
Москва 2012 г.
Определение Непрерывная случайная величина Х имеет показательный закон распределения с параметром
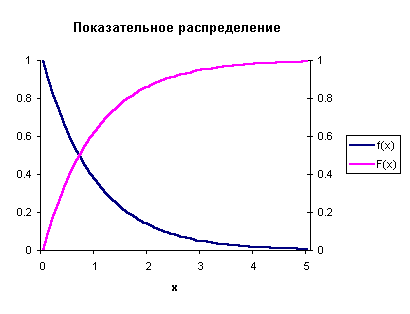
Кривая распределения
Рис 2. Получим выражение для функции распределения по формуле 1) При 2) При По соответствующим формулам получаем выражения для
Задача. Среднее время безотказной работы прибора равно 80 ч. Полагая, что время безотказной работы прибора имеет показательный закон распределения, найти: а) выражение его плотности вероятности и функции распределения; б) вероятность того, что в течение 100 ч. прибор не выйдет из строя. Решение. Х- время безотказной работы прибора, среднее время - Искомая вероятность
Замечание. Показательный закон распределения играет большую роль в теории массового обслуживания и теории надежности. МОСКОВСКИЙ ГОСУДАРСТВЕННЫЙ ИНСТИТУТ ЭЛЕКТРОНИКИ И МАТЕМАТИКИ Кафедра теории вероятностей и математической статистики РЕФЕРАТ По математической статистике на тему: «Равномерное распределение» Выполнил: студенты группы М-65 Ражева А.А. Кнутова А.С. Проверил:Заведующий Кафедрой Ивченко Г. И. Москва 2012 г.
Непрерывное равномерное распределение — в теории вероятностей распределение, характеризующееся тем, что вероятность любого интервала зависит только от его длины. Равномерное распределение полезно при описании переменных, у которых каждое значение равновероятно, иными словами, значения переменной равномерно распределены в некоторой области. Определение Говорят, что случайная величина имеет непрерывное равномерное распределение на отрезке [a,b], где
Пишут: X ~ U (a,b) или Иногда значения плотности в граничных точках x = a и x = b меняют на другие, например 0 или Если L (ξ) = U(a,b), то Равномерное распределение U (a,b) описывает процесс «выбора точки наудачу» в интервале [a,b]. Так, если [a,b] – интервал между последовательными отправлениями автобуса от остановки, то время ожидания пассажира, не знающего расписания и пришедшего на остановку, есть случайная величина с распределением U (0,1). Распределение U (0,1) играет особую роль в методах моделирования с помощью компьютеров случайных величин с заранее заданными распределениями. Такие методы широко используют для приближенных вычислений интегралов, решений дифференциальных и интегральных уравнений и т.д. Пример (Гипотеза случайности). В некоторых случаях априори предполагается (постулируется), что исходные данные представляют собой случайную выборку из некоторого распределения, т.е. компоненты вектора данных X=(
Функция распределения Интегрируя определённую выше плотность, получаем:
Так как плотность равномерного распределения разрывна в граничных точках отрезка [a,b], то функция распределения в этих точках не является дифференцируемой. В остальных точках справедливо стандартное равенство:
Характеристическая функция случайной величины X ~ U(a,b):
Математическое ожидание и дисперсия по определению равны:
Вообще,
Стандартное равномерное распределение Если a = 0, а b = 1, то есть X ~ U[0,1], то такое непрерывное равномерное распределение называют стандартным. Имеет место элементарное утверждение: Если случайная величина X ~ U[0,1], и Y = a + (b − a)X, где a < b, тo Y ~ U[0,1]. Таким образом, имея генератор случайной выборки из стандартного непрерывного равномерного распределения, легко построить генератор выборки любого непрерывного равномерного распределения. Более того, имея такой генератор и зная функцию обратную к функции распределения случайной величины, можно построить генератор выборки любого непрерывного распределения (не обязательно равномерного) с помощью метода обратного преобразования. Поэтому, стандартно равномерно распределённые случайные величины иногда называют базовыми случайными величинами.
Линейное преобразование переводит СВ X ~ R(a,b) в СВ Y ~ R(0,1). Действительно,
Равномерное распределение является непрерывным аналогом дискретного распределения вероятностей для опытов с равновероятными исходами.
Значение С помощью линейного преобразования приводится к равномерному распределению на отрезке [0,1]. Равномерное распределение является непрерывным аналогом распределений классической теории вероятностей, описывающих случайные эксперименты с равновероятными исходами.
Погрешность, происходящая от округления числа, удовлетворительно описывается равномерным распределением на отрезке [ − 1 / 2,1 / 2].
Если случайная величина ζ имеет непрерывную функцию распределения
Моделирование Обозначим буквой
Если Моделировать случайную величину Мы рассмотрим метод псевдослучайных последовательностей, который наиболее просто реализуется в компьютере. Для получения псевдослучайной последовательности используем алгоритм, который называется методом середины квадратов. Поясним его на примере. Возьмем некоторое число
Метод обратных функций. Пусть случайная величина
Отсюда следует, что значение
Последовательности значений Моделирование случайной величины с равномерным распределением на отрезке Пусть случайная величина Составляем уравнение Последовательности значений Порядковые статистики. Случайная величина Для случая
При этом:
А также:
Если же
А также:
Отметим далее, что если
Оценивание параметров в равномерном распределении. Введём статистический аналог теоретического математического ожидания случайной величины
Введём статистический аналог теоретической дисперсии случайной величины
Любая измеримая функция от выборки Статистика
Статистика
То есть для любого
ü Возьмём выборку Оптимальной несмещённой оценкой θ в данном классе оценок является:
Её дисперсия:
ü Оценим теперь параметр θ равномерного распределения Статистики Кроме того, имеем:
ü Пусть теперь
Достаточные статистики и оптимальные оценки. Если для любой оценки Итак, T* - оптимальная оценка для параметрической функции
Статистика
Теорема Рао-Блекуэлла-Колмогорова: Оптимальная оценка, если она существует, является функцией от достаточной статистики. Теорема: Если существует полная достаточная статистика, то всякая функция от неё является оптимальной оценкой своего математического ожидания. То есть оптимальная оценка однозначно определяется уравнением Функция Критерий факторизации. Для того, чтобы статистика была достаточной для параметрического семейства распределений P, необходимо и достаточно, чтобы функция правдоподобия выборки
Где множитель h(x) от
ü Пусть
ü Пусть теперь
ü Статистика Если Аналогично, если Этими двумя случаями исчерпываются ситуации, когда в модели Для модели
|
 , если ее плотность вероятности
, если ее плотность вероятности  имеет вид
имеет вид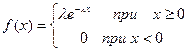 (5)
(5)
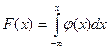 .
.
 .
.
 .
. и
и  .
. (6);
(6);  (7);
(7);  (8);
(8);  (9)
(9)
 , тогда по формуле (7)
, тогда по формуле (7)  и по (5)
и по (5)  ;(6)
;(6)  .
.
 , если её плотность имеет вид:
, если её плотность имеет вид:

 . Так как интеграл Лебега от плотности не зависит от поведения последней на множествах меры нуль, эти вариации не влияют на вычисления связанных с этим распределением вероятностей.
. Так как интеграл Лебега от плотности не зависит от поведения последней на множествах меры нуль, эти вариации не влияют на вычисления связанных с этим распределением вероятностей.
 независимы и одинаково распределены. Как правило, это предположение бывает оправдано, так как вытекает из самого характера задачи, и не подвергается сомнению. Но иногда это исходное предположение само нуждается в проверке, т.е. оно рассматривается как статистическая гипотеза
независимы и одинаково распределены. Как правило, это предположение бывает оправдано, так как вытекает из самого характера задачи, и не подвергается сомнению. Но иногда это исходное предположение само нуждается в проверке, т.е. оно рассматривается как статистическая гипотеза 
 , называемая гипотезой случайности. Формализуется такая гипотеза следующим образом. Пусть
, называемая гипотезой случайности. Формализуется такая гипотеза следующим образом. Пусть  обозначает функцию распределения выборки
обозначает функцию распределения выборки  , тогда подлежащая проверки гипотеза означает утверждение
, тогда подлежащая проверки гипотеза означает утверждение  , где
, где  - некоторая одномерная функция распределения (она может быть полностью задана, либо задано семейство, которому она принадлежит, либо никак не специфицируется). Типичным примером ситуации, когда возникает необходимость проверки гипотезы случайности, является работа генератора (датчика) случайных чисел. Под случайными числами понимается последовательность
- некоторая одномерная функция распределения (она может быть полностью задана, либо задано семейство, которому она принадлежит, либо никак не специфицируется). Типичным примером ситуации, когда возникает необходимость проверки гипотезы случайности, является работа генератора (датчика) случайных чисел. Под случайными числами понимается последовательность 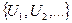 независимых и равномерно распределённых на отрезке [0,1] случайных величин. Такие числа широко используются в различных областях: в статистике – для моделирования случайных выборок из различных распределений, в криптографии – при получении ключей для шифрования информации, в численном анализе и т.д. В практических задачах последовательность
независимых и равномерно распределённых на отрезке [0,1] случайных величин. Такие числа широко используются в различных областях: в статистике – для моделирования случайных выборок из различных распределений, в криптографии – при получении ключей для шифрования информации, в численном анализе и т.д. В практических задачах последовательность  (т.е. чтобы эти числа были практически неотличимы от независимых одинаково распределенных чисел), что в математическом плане сводится к проверке гипотезы случайности.
(т.е. чтобы эти числа были практически неотличимы от независимых одинаково распределенных чисел), что в математическом плане сводится к проверке гипотезы случайности.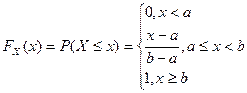






