, важным свойством полной рандомизации является минимизация предопределенности в процессе распределения по группам. Тем не менее, при наличии ограничений на количество пациентов в группах может иметь место существенный дисбаланс по этому показателю. Например, если необходимо набрать 2 группы по 5 больных в каждой, существует возможность, что в группу А попадет от 0 до 10 человек. Для рассматриваемой группы в 10 человек вероятность оптимального баланса (по 5 человек в каждой из групп) составляет 24,61%. Таким образом, безо всяких дополнительных манипуляций вероятность возникновения дисбаланса составляет 75%. Соответственно, наиболее существенная проблема полной рандомизации – ненулевая вероятность дисбаланса состава формируемых групп (высокая вероятность малого дисбаланса и малая вероятность значительного дисбаланса, соответственно). Если принять за «значительный дисбаланс» разницу в численности формируемых групп в 20% и более, то его вероятность составит 2,16% для вышеупомянутой группы в 10 человек. Дисбаланс количественного состава групп влечет за собой снижение статистической мощности исследования. Ввиду этого, полная рандомизация рекомендуется для исследований, включающих не менее (лучше – более) 200 больных [32]. Существует вариант полной рандомизации, называемый «асимметричная монета» (biased coin), который специально предназначен для ликвидации количественного дисбаланса в формируемых группах непосредственно в процессе рандомизации. В случае, если дисбаланс состава групп выходит за некоторые неприемлемые для исследователей пределы, вводится поправочный коэффициент, повышающий (или понижающий) шансы больного оказаться в той или иной группе испытуемых. Наиболее показательно применение данного метода при использовании рандомизации с помощью последовательности случайных чисел. Предположим, что рандомизация производится в группы А и В; генератор случайных чисел выдает целые числа в диапазоне от 1 до 10, и если выпавшее число меньше или равно 5, больной попадает в группу А, иначе – в группу В. Предположим, что на каком-либо этапе рандомизации в группе А оказалось 7 человек, а в группе В – только 3. В таком случае вводится поправочный коэффициент 1,5, на который умножается выпадающее случайное число; в результате шансы больного попасть в группу А уменьшаются на 20%, и в процессе дальнейшей рандомизации количественный состав формируемых групп постепенно выравнивается. Образно говоря, мы начинаем подбрасывать асимметричную монету вместо «идеальной». При этом распределение участников исследования по группам остается в целом случайным, метод прост в исполнении, но малопригоден для работы с небольшими группами. Как упоминалось выше, особенность полной рандомизации – минимизация систематических ошибок отбора благодаря равной вероятности назначения любой из тестируемых схем лечения при их последовательном переборе. Соответственно, ни больные, ни медицинский персонал и исследователи никоим образом не могут предугадать группу, в которой окажется тот или иной больной, что, в свою очередь, снижает детерминизм распределения. Тем не менее, вышеуказанный дисбаланс количественного состава групп не может замаскировать признаки эффективности сравниваемых терапевтических схем. Это может произойти при межгрупповом дисбалансе ковариат – существенных признаков, независимо (от проводимого вмешательства) влияющих на исход эксперимента. Естественно, цель большинства схем рандомизации – не только выровнять группы количественно, но и минимизировать указанный дисбаланс ковариат. К сожалению, полная рандомизация не позволяет добиться этого. Более того, сопутствующее проведение стратификации в данном случае бессмысленно, поскольку вероятность дисбаланса ковариат при полной рандомизации после стратификации равна таковой без стратификации [32]. При всем том, очень хорошего баланса ковариат можно добиться при использовании стратификации вместе с простой рандомизацией (см. выше), что на практике означает разбиение общей группы испытуемых на подгруппы по наличию / отсутствию / выраженности тех либо иных ковариат (страт) с последующим проведением простой рандомизации в полученных однородных подгруппах, с условием (назовем его ограничением), что общее количество больных внутри каждой подгруппы, получающих любую из сравниваемых схем лечения, должно быть одинаковым.
Стратификация – процесс разделения лиц, включаемых в РКИ, на подгруппы по признаку наличия либо отсутствия каких-либо факторов, могущих независимо от проводимого вмешательства повлиять на исход исследования (рост, вес, возраст, пол, сопутствующие заболевания и т.п.), после чего внутри полученных однородных подгрупп проводится рандомизация. Например, известно, что при лечении наркомании пол больного влияет на исход независимо от проводимой терапии; в этом случае пол может быть использован как фактор для стратификации. При этом группа мужчин отделяется от группы женщин, после чего внутри каждой группы проводится рандомизация в подгруппы, получающие различные режимы терапии; в дальнейшем сравнение эффективности указанных режимов производится независимо в обоих группах. При таком подходе удается надежно (благодаря рандомизации) оценить эффективность различных схем лечения наркомании для каждого пола в отдельности [23]. Таким образом, можно считать, что стратификация способствует уменьшению случайных ошибок (accidental bias) при формировании групп. Под «случайными ошибками» понимают систематические ошибки, обусловленные неравномерным распределением в сравниваемых группах известных либо неизвестных факторов, независимо влияющих на исход планируемого испытания. Строго говоря, стратификация используется для достижения сбалансированного распределения ковариаций в сравниваемых группах. Соответственно, все различия в наблюдаемых исходах становится возможным объяснить только различием вмешательств, имевших место в сравниваемых группах. Еще одно преимущество стратификации - возрастание мощности (power) статистических исследований. Мощность, напомним, определяется как минимальный уровень истинной разницы между группами, который можно выявить в данном исследовании с учетом особенностей его дизайна. Так, при наличии в исследовании 100 человек его мощность при условии стратифицированной рандомизации выросла почти на 12%. Снижается также вероятность ошибок I и II типов при выполнении статистической обработки результатов [23]. Тем не менее, стратификацию желательно проводить по минимальному количеству факторов, действительно существенно влияющих на исходы - при этом сам процесс стратификации упрощается; кроме того, чрезмерная стратификация приводит к дисбалансу в распределении схем вмешательств, поскольку большое количество факторов стратификации (страт) приводит к малому размеру результирующих подгрупп. Пока количество страт достаточно мало, у стратификации нет недостатков.
