
Распараллеливание независимых вычислений
Очень наглядным примером вычислений, распараллеливаемых по данным, является операция сложения векторов (или матриц). В этом случае однотипные данные, – компоненты векторов, - складываются независимо друг от друга, а результатом сложения является вектор, такой же, как векторы с исходными данными:
Центральный процессор персонального компьютера (CPU) решает эту задачу последовательным сложением всех компонент векторов
Для упрощения примера, мы не учитываем здесь то, что современные CPU являются суперскалярными, то есть – могут одновременно складывать несколько пар чисел, поскольку большого количества параллельных потоков данных они не обеспечивают. Без распараллеливания алгоритм программы для CPU имеет вид цикла:
Рис. 5.1. Последовательное сложение векторов С другой стороны, при наличии N процессоров, работающих параллельно, эту же задачу можно было бы решить в N раз быстрее, сложив на каждом из процессоров по одной из компонент векторов:
При меньшем, чем N количестве параллельных процессоров m < N сложение векторов всё равно возможно выполнить параллельно. Для этого можно разбить векторы на блоки по m чисел (что эквивалентно преобразованию векторов в двухмерные матрицы):
Представление соответствует сложению каждой из строк на отдельном процессоре:
Принцип распараллеливания однотипных и независимых вычислений - как раз и реализован на графических процессорах. Эти процессоры включают в себя десятки параллельных графических конвейеров, специально предназначенных для параллельного проведения одинаковых операций над числами с плавающей точкой. В примере - ко всем элементам матриц применяется одна и та же операция сложения. Это – пример принципа параллельного программирования называют SIMD (Single Instruction Multiple Data, одна инструкция для множества данных, см. раздел 4.3.4). Помимо собственно распараллеливания, этот принцип вычислений имеет и то преимущество, что позволяет избавиться от операций изменения управляющих переменных цикла (i в примере выше), проверки условия завершения цикла и выхода за границы массивов. Частичное разворачивание циклов (например, обработка в теле цикла сразу 4-х элементов) используется и для оптимизации вычислений на центральных процессорах, в частности - позволяет компилятору задействовать расширенные наборы SIMD команд типа SSE и 3dNow!. Всё же, на графических процессорах принцип SIMD реализован в гораздо более полной мере.
|
 .
.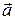 и
и  :
: .
.

 .
.



