
Методы имитации случайных факторов
Базовой последовательностью случайных чисел, используемой для формирования в ЭВМ случайных элементов различной природы, с различными законами распределения является совокупность случайных чисел с равномерным законом распределения:
где
Строго говоря, на цифровой ЭВМ получить последовательность случайных величин с равномерным распределением не представляется возможным[1]. Поэтому, если считать, что число разрядов ЭВМ равно k, а случайное число сформировано согласно формуле:
где
Такое распределение чисел х называется квазиравномерным в интервале [0; 1], причем математическое ожидание и дисперсия определяются следующими соотношениями:
Из формул (9.2) видно, что математическое ожидание М[х] точно совпадает с генеральным средним для равномерного распределения в интервале [0; 1], а дисперсия при Практически при k > 15 обеспечивается требуемая точность в имитационных исследованиях. Поэтому в дальнейшем будем говорить о равномерном законе, хотя в действительности при программном моделировании имеем дело с квазиравномерным законом. При выводе выражений (9.2) предполагалось, что х формируется на основе случайных чисел αi, принимающих значения (0; 1) с вероятностью Однако, если при моделировании количество обращений к программному датчику случайных чисел оказывается меньше периода, измеряемого количеством различных случайных чисел, то такая периодичность программного датчика не оказывает существенного влияния на результаты моделирования. Основные достоинства программного способа получения псевдослучайных чисел состоят в следующем: · не требуются специальные внешние устройства; · получение чиселдостаточно быстрое (обычно требуется 3–10 команд на число); · возможно повторное воспроизведение чисел; · требуется только однократная проверка алгоритма получения заданной последовательности чисел. Методы получения псевдослучайных квазиравномерных чисел программным путем можно разделить на две основные группы: а) аналитические; б) методы перемешивания. При использовании аналитических методов очередное число в псевдослучайной последовательности получается с помощью некоторого рекуррентного соотношения, аргументами которого являются одно или несколько предыдущих чисел последовательности:
Простейшим примером указанного способа получения случайных чисел, равномерно распределенных в интервале [0; 1], может служить метод вычетов, в котором используется следующее рекуррентное соотношение:
где выражение bxi (mod M) означает остаток от деления произведения bxi на число М;
хi – предыдущее случайное число; b – некоторая константа; М – число, определяющее наибольшее значение получаемых случайных чисел.
Данный способ является основой построения мультипликативного программного датчика случайных чисел. В этом случае алгоритм построения последовательности случайных чисел сводится к следующему: 1. Выбрать в качестве параметра 2. Вычислить коэффициент b по формуле 3. Вычислить произведение bа0; взять k младших разрядов в качестве первого члена последовательности а1, остальные отбросить; 4. Провести нормализацию числа по формуле 5. Вычислить очередное псевдослучайное число а2 как k младших разрядов произведения bа1 и вернуться к пункту 4. Описанный генератор подвергался, как отмечено в [3] широкой экспериментальной проверке и проявил достаточно хорошие свойства. С другими аналитическими способами получения случайных чисел, равномерно распределенных в интервале [0; 1], можно ознакомиться в [1]. В случае применения методов перемешивания очередное число последовательности получается путем хаотического перемешивания разрядов предыдущего случайного числа с помощью операций сдвига, специальных сложений и различных арифметических операций. Например, часто используются следующие комбинации операций для перемешивания разрядов предыдущего случайного числа: · сдвиг предыдущего числа на некоторое число разрядов влево и специальное сложение результатов этого сдвига с предыдущим числом последовательности; · сдвиг предыдущего числа на некоторое число разрядов влево и вправо и специальное сложение результатов этих сдвигов. Данные операции заканчиваются взятием модуля и нормализацией. В качестве начальной константы для формирования последовательности обычно берут иррациональные числа. Имитация случайных событий. Пусть в результате эксперимента должно наступить одно из несовместимых событий
где Pk – вероятность наступления события Аk.
Разбиваем отрезок [0; 1] на n частей длиной P1, P2,..., Рп; при этом точки деления отрезка имеют следующие координаты:
Пусть теперь х – очередное число от генератора случайных чисел. Если Действительно:
Рассмотренная процедура может быть положена в основу выбора направления передачи требований при моделировании замкнутых сетей массового обслуживания. Аналогичным образом можно моделировать дискретные случайные величины при конечном числе их значений. Если имеем дискретную случайную величину у, причем у = 1 с вероятностью Р, а у = 0 с вероятностью 1 – Р, то при имитации ее на ЭВМ необходимо каждый раз решать следующую систему неравенств: если Имитация непрерывных случайных величин. В литературе рассматриваются несколько способов имитации, основанных на различных преобразованиях равномерно распределенных случайных чисел в числа с заданным законом распределения. Метод обратной функции. Он основан на использовании следующей теоремы. Если х – случайная величина, равномерно распределенная на отрезке [0; 1], то случайная величина у, являющаяся решением уравнения:
имеет плотность распределения f(y). Данный метод позволяет сформулировать правило генерирования случайных чисел, имеющих произвольное непрерывное распределение f(y): • вырабатывается случайное число х1 генератором случайной равномерной последовательности; • случайное число yi, имеющее распределение f(y), находится из решения уравнения:
Таким образом, последовательность чисел Пример 1. Необходимо получить последовательность чисел, равномерно распределенных на отрезке [а, b]. Тогда, используя (9.3) имеем:
откуда Пример 2. Необходимо получить последовательность чисел, имеющих распределение по показательной функции:
В соответствии с (9.3) имеем:
откуда
Так как величина
Однако формула (9.3) не для всех распределений может быть использована по следующим причинам: • зависимость • зависимость В этом случае используют приближенные методы, например метод ступенчатой аппроксимации и предельные теоремы теории вероятности. Метод ступенчатой аппроксимации. Зависимость плотности распределения f(y) от возможных значений случайной величины у представляется графически в интервале изменения у от а до b. Если случайная величина задана на бесконечном интервале, то производим усечение распределения с заданной точностью. В данном случае указанная плотность f(у) может быть получена также и экспериментально. Разобьем отрезок [а, b] на n, частей таких, что:
где αi – координата точки разбиения
Тогда вероятность того, что случайная величина у попадет в один из интервалов,
