Класифікація на основі дискримінантної функції
Модуль Дискримінантний аналіз використовується у випадку, коли маємо групи об’єктів і перед нами стоїть завдання віднесення нового об’єкта до якоїсь групи та коли необхідно встановити правила віднесення об’єкта до певної групи. Розглянемо приклад. Нехай, підприємства характеризуються наступними економічними показниками: х1 – продуктивність праці, х2 – питома вага робітників у складі промислово-виробничого персоналу, х3 – коефіцієнт змінності устаткування (змін), х4 – питома вага втрат від браку (%), х5 – фондовіддача активної частини основних виробничих фондів. Значення вказаних показників для 20 підприємств наведені у табл. 9. Зверніть увагу, що 17 підприємств уже розкласифіковані на дві групи, а три підприємства необхідно віднести до певної групи. Таблиця 9 Вихідні дані для аналізу
Запустити програму Statistica. Сформувати таблицю вихідних даних. Зауважимо, що в таблицю вихідних даних необхідно додати кілька рядків без даних (вони призначені для об’єктів, які потрібно віднести до певного класу). На панелі інструментів Statistics або в меню Statistics вибрати функцію Discriminant Analysis – Дискримінантний аналіз. У стартовому вікні Дискримінантного аналізу потрібно обрати групувальний показник – Grouping (у нашому випадку – „група”) і незалежні змінні – Independent (рис. 29). У цьому ж вікні можна зробити додаткові установки.
Рис. 29. Стартове вікно Дискримінантного аналізу
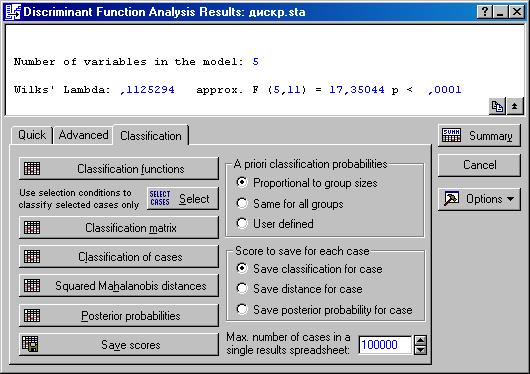
Натиснувши кнопку ОК, одержимо вікно результатів (рис. 30).
Рис. 30. Вікно результатів дискримінантного аналізу В інформаційній частині вікна міститься наступна інформація: кількість змінних у моделі, значення лямбди Уілкса, значення критерію Фішера для апроксимації. У функціональній частині вікна є ряд кнопок для всебічного перегляду результатів. Натиснувши кнопку Classification functions – Класифікаційні функції, одержимо коефіцієнти дискримінантних функцій для двох груп (рис. 31). Угорі в таблиці вказана ймовірність віднесення підприємства до тієї чи іншої групи.
Рис. 31. Коефіцієнти дискримінантних функцій
Ініціювавши кнопку Classification matrix, одержимо матрицю класифікацій, у якій зазначено кількість спостережень у кожній групі й імовірність попадання спостережень у групи (рис. 32). Зверніть увагу на цю матрицю. У стовпці Percent Correct указаний процент правильної класифікації об’єктів. У рядках матриці вказана спостережувана класифікація підприємств, а у стовпцях – отримана за побудованими дискримінантними