Перестановка блоков (permuted blocks) – пример исходно ограниченной схемы рандомизации. Данный метод предотвращает дисбаланс количественного состава групп посредством введения ограничительного условия – полного равенства размера образующихся при рандомизации групп сравнения. Простая рандомизация, упомянутая выше, тоже имеет подобное ограничение; тем не менее, размер формируемых данным способом групп может оказаться неодинаковым вплоть до момента набора нужного количества больных в каждую из них. Принцип метода перестановки блоков состоит в следующем: из всех вариантов распределения больных по группам, повторенных требуемое количество раз, формируется т.н. блок. Размер блока произволен, но общее количество вариантов в блоке должно быть кратно количеству сравниваемых вмешательств. Например, если требуется быстро распределить больных по группам А и В так, чтобы размер обеих групп все время оставался одинаковым, можно распределять в обе группы по 2 больных на каждом этапе рандомизации; при этом размер блока будет равен 4. Существует 6 вариантов взаимного расположения «А» и «В» в таком блоке: AABB, ABAB, ABBA, BBAA, BABA, BAAB. В процессе распределения больных по группам один из таких блоков выбирается случайным образом (например, компьютером, либо экспериментатор, непосредственно осуществляющий рандомизацию, выбирает неподписанный конверт из тщательно перетасованной пачки таких же, вскрывает его и достает оттуда карточку – схему блока рандомизации). Понятно, что в данном случае проходят процедуру рандомизации одновременно 4 человека, причем в каждую из формируемых групп попадут 2 из них. При размере блока 2 и наличии двух альтернативных вмешательств А и В рандомизация перестановкой блоков, по сути, сводится к простой, или полной рандомизации (см. выше). Размер блока может быть и более четырех – 6, 8, 10 и т.п., в соответствии с потребностями исследователей; при этом он должен оставаться кратным количеству сравниваемых вмешательств (в данном случае 2 – А и В). Существует разновидность данного метода, когда внутри каждого блока производится независимая рандомизация вариантов распределения больных в группы в желаемой пропорции, например, 1: 2 или 1: 3. Существует также вариант метода, называемый «перестановка случайных блоков» – в этом случае случайным образом меняется размер самих блоков (в рамках решаемой задачи, оставаясь кратным числу сравниваемых вмешательств), причем размер каждого последующего блока остается неизвестен исследователям. Рандомизация участников исследования последовательными блоками – пример дизайна, сохраняющего баланс сравниваемых групп на протяжении всего исследования. Тем не менее, обеспечивается только баланс количественного состава групп, но не важных характеристик больных. Кроме того, данный дизайн может вносить элемент предопределенности в формирование групп при несоблюдении условия сокрытия рандомизации из-за наличия периодически повторяющихся элементов в конце каждого блока. Например, представим себе клиническое испытание, где производится рандомизация в 3 группы блоками по 6 больных. В этом случае, если первые 5 номеров в блоке имеют последовательность 2, 3, 1, 1, 2, то шестым с неизбежностью окажется номер 3, что делает распределение предсказуемым. Данный недостаток (разновидность selection bias) отчасти преодолевается использованием случайного размера собственно блоков (именно такая разновидность данного метода и называется permuted blocks design – дизайн с перестановкой блоков). В конечном итоге, рандомизация блоками не предоставляет возможностей для достижения баланса существенных признаков (ковариат – см. выше) в формируемых группах. С указанной целью можно использовать стратифицированную рандомизацию блоками, когда данная схема применяется после стратификации, последовательно в каждой страте (см. «стратификация»). При этом количество страт должно быть ограничено, поскольку дизайн с перестановкой блоков рассчитан на максимальный размер отдельного блока, кратный суммарному количеству уровней стратифицирующих факторов-ковариат (т.е. страт). При этом чем больше размер отдельных блоков, тем выше вероятность возникновения дисбаланса формируемых групп (особенно при их небольшом и не кратном величине блока размере). В итоге, стратифицированная рандомизация перестановкой блоков может создать приблизительный баланс распределения схем вмешательств в каждой из страт; тем не менее, исследование в целом может характеризоваться определенным дисбалансом состава групп в случае, если количество страт велико либо размер блоков значителен по сравнению с числом больных, включенных в испытание [22]. Кроме того, данная модификация неудобна при работе с малыми группами. Главное преимущество титульного дизайна – простота применения, что не относится к стратифицированной рандомизации перестановкой блоков, которая может быть осуществлена без ошибок только при наличии соответствующего программного обеспечения. Тем не менее, после определения стратифицирующих факторов, размера блока и количества формируемых групп схема распределения может быть полностью расписана до начала клинических испытаний, после чего она остается статической в продолжение всего исследования. Правильный анализ результатов исследования должен учитывать все использованные стратифицирующие факторы и размер блока.
Модель избирательной урны (urn model) – одна из наиболее сложных схем рандомизации; тем не менее, при правильном применении она обеспечивает лучший баланс численного состава групп, чем полная рандомизация (особенно при работе с малыми группами), и в то же время не страдает излишней предсказуемостью, как метод перестановки блоков. Модель избирательной урны удобна также для тех случаев, когда размер формируемых групп на момент начала исследования еще не определен. Принцип модели избирательной урны состоит в следующем: исследователи используют непрозрачную емкость («урну»), реальную или ее компьютерную модель. В урне имеются шары различных цветов, каждый цвет соответствует одной из формируемых групп. Исходное количество шаров разного цвета в урне всегда одинаково (в том числе оно может быть равным нулю). В наиболее простой ситуации мы формируем две группы. В этом случае у нас в урне имеются шары двух цветов – например, красного и синего. Если исследователь вытаскивает из урны красный шар – больной определяется в группу А, если синий – в группу В. Метод работает следующим образом: если из урны извлечен шар красного цвета, то больной направляется в группу А, красный шар возвращается обратно в урну, после чего в урну добавляются один или несколько (всегда одинаковое, заранее оговоренное количество) шаров синего цвета. Принцип метода состоит в том, что после выбора больного в одну из групп шансы следующего больного попасть в другую группу искусственно несколько повышаются (степень повышения зависит от количества добавленных шаров соответствующего цвета), что и обеспечивает в конечном итоге существенно бóльшую вероятность баланса количественного состава формируемых групп, чем в случае простой (полной) рандомизации. В случае, если формируется более двух групп, принцип не меняется – извлеченный шар определенного цвета возвращается назад, после чего в урну вносится определенное одинаковое количество шаров всех остальных цветов. По сути, модель избирательной урны – усложненная разновидность упоминавшегося ранее дизайна «асимметричная монета» (biased coin). Общее количество шаров каждого цвета, находящихся в урне на момент начала рандомизации, принято обозначать как α, а количество шаров другого цвета (цветов), добавляемое после каждой итерации рандомизации – как β. Один из наиболее простых вариантов реализации модели избирательной урны, когда α=1 и β=1, приведен на рисунке 13.
Рис. 13. Иллюстрация принципа работы модели избирательной урны (по [50]).
В случае, когда α=0, β>0, т.е. исходно урна шаров не содержит, первый больной распределяется в какую-либо из групп по результату настоящего или смоделированного броска «идеальной», т.е. симметричной, монеты. После этого в урну добавляется заданное количество шаров другого цвета (цветов), и процесс рандомизации продолжается как описано выше. Согласно модели Фридмана (Friedman, 1949), вероятность, с которой больной попадает в группу А, вычисляется по формуле:
где: α, β≥0, причем либо α, либо β обязательно больше 0; φ(Dn, n) – собственно, вероятность распределения в группу А; n – предполагаемое количество больных в обоих формируемых группах; Dn – величина дисбаланса между формируемыми группами (человек), причем Dn=n(A) − n(B); α – общее количество шаров каждого цвета, находящихся в урне на момент начала рандомизации; β – количество шаров другого цвета (цветов), добавляемое после каждого шага рандомизации.
Вероятность, с которой больной попадет в группу В, вычисляется как 1 − φ(Dn, n). Принято считать, что при проведении простой (полной) рандомизации и достаточно большой величине n обе вероятности стремятся к 0,5. В случае модели избирательной урны φ(Dn, n) монотонно снижается с возрастанием дисбаланса Dn при фиксированном n и стремится к 0,5 с возрастанием n при фиксированном Dn (см. рис. 14, 15).
Рис. 14. График вероятности попадания произвольного больного в группу А. α = 10, β = 5, n = 30.
Рис. 15. График вероятности попадания произвольного больного в группу А. α = 10, β = 5, n = 3000.
Для случая, когда α=0, β>0, величина φ(Dn, n) не зависит от величины β, а схема рандомизации может быть сведена к классической перестановке блоков (см. выше), когда имеется только один блок с размером, увеличивающимся на одну и ту же величину при каждом шаге рандомизации. Такой вариант метода обеспечивает хороший количественный баланс формируемых групп, особенно при небольших n (рис. 16). В этой связи вариант метода (α=0, β>0) предпочтительнее при рандомизации больных в небольшие группы.
Рис. 16. График вероятности попадания произвольного больного в группу А. α = 0, β = 5, n = 15.
В случае, когда α>0, β=0, модель избирательной урны сводится к схеме простой (полной) рандомизации, и φ(Dn, n)=0,5 независимо от величины Dn (см. рис. 12). Та же ситуация наблюдается при β>0, если n стремится к бесконечности (см. рис. 17).
Рис. 17. График вероятности попадания произвольного больного в группу А. α = 100, β = 0, n = 50.
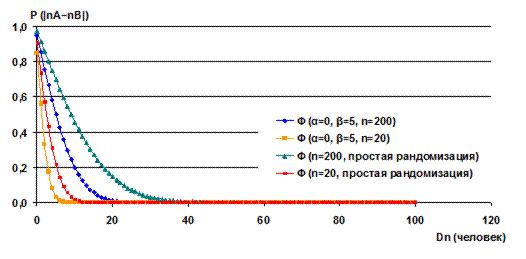
Из вышеприведенных рисунков видно, что для модели избирательной урны (при β>0) характерно существенное снижение вероятности распределения больного в группу А, если в этой группе больше больных, чем в группе В, причем эта вероятность тем меньше, чем больше величина дисбаланса. В то же время, в случае простого (полного) распределения φ(Dn, n) всегда равна 0,5 независимо от текущей величины дисбаланса групп, поскольку результат последующего «броска симметричной монеты» совершенно не зависит от результата предыдущего броска, что является одной из аксиом теории вероятности. Вероятность появления количественного дисбаланса в формируемых группах при использовании модели избирательной урны описывается формулой:
причем
где: P (|nA−nB|) – вероятность количественного дисбаланса формируемых групп; Φ – стандартная функция нормального распределения; d – величина дисбаланса групп А и В (человек); n – предполагаемое количество больных в обоих формируемых группах; α – общее количество шаров каждого цвета, находящихся в урне на момент начала рандомизации; β – количество шаров другого цвета (цветов), добавляемое после каждого шага рандомизации.