То есть попадание на любой отрезок · получаем два числа · с помощью x1 находим индекс · с помощью числа х2 находим · находим случайное число, имеющее интересующий нас закон распределения f(y):
Таким образом, для получения случайного числа у, имеющего закон f(y), используются два числа от генератора случайных чисел х1, x2. Использование предельных теорем. В некоторых случаях для имитации определенных законов распределения используют предельные теоремы теории вероятностей. Так, например, для получения нормального закона распределения используется свойство сходимости независимых величин к нормальному распределению. Метод обратной функции в этом случае оказывается неэффективным, так как получаемый при этом интеграл:
не раскрывает явную зависимость Для получения нормально распределенных чисел с параметрами Сформируем величину z согласно следующей формуле:
По центральной предельной теореме при достаточно большом значении п величина z может считаться нормально распределенной с параметрами:
Проведя нормирование величины z1 получим, что величина:
будет иметь нормальное распределение с параметрами Имитация дискретных случайных величин. Из всего множества законов распределения дискретных случайных величин рассмотрим наиболее часто встречающиеся в задачах имитации систем управления: • величины уi имеют биномиальное распределение:
• величины уi имеют пуассоновское распределение с параметром аi:
В первом случае имитация величины уi сводится к n -кратной имитации эксперимента с двумя исходами:
имеет распределение, близкое к биномиальному. Во втором случае необходимо воспользоваться предельной теоремой Пуассона: если Р0 – вероятность наступления события А при одном испытании, то вероятность наступления i события при n независимых испытаниях в случае, если
Поэтому имитация в этом случае проводится так же, как и в первом, только при условии, что:
Чем больше значение n, тем больше распределение чисел уi будет приближаться к закону Пуассона (9.6). Значение л выбирается из условия (9.7) при известном параметре а. Имитация потоков дискретных событий. Под потоком событий, как ранее было отмечено, понимают последовательность однородных событий, происходящих в какие-то, вообще говоря, случайные моменты времени. В системе управления мы имеем дело с различными видами потоков (например, потоки задач, вызовов, справок в информационных системах; потоки отказов и восстановлений; потоки команд управления типа «включить», «отключить» в сложных иерархических системах управления рассредоточенными объектами; потоки требований на занятие определенного ресурса, причем в вычислительных системах – требование на занятие магистрали, внешнего запоминающего устройства, процессора, в системах связи – требование на занятие канала связи и т. д.). При имитационном моделировании поток событий чаще всего воспроизводится через интервалы времени между соседними событиями. Если время между соседними событиями случайно, то в зависимости от вида распределения воспроизведение его в ЭВМ происходит в соответствии с теми способами, которые были рассмотрены при имитации непрерывных случайных величин, причем случайной величиной является длительность интервала между соседними событиями. Например, для простейшего потока событий время между событиями подчинено показательному закону; следовательно, имитация данного потока должна происходить в соответствии с выражением (9.4). Модификация простейшего потока – поток Эрланга – получается в результате имитации простейшего потока и последующего просеивания его событий в соответствии с порядком этого потока. Регулярный поток в системе легко имитируется, так как он задается постоянным временем интервала между событиями. Аналогичным образом могут быть смоделированы и потоки более общего вида через задание соответствующего распределения интервалов между соседними событиями в потоке. Рассмотренные выше способы имитации случайных факторов являются далеко не полным перечнем способов моделирования различных возможных случайных ситуаций, возникающих в системе управления.
NB
■ Имитационное моделирование является относительно новым и быстро развивающимся методом исследования поведения систем управления. Этот метод состоит в том, что с помощью ЭВМ воспроизводится поведение исследуемой системы управления, а исследователь-системотехник, управляя ходом процесса имитации и обозревая получаемые результаты, делает вывод о ее свойствах и качестве поведения. ■ При имитационном моделировании на ЭВМ можно выделить следующие основные этапы исследования: ■ формулировка проблемы; ■ построение математической модели функционирования системы; ■ составление и отладка программы для ЭВМ, включая и разработку процедур моделирования различных случайных факторов; ■ планирование имитационных экспериментов; ■ проведение экспериментов и обработка результатов исследования. ■ Составление машинной программы. Решаются следующие задачи: ■ составление самой программы с использованием как универсальных алгоритмических языков, так и проблемно-ориентированных на решение задач имитации; ■ разработка программных процедур имитации различных случайных факторов, имеющихся в системе; ■ отладка программы. ■ Планирование экспериментов. Решаются следующие основные задачи: ■ выбор способов ускорения сходимости статистических оценок интересующих нас критериев к истинным значениям; ■ определение объема имитационных экспериментов; ■ составление плана проведения машинных экспериментов, что особенно важно при решении задач оптимизации на основе имитации. Решение вышеуказанных задач и составляет содержание этапа планирования экспериментов. ■ Метод ступенчатой аппроксимации. Зависимость плотности распределения f(у) от возможных значений случайной величины у представляется графически в интервале изменения у от а до b. Если случайная величина задана на бесконечном интервале, то производим усечение распределения с заданной точностью. ■ Использование предельных теорем. В некоторых случаях для имитации определенных законов распределения используют предельные теоремы теории вероятностей. Так, например, для получения нормального закона распределения используется свойство сходимости независимых величин к нормальному распределению. ■ Имитация потоков дискретных событий. Под потоком событий, как ранее было отмечено, понимают последовательность однородных событий, происходящих в случайные моменты времени. Литература
1. Голенко Д.И. Моделирование псевдослучайных чисел на ЭВМ. – М.: Наука, 1982. 2. Денисов А.A., Колесников Д.H. Теория больших систем управления. – Л.; Энергоиздат, 1982. 3. Ермаков С.М. Метод Монте-Карло и смежные вопросы. – М.: Наука, 1981. 4. Моисеев Н.Н. Имитационные модели. – М.: Знание, 1983. 5. Полляк Ю.Г. Вероятностное моделирование на ЭВМ. – М.: Советское радио, 1981. 6. Растригин Л.А. Современные принципы управления сложными объектами. – М.: Советское радио, 1980. 7. Шеннон К. Имитационное моделирование. – М.: Наука, 1989. Глава 10. Планирование экспериментов
|