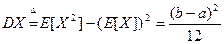



 , то случайная величина
, то случайная величина 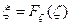 имеет равномерное распределение на отрезке [0,1]. Этим объясняется широкое использование равномерного распределения в статистическом моделировании (методы Монте-Карло).
имеет равномерное распределение на отрезке [0,1]. Этим объясняется широкое использование равномерного распределения в статистическом моделировании (методы Монте-Карло). случайную величину с равномерным распределением на отрезке
случайную величину с равномерным распределением на отрезке 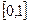 . Для этой случайной величины функция распределения и плотность распределения вероятностей соответственно имеют вид:
. Для этой случайной величины функция распределения и плотность распределения вероятностей соответственно имеют вид:


 , то вероятность
, то вероятность 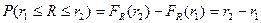
 . Пусть
. Пусть  Возведем его в квадрат:
Возведем его в квадрат: 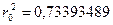 .Выберем четыре средние цифры этого числа и положим
.Выберем четыре средние цифры этого числа и положим  . Затем возводим
. Затем возводим  в квадрат:
в квадрат:  и снова выбираем четыре средние цифры. Получаем
и снова выбираем четыре средние цифры. Получаем  . Далее находим
. Далее находим  и т. д. Последовательность чисел
и т. д. Последовательность чисел  принимают за последовательность значений случайной величины
принимают за последовательность значений случайной величины 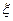 имеет монотонно возрастающую функцию распределения
имеет монотонно возрастающую функцию распределения  , значит, случайная величина
, значит, случайная величина 
 случайной величины
случайной величины  где
где  значение случайной величины
значение случайной величины 
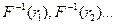 значений случайной величины
значений случайной величины 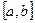
 , откуда
, откуда 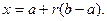
 случайной величины
случайной величины  , которая при каждой реализации выборки
, которая при каждой реализации выборки  принимает значение
принимает значение 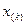 , называется k-ой порядковой статистикой.
, называется k-ой порядковой статистикой. распределения порядковых статистик имеют вид:
распределения порядковых статистик имеют вид:




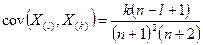
 , то плотность совместного распределения экстремальных значений выборки
, то плотность совместного распределения экстремальных значений выборки  и
и  имеет вид:
имеет вид:





 и
и 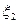 - независимые равномерно распределённые величины на отрезке [0,1], то величины
- независимые равномерно распределённые величины на отрезке [0,1], то величины 
 - независимы и нормально распределены с параметрами (0,1).
- независимы и нормально распределены с параметрами (0,1). - выборочное среднее.
- выборочное среднее. - выборочная дисперсия.
- выборочная дисперсия. называется статистикой.
называется статистикой. называется несмещённой оценкой для заданной параметрической функции
называется несмещённой оценкой для заданной параметрической функции  если она удовлетворяет условию:
если она удовлетворяет условию:
 для заданной параметрической функции
для заданной параметрической функции  называется состоятельной, если
называется состоятельной, если
 при
при 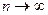
 для любого
для любого 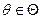 .
. из распределения
из распределения  и оценим параметр θ. Рассмотрим класс оценок вида
и оценим параметр θ. Рассмотрим класс оценок вида 

 .
. по выборке
по выборке  Тогда:
Тогда: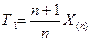 и
и  - несмещённые.
- несмещённые. то есть оценка
то есть оценка  точнее. Более того,
точнее. Более того, 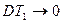 при
при  то есть оценка
то есть оценка  не обладает этим свойством.
не обладает этим свойством. - выборка из
- выборка из  . Тогда статистики
. Тогда статистики  и
и 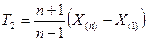 несмещённые и состоятельные оценки функций
несмещённые и состоятельные оценки функций 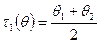 и
и  соответственно.
соответственно.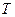 из класса
из класса 
 , для любого
, для любого 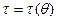 , если
, если ,
,  ,
,  .
.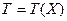 называется достаточной для параметрического семейства распределений P=
называется достаточной для параметрического семейства распределений P=  (или достаточной для параметра
(или достаточной для параметра  ), если условный закон распределения выборки при условии, что статистика T(X) приняла некоторое фиксированное значение t, не зависит от параметра
), если условный закон распределения выборки при условии, что статистика T(X) приняла некоторое фиксированное значение t, не зависит от параметра  , где Т – полная достаточная статистика, H(T) – произвольная функция от Т.
, где Т – полная достаточная статистика, H(T) – произвольная функция от Т. , рассматриваемая при фиксированной реализации выборки
, рассматриваемая при фиксированной реализации выборки  как функция от
как функция от  в нём допускала следующее представление:
в нём допускала следующее представление:
 Тогда
Тогда  - полная достаточная статистика для θ. Тогда
- полная достаточная статистика для θ. Тогда 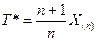 - оптимальная несмещённая оценка θ, и вообще,
- оптимальная несмещённая оценка θ, и вообще, 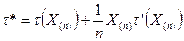 - оптимальная оценка любой дифференцируемой функции
- оптимальная оценка любой дифференцируемой функции 
 является полной. Кроме того, оценки
является полной. Кроме того, оценки  и
и 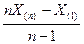 являются несмещёнными, следовательно, и оптимальными оценками для параметров
являются несмещёнными, следовательно, и оптимальными оценками для параметров  и
и  соответственно.
соответственно. где
где  - заданные непрерывные функции скалярного параметра θ.
- заданные непрерывные функции скалярного параметра θ. при возрастании θ, то в этом случае существует одномерная достаточная статистика
при возрастании θ, то в этом случае существует одномерная достаточная статистика 
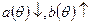 при возрастании θ, то одномерная достаточная статистика существует и имеет вид
при возрастании θ, то одномерная достаточная статистика существует и имеет вид 
 достаточной статистикой является
достаточной статистикой является  , а для моделей
, а для моделей 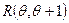 и
и 