Используя представленную формулу, легко рассчитать, что вариант дизайна (α=0, β>0) выгодно использовать для рандомизации больных в небольшие группы, поскольку он обеспечивает лучший количественный баланс малых групп, чем полная рандомизация, и в то же время бóльшую случайность распределения больных по группам, чем метод перестановки блоков (причем качество рандомизации не зависит от соотношения численности группы и размера блока). При этом с увеличением n вероятность дисбаланса становится еще ниже, чем в случае простой (полной) рандомизации (см. рис. 18); при (α>0, β>0) вероятность появления дисбаланса в больших группах уменьшается еще значительнее.
Рис. 18. Сравнение эффективности модели избирательной урны и простой (полной) рандомизации для распределения больных в большие и малые группы [21].
Практические эксперимента показали, что при α=1 увеличение β с 1 до 5 приводило к повышению баланса групп, при β>5 существенного улучшения баланса не наблюдалось. При больших величинах α (вплоть до 500) улучшение балансировки групп наблюдалось при возрастании β до 12-13, при дальнейшем повышении β разница дисбалансов всякий раз оказывалась незначимой [50]. Кратко резюмируя особенности обсуждаемого дизайна, следует отметить, что: · При α=0, β>0 вероятность дисбаланса не зависит от величины β; · При β÷α → 0 модель избирательной урны не отличается от схемы простой (полной) рандомизации; · При α>0, β÷α >1 и средних по размеру группах дальнейшее увеличение β не приводит к заметному снижению вероятности дисбаланса; · При β÷α → ∞ (включая вариант, когда α=0) метод урны хорошо сохраняет баланс между малыми группами.
У рассматриваемого метода имеются и некоторые недостатки: 1. Техника выполнения данного варианта рандомизации сложна, сравнительно трудна для понимания, требует наличия в исследовательской группе статистика; кроме того, ход рандомизации невозможно спланировать до начала исследования – это по условию динамический процесс (правда, это удобно, если на момент начала исследования конечный размер сравниваемых групп еще неизвестен); 2. Не всегда удается создать баланс ковариат в группах (как и в случае рандомизации перестановкой блоков); соответственно, может потребоваться предварительная стратификация по существенным для результатов исследования признакам с последующей изолированной рандомизацией в пределах каждого из уровней стратифицирующего фактора.
Адаптивные (приспособительные) модели рандомизации включают в себя ковариативные адаптивные (covariative adaptive) и реактивные адаптивные (response adaptive) модели.
Ковариативная адаптивная рандомизация используется в случае, если количество формируемых групп сравнимо с количеством участников исследования, набираемых в группы (т.е. размер формируемых групп мал). При этом статические схемы рандомизации, описанные выше, в принципе могут обеспечить количественный баланс формируемых групп (например, рандомизация методом переставленных блоков (permutted blocks) либо методом избирательной урны – urn model), но неспособны гарантировать баланс важных для эксперимента характеристик больных (ковариат) в каждой из групп, что приведет к невозможности корректного сравнения полученных в исследовании результатов. Так, например, если мы формируем две группы сравнения по 30 человек в каждой, при условии, что изучаемый нами признак имеется у 30% населения, дисбаланс данного признака на этапе формирования групп при использовании простой (полной) рандомизации составит более 10% с вероятностью 0,45. Для коррекции данного явления обычно применяется стратификация по всем существенным ковариатам с последующей блоковой рандомизацией внутри полученных страт, но увеличение количества ковариат неизбежно приведет к уменьшению числа полных блоков в пределах одной страты (см. выше), что нивелирует эффект от подобного рода манипуляций. В настоящее время не рекомендуется использовать стратификацию более чем по 3-4 существенным признакам [26]. Соответственно, принцип ковариативной адаптивной рандомизации заключается в том, что каждый новый субъект, включаемый в исследование, распределяется в одну из формируемых групп с учетом баланса важных для исследования признаков больных, сложившихся в группах на момент его включения. При этом соотношение важных ковариат постоянно мониторируется; дисбаланс по каждой из ковариат выявляется попарным сравнением групп методом χ2 (хи квадрат) Пирсона. Новый субъект распределяется в ту из групп, в которой значение контролируемых ковариат (с учетом вклада включаемого субъекта) даст наименьшее максимальное отклонение от исходно запланированных величин соотношений данных ковариат. Ковариативная адаптивная рандомизация имеет ряд разновидностей: 1. Метод минимизации. Классический метод минимизации предполагает построение функций индивидуального баланса для каждого из учитываемых существенных факторов и функции общего баланса для всего исследования, причем переменными этих функций являются, в числе прочих, значения вероятности (р) назначения больному той или иной терапевтической схемы. При этом каждый новый больной, включаемый в исследование, оценивается на предмет уровней мониторируемых ковариат, данные уровни подставляются в вышеописанные формулы, и больной распределяется в ту из формируемых групп, где величина рассчитанного по соответствующей формуле дисбаланса ковариат окажется минимальной, а вероятность р – соответственно, максимальной [43]. Данный способ позволяет сбалансировать формируемые группы по 10-20 существенным факторам (ковариатам), что абсолютно недостижимо при использовании стратификации. К недостаткам метода относятся: · Предопределенность (детерминированность) получаемых результатов: в каждый момент времени можно предсказать, в какую из групп будет распределен конкретный пациент. Существуют сложные математические способы, отчасти устраняющие данную проблему (например, с использованием множителей Лагранжа [30]). · Данный метод рандомизации сложен на этапе подготовки к проведению исследования и требует наличия в исследовательском штате квалифицированных математиков и статистиков. Существует ряд коммерческих программ и плагинов (в основном к известным программам статистического анализа данных – SPSS, SAS), позволяющих облегчить либо опустить данный этап подготовки. · Перечень рандомизации невозможно сгенерировать заранее, перед началом исследования. Это – общий недостаток динамических моделей рандомизации: каждая последующая итерация распределения участников по группам зависит от всех предыдущих; соответственно, при каждом новом эпизоде рандомизации приходится вновь запускать алгоритм минимизации. · При неправильной оценке уровней мониторируемых ковариат у включаемого в исследование больного он будет распределен в неверную группу; при этом общий баланс ковариат в формируемых группах нарушится, причем неявно для исследователей. · В процессе исследования больные могут по разным причинам выйти из него, покинув свои группы, что явным образом приведет к нарушению достигнутого баланса ковариат. · Алгоритм минимизации может быть реализован с ошибками на программном уровне; описан случай дефектного распределения более чем 1000 женщин в сравниваемые группы до выявления ошибки в алгоритме [14]. Данная проблема отчасти преодолевается неоднократным тестовым запуском рабочего алгоритма до начала исследования с вдумчивым анализом получаемых результатов.
2. Метод максимальной энтропии. Принцип «максимальной энтропии» постулирует, что распределение вероятностей, наиболее соответствующее имеющейся информации (исходно предполагается, что данной информации недостаточно для полной оценки вероятности ожидаемого события) – это распределение, обладающее максимальной энтропией [17]. Предполагается также, что информация объективна и поддается проверке, а вероятности – взаимоисключающие (как, например, вероятность включения в группы сравнения – войдя в какую-либо из групп, больной уже не может быть приписан ни к одной из оставшихся). Алгоритм адаптивной рандомизации, основанный на данном принципе, предполагает написание формулы оценки энтропии исследуемых групп, исходя из совокупности значений мониторируемых факторов (ковариат); количество учитываемых факторов не ограничивается. При каждом новом запуске алгоритма (т.е. при включении в исследование каждого нового участника) производится оценка параметров, интересующих исследователей; полученные значения подставляются в формулу определения энтропии, последовательно для каждой из формируемых групп, с учетом сложившегося в них на момент данного эпизода рандомизации соотношения ковариат; больной будет причислен к той из групп, где подсчитанная величина энтропии окажется максимальной (т.е. где параметры включаемого больного окажут наименьшее влияние на сложившийся баланс ковариат). Данный метод рандомизации имеет те же достоинства и недостатки, что и вышеописанный метод минимизации.
3. Метод минимального правдоподобия. Упомянутая ранее рандомизация по методу минимального правдоподобия (minimal likelihood) используется крайне редко.
Реактивная адаптивная (response adaptive) рандомизация предполагает целенаправленное изменение правил распределения новых участников исследования по группам сравнения в зависимости от особенностей реакции уже вовлеченных в исследование лиц на изучаемые воздействия. Данная разновидность рандомизации предпочтительна с этической точки зрения в тех клинических испытаниях, где производится сравнение методов диагностики и, особенно, лечения серьезных жизнеугрожающих заболеваний и состояний, причем один из методов может оказаться существенно более эффективным, чем сравниваемые с ним. В этом случае становится неэтичным подвергать опасности жизнь и здоровье остальных участников исследования, и схема рандомизации новых участников, последовательно включаемых в клиническое испытание, должна предусматривать искусственное повышение вероятности их попадания в группу больных, получающих наиболее эффективное лечение из сравниваемых; при этом приходится считаться с тем, что на момент начала испытания даже приблизительное соотношение эффективности сравниваемых схем лечения еще неизвестно. Такая схема рандомизации получила название «игра на лидера» («play the winner»). Наиболее простая ее разновидность, описанная Zelen (1969 г.) [36], предусматривала рандомизацию в 2 группы, причем имелось 2 взаимоисключающих исхода лечения – «успех» и «неудача». Распределение каждого нового участника исследования (n) в одну из двух групп определялось результатом исследуемого вмешательства у предыдущего (n–1) участника: если оно было успешным, то участник n распределялся в ту же группу, что и n–1, а если безуспешным – то в другую группу. Такая схема рандомизации получила название «все или ничего» («all-or-none»). В настоящее время известен ряд модификаций данного подхода, допускающих сравнение 3-х и более схем лечения, а также учитывающих отдаленные эффекты лечения (не всегда в клинической практике успех или неудача терапии очевидны сразу после прохождения курса лечения; кроме того, учитываемый исход (endpoint) может не успеть развиться за время непосредственного наблюдения за субъектом «n–1»). Несмотря на очевидный детерминизм, «игра на лидера» остается стохастическим процессом, так как определяется успехом либо неудачей исследуемых вмешательств в каждом из случаев. Наиболее традиционный подход к реализации «игры в победителя» - модифицированная модель избирательной урны Фридмана, подробно описанная ранее. Принцип подхода заключается в том, что, если из урны извлекается шар А, то больной приписывается к группе, получающей схему лечения А, а шар возвращается обратно в урну. Если лечение было эффективно, и зарегистрирован его «успех», в урну дополнительно подкладывается рассчитанное (не обязательно целое) количество шаров А, что в итоге повышает шанс каждого следующего больного, включаемого в клиническое испытание, попасть при рандомизации в группу А. Если же лечение А оказывается неэффективным (т.е. зарегистрирована «неудача»), в урну подкладывается соответствующее количество шаров других групп (В, С и т.д.), что понижает шансы распределения следующих больных в группу А, но повышает – во все остальные группы. Аналогично поступают, если из урны был извлечен шар В, С и т.д. При этом на момент начала процесса рандомизации оптимально наличие в урне по одному шару каждой группы (α=n, где n – количество формируемых групп), поскольку в этом случае влияние результатов сравниваемых схем терапии на распределение по группам последовательно включаемых в испытание больных проявляется наиболее полно. Наиболее сложным элементом данного подхода является определение количества шаров разного цвета, добавляемых в урну в случае успеха или неудачи сравниваемых схем терапии; это количество может быть дробным и (обычно) динамически изменяется в ходе исследования по мере уточнения реальной эффективности сравниваемых схем терапии. В наиболее простом варианте, предложенном Bai, Hu и Shen [51], в случае успеха терапевтической схемы (н-р, А) в урну добавляется один дополнительный шар А, а также нецелочисленное количество шаров других цветов, равное 1/(n–1), где n – общее количество формируемых групп. Ясно, что подобная схема далека от идеала, поскольку не учитывает кумулятивную эффективность соответствующей схемы терапии, что признают и сами авторы. Более совершенные алгоритмы, наподобие предложенных Lecoutre и Elqasyr [12], отличаются значительной сложностью математических построений, выходящих за рамки настоящего руководства, но и качество рандомизации, проводимой при помощи подобных моделей, существенно выше. Так, при условии наличия двух сравниваемых методов лечения, вероятность успеха при использовании которых в реальности составляет 60% и 80%, и 50 больных, вышеупомянутый алгоритм Lecoutre и Elqasyr позволяет достичь распределения 64,9-66,1% участников исследования в группу с более эффективным терапевтическим воздействием; при этом асимптотическая («идеальная») пропорция данных лиц составляет 66,7%. Существует также относительно удачная реализация указанного алгоритма, основанная на теореме Байеса (Bayesian adaptive randomization) [13]. К недостаткам описанного способа рандомизации, кроме приведенных выше (см. описание метода минимизации), относится также и некоторые неотъемлемые его черты, как-то: · Преимущественная ориентация на методы лечения, дающие немедленный положительный либо отрицательный исход (т.е. к моменту окончания курса терапии), т.к. учет отдаленных результатов лечения сложен даже при использовании продвинутых алгоритмов рандомизации. · Значительная продолжительность процесса рандомизации, т.к. каждый последующий участник испытания может быть распределен в какую-либо из сравниваемых групп только после формирования определенного исхода вмешательства у предыдущего участника; этот факт также затрудняет регистрацию отдаленных результатов терапии.
В целом следует отметить, что адекватное использование адаптивных моделей рандомизации, равно как и модели избирательной урны, требует наличия в исследовательской группе квалифицированного математика со знанием прикладной медицинской статистики, а также подготовленного программиста с опытом работы с большими массивами данных.
Важным элементом рандомизации является сокрытие ее результатов, или т.н. «ослепление» (blinding). Как упоминалось выше, РКИ признается «золотым стандартом» доказательной медицины именно потому, что включает в себя этап рандомизации, который максимально устраняет систематические ошибки при формировании сравниваемых групп. Указанные ошибки заключаются прежде всего в дисбалансе количественного и качественного состава сравниваемых групп, а также дисбалансе ковариат (т.е. важных характеристик участников исследования, существенных для анализа и понимания полученных результатов). Главную роль в возникновении указанного дисбаланса играют персональные пристрастия врачей-экспериментаторов (которые по каким-либо причинам, нередко – совершенно субъективным, питают те или иные личные симпатии или антипатии к определенным медикаментозным препаратам) и вкусы больных, предпочитающих тот или иной метод лечения другому, нередко на основании совершенно вздорных домыслов, догадок и слухов. С целью исключения личного субъективизма как участников испытания, так и экспериментаторов и производится сокрытие (ослепление) результатов рандомизации. Сокрытие результатов рандомизации включает в себя ряд практических аспектов: 1. Сокрытие рандомизационных кодов. Осуществляется обычно в двух вариантах: а) участник исследования, непосредственно осуществляющий рандомизацию в группы при регистрации новых участников (например, врач приемного покоя стационара) получает из центра управления ходом РКИ немаркированные заклеенные конверты, в каждом из которых содержится один рандомизационный код, сгенерированный каким-либо из вышеописанных способов. Указанный код не должен иметь ничего общего с названием препаратов или инструментальных вмешательств, производимых в соответствующей формируемой группе сравнения; в идеале указанный код должен представлять собой внешне бессмысленное буквенно-цифровое сочетание. При регистрации каждого нового участника исследования экспериментатор извлекает из контейнера очередной конверт, вскрывает его, читает рандомизационный код и распределяет больного в соответствующую группу. Как вариант, возможно использование специально сгенерированной таблицы псевдослучайных чисел, которые последовательно используются для рандомизации участников РКИ в группы и вычеркиваются из таблицы после однократного использования. б) В случае, если рабочее место экспериментатора, осуществляющего рандомизацию, оснащено компьютером, связанным с сервером центра управления РКИ через Интернет или какого-либо еще рода сеть, возможно использование специальной клиентской программы, при помощи которой сотрудник мог бы при необходимости отправлять серверу соответствующий запрос; по получении указанного запроса на сервере производится запуск алгоритма рандомизации, и результат (сгенерированный в реальном времени рандомизационный код) отправляется обратно на компьютер исследователя, после чего его можно визуализировать при помощи клиентской части программы. Такого рода подход удобен при осуществлении динамических схем рандомизации, где результат каждой следующей итерации зависит либо от совокупности характеристик больных, ранее включенных в исследование, либо от исхода исследуемого вмешательства у ранее включенного в испытание участника, вследствие чего рандомизационные коды нельзя подготовить заранее, до начала исследования. В идеале расшифровка рандомизационных кодов должна находиться в руках только организаторов или даже только спонсоров исследования (если речь идет об испытаниях лекарственного препарата); ни больные, ни непосредственно осуществляющие рандомизацию и изучаемые вмешательства исследователи, ни даже статистик, производящий обработку полученных результатов, не должны знать, какие именно вмешательства имели место в соответствующих сравниваемых группах. Раскрытие рандомизационных кодов до полного завершения РКИ и обработки его результатов не допускается; в исключительных случаях, оговоренных в протоколе исследования, такое раскрытие (с обязательным официальным извещением организаторов и/или спонсоров исследования) все же может иметь место; обычно это происходит в том случае, если предварительный (промежуточный) анализ результатов эксперимента показал явное, существенное и статистически значимое преимущество какого-либо одного из сравниваемых вмешательств, либо выявил высокую частоту неблагоприятных исходов, побочных эффектов и опасных осложнений при применении какого-либо из тестируемых методов лечения. В обоих случаях дальнейшее проведение исследования с использованием прежнего протокола неэтично и сопряжено с опасностью для жизни и здоровья участников эксперимента, вследствие чего целесообразно раскрыть рандомизационные коды и либо 1) назначить всем больным лечение, оказавшееся наиболее эффективным, либо 2) отменить препарат / прекратить вмешательство, ведущие к неблагоприятным исходам и осложнениям исследуемого заболевания либо состояния. В целях своевременного выявления подобного развития событий в протоколе РКИ обязательно необходимо предусмотреть этапы исследования, на которых будет производиться промежуточный анализ его результатов, и действия, которые будут предприняты экспериментаторами при обнаружении соответствующих тенденций. 2) Сокрытие применяемых схем терапевтических вмешательств. С целью исключения субъективности при оценке результатов РКИ, а также для предотвращения выхода больных из исследования вследствие несогласия с проводимой терапией необходимо так организовать работу, чтобы ни больные, ни врачи, непосредственно выполняющие сравниваемые вмешательства, не могли догадаться по виду и количеству назначенных больным препаратов, какое именно лечение получают подопытные лица в той или иной группе; это касается и контрольной группы, которая, как указывалось выше, является неотъемлемым элементом дизайна РКИ. Необходимо учитывать также т.н. «плацебо-эффект», имеющий место у большинства людей при назначении им медикаментозных препаратов: у многих больных состояние может несколько (у наиболее внушаемых и эмоционально лабильных лиц – иногда даже значительно) улучшиться под влиянием самого факта назначения лечения как такового, независимо от его реальной эффективности. Плацебо-эффект может вносить существенный вклад в клинические проявления активности того или иного препарата, причем не только в его позитивное действие: существует довольно обширная группа (до 30-35% популяции) т.н. «плацебо-реакторов», которые могут реагировать на назначение любой медикаментозной терапии появлением тошноты и рвоты, повышенной утомляемости, головной боли и т.п., что симулирует побочные эффекты лекарства. В основе плацебо-эффекта лежит самовнушение, в некоторых случаях достигающее степени самогипноза. Понятно, что для нивелирования «эффекта плацебо» больные в контрольной группе должны получать такие же по виду и количеству «препараты», что и во всех опытных группах. Соответственно, в опытных группах количество и вид получаемых каждым больным препаратов / инвазивных манипуляций также должны быть абсолютно идентичны. Маскирование вида хирургических вмешательств проблематично; что же касается испытаний медикаментозных препаратов, то фармацевтические компании, заказывающие такое испытание, специально для РКИ выпускают партии сравниваемых лекарств в идентичной упаковке, маркированной только соответствующим рандомизационным кодом; сами таблетки и/или капсулы выглядят абсолютно идентично, независимо от реально содержащегося в них препарата, и либо маркированы рандомизационным кодом, непонятным непосвященному, либо вообще не маркированы. Для назначения в контрольной группе специально выпускается т.н. плацебо – вещество, не имеющее никаких терапевтических действий, но неотличимое от лекарства по виду, вкусу, массе, цвету, запаху и т.д. В идеальном случае плацебо действительно не содержит никаких медикаментозных препаратов (основу его может составлять, например, молочный сахар); такое средство предназначено исключительно для моделирования плацебо-эффекта в контрольной группе и называется инертным плацебо. В том случае, если плацебо содержит какой-либо действующий препарат, бесполезный или неэффективный при изучаемом заболевании, но в целом безвредный или условно-полезный для больного (например, витамины), оно называется активным плацебо. В случае, если лица в контрольной группе получают инертное либо активное плацебо, РКИ является рандомизированным клиническим испытанием с плацебо-контролем. Использование плацебо-контроля, являясь отраслевым стандартом, тем не менее, порождает этическую проблему, поскольку больные в контрольной группе фактически остаются вообще без лечения на все время исследования. В связи с этим в ряде испытаний применялся т.н. активный, или позитивный контроль. В этом случае в контрольной группе назначают схему лечения, включающую ранее разработанные препараты с известной эффективностью против изучаемого заболевания, и сравнение новой схемы / новых препаратов производится с уже известными. При этом данные препараты должны быть внешне неотличимыми от используемых в опытной группе (т.н. двойное маскирование). РКИ с активным контролем постоянно используют при оценке клинической эффективности лекарств-дженериков в сравнении с оригинальными препаратами. Интересно отметить, что выраженность плацебо-эффекта непосредственно зависит от органолептических свойств плацебо. Так, показано, что наибольшим анальгетическим эффектом обладают красные таблетки плацебо, несколько меньшим – синие, еще меньшим – зеленые, и наиболее низким – желтые [16]. Здесь, несомненно, играет свою роль расхожее представление обывателей о том, что в красный цвет окрашивают преимущественно сильнодействующие препараты, а в желтый – «обычные таблетки», которые «никогда не помогают». В некоторых случаях скрыть применяемые схемы терапии невозможно, например, если инвазивные (хирургические) методы лечения сравниваются с неинвазивными (терапевтическими), или если эффективность консультации психолога сравнивается с эффективностью антидепрессантов. Случаются ситуации, когда сокрытие применяемых схем лечения нежелательно, даже если и возможно, поскольку от исследователей требуют комплексно оценить весь «набор» медицинских услуг, включая их эффективность, удобство и доступность для больного. В любом случае, элементы «ослепления» могут иметь место в любом РКИ на этапе анализа исходов сравниваемых вмешательств. Исходя из использованных методов сокрытия результатов рандомизации и применяемых схем терапии, все РКИ подразделяются на: 1. Слепые – о результатах рандомизации и применяемых схемах терапии не знают только пациенты – непосредственные участники испытания; 2. Двойные слепые – ни пациент, ни врачи-исследователи не владеют информацией о результатах рандомизации и применяемых вмешательствах; 3. Тройные слепые – ни пациент, ни исследователи, ни фармацевты, поставляющие препараты для испытания, не знают результатов рандомизации. В этом случае рандомизационные коды известны только организаторам и/или спонсорам исследования; нередко их не знает даже статистик, производящий промежуточный и окончательный анализ результатов исследования. Отраслевым стандартом являются двойные слепые РКИ с плацебо-контролем; считается, что такой уровень сокрытия результатов рандомизации является достаточным для устранения субъективности при получении и анализе результатов исследования, а более строгое сохранение тайны существенно усложняет организацию и проведение экспериментов.
5. Следующий этап планирования РКИ – определение размера сравниваемых групп (т.е объема формируемой выборки из популяции) Размер формируемых групп сравнения имеет принципиальное значение при последующем анализе полученных в РКИ результатов. В процессе РКИ мы всегда проверяем некую гипотезу, например, что тестируемый нами препарат А лучше (или не хуже) ранее созданного препарата В, или что препарат А обладает клинической эффективностью, значимо превышающей эффект плацебо. При этом мы не можем включить в наши группы всю интересующую нас популяцию – мы вынуждены делать выборки из нее, вследствие чего получаемые нами результаты всегда характеризуются элементом неопределенности: мы никогда не можем быть уверенными на 100%, что сделанное нами заключение об истинности или ложности проверяемой гипотезы безошибочно. Предположим, мы производим сравнение эффективности двух гипотетических препаратов А и В. В сравниваемые группы нами включено по 10 добровольцев. По окончании исследования интересующий нас исход терапии наступил в 6 случаях в группе, получающей препарат А, и в 5 случаях в группе, получающей препарат В. Можно ли на основании полученных результатов утверждать, что препарат А более эффективен, чем препарат В? При сравнении точным тестом Фишера (Fisher's exact test) выявлено, что различия недостоверны (р=0,5); соответственно, приходится констатировать, что гипотеза, согласно которой препарат А более эффективен, чем препарат В, несостоятельна. Теперь предположим, что в группы А и В мы набрали по 100 добровольцев, причем нужный нам исход в группе А наступил у 60 больных, а в группе В – у 50. Анализ по критерию χ2 показывает, что межгрупповые различия и в этом случае остаются незначимыми, р=0,15 (обратите внимание на уменьшение величины р по сравнению с предыдущим примером). Наконец, предположим, что мы сформировали 2 группы сравнения (А и В), в каждой из которых насчитывается по 1000 человек, причем нужный исход наступил у 600 человек в группе А и у 500 – в группе В. В этом случае анализ межгрупповых различий по критерию χ2 показывает их высокую достоверность (р<0,0001). Таким образом, увеличение размеров сравниваемых групп от 10 до 1000 добровольцев позволило подтвердить гипотезу, согласно которой препарат А более эффективен, чем препарат В. Понятно, что с увеличением размеров сравниваемых групп статистическая значимость наблюдаемых в них различий в результатах сравниваемых вмешательств будет нарастать. Параллельно будет нарастать стоимость исследования и сложность его организации. Размер сравниваемых групп в 10000 человек каждая даст еще более значимые результаты сравнения, но будет разорительным для исследователей. Итак, при формировании групп мы должны достичь некоей золотой середины: когда размер групп уже достаточно велик для получения значимых результатов сравнения, и в то же время достаточно мал для того, чтобы стоимость исследования осталось в рамках сметы. Вторым аспектом данной проблемы является тот факт, что выборка (т.е. группа сравнения) формируется путем привлечения индивидуумов из популяции случайным образом. В связи с этим никто не может гарантировать, что картина распределения эффекта исследуемого вмешательства, наблюдаемая в генеральной совокупности (т.е. во всей популяции), хоть сколько-нибудь точно будет воспроизведена в сформированной выборке; при этом чем меньше размер формируемых групп, тем большее влияние
|

 ,
,



 ,
,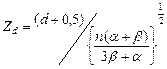 ,
,