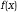 – дифференциальный закон распределения равномерно распределенных чисел х в интервале
– дифференциальный закон распределения равномерно распределенных чисел х в интервале 
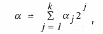
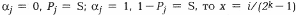 принимает значение
принимает значение  с вероятностью
с вероятностью 
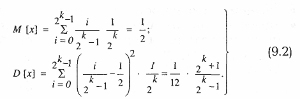
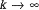 асимптотически стремится к дисперсии для равномерного распределения при а = 0, b = 1, равной 1/12.
асимптотически стремится к дисперсии для равномерного распределения при а = 0, b = 1, равной 1/12. = 1/2, для чего в машине должен существовать случайный генератор, дающий строго случайные последовательности чисел αiссоответствующим распределением. Так как в ЭВМ такого генератора нет, случайные числа вырабатываются программным путем, в силу чего они, строго говоря, не являются случайными, так как формируются на основе вполне детерминированных преобразований, поэтому их называют псевдослучайными. Такие последовательности случайных чисел являются периодическими, поэтому очень длинные последовательности, длина которых превосходит период, уже не будут строго случайными.
= 1/2, для чего в машине должен существовать случайный генератор, дающий строго случайные последовательности чисел αiссоответствующим распределением. Так как в ЭВМ такого генератора нет, случайные числа вырабатываются программным путем, в силу чего они, строго говоря, не являются случайными, так как формируются на основе вполне детерминированных преобразований, поэтому их называют псевдослучайными. Такие последовательности случайных чисел являются периодическими, поэтому очень длинные последовательности, длина которых превосходит период, уже не будут строго случайными.
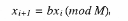
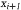 – очередное случайное число;
– очередное случайное число;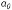 – произвольное нечетное число, например
– произвольное нечетное число, например  при разрядности ЭВМ k = 32, b М = 231-1;
при разрядности ЭВМ k = 32, b М = 231-1; , где с – любое целое положительное число, в частном случае
, где с – любое целое положительное число, в частном случае 

 которые образуют полную группу событий, то есть:
которые образуют полную группу событий, то есть:
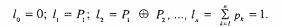
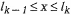 то считаем, что произошло событие Ak.
то считаем, что произошло событие Ak.
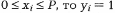 ; если
; если  , где х1 – очередное случайное число от генератора случайных равномерно распределенных чисел.
, где х1 – очередное случайное число от генератора случайных равномерно распределенных чисел.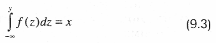
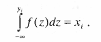
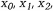
 преобразуется в последовательность
преобразуется в последовательность 
 имеющую заданную плотность распределения f(y). Рассмотрим примеры.
имеющую заданную плотность распределения f(y). Рассмотрим примеры.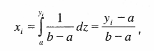




 также имеет равномерное распределение на отрезке [0; 1], то формула (9.4) может быть записана другим способом:
также имеет равномерное распределение на отрезке [0; 1], то формула (9.4) может быть записана другим способом:
 нельзя получить в явном виде;
нельзя получить в явном виде; является сложной для численных расчетов.
является сложной для численных расчетов.

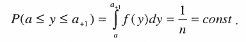
 случайной точки равновероятно. На каждом из интервалов функция f(y) аппроксимируется ступенчатой функцией так, чтобы значение f(у) в каждом интервале было постоянным; тогда координата случайной точки может быть представлена как
случайной точки равновероятно. На каждом из интервалов функция f(y) аппроксимируется ступенчатой функцией так, чтобы значение f(у) в каждом интервале было постоянным; тогда координата случайной точки может быть представлена как  – расстояние точки от левого конца интервала. В силу ступенчатой аппроксимации сi является равномерно распределенной величиной на интервале
– расстояние точки от левого конца интервала. В силу ступенчатой аппроксимации сi является равномерно распределенной величиной на интервале  . Правило имитации в этом случае сводится к следующему:
. Правило имитации в этом случае сводится к следующему: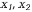 от генератора равномерно распределенных чисел;
от генератора равномерно распределенных чисел;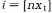 для интервала, где
для интервала, где  – целая часть числа
– целая часть числа  , причем
, причем 
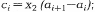


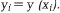
 удобен искусственный прием, основанный на центральной предельной теореме теории вероятностей. Для этого в качестве исходных чисел возьмем n равномерно распределенных на отрезке [–1; 1] чисел, получаемых из интервала [0; 1] по правилу:
удобен искусственный прием, основанный на центральной предельной теореме теории вероятностей. Для этого в качестве исходных чисел возьмем n равномерно распределенных на отрезке [–1; 1] чисел, получаемых из интервала [0; 1] по правилу: 



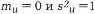 . Практически установлено, что при n > 8 формула (9.5) дает вполне хорошие результаты.
. Практически установлено, что при n > 8 формула (9.5) дает вполне хорошие результаты.

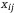 = 1 с вероятностью Р и хij = 0 с вероятностью
= 1 с вероятностью Р и хij = 0 с вероятностью  , что реализуется по уже рассмотренной выше схеме имитации дискретных случайных событий. Тогда:
, что реализуется по уже рассмотренной выше схеме имитации дискретных случайных событий. Тогда:
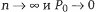 , асимптотически стремится к (9.6) при:
, асимптотически стремится к (9.6) при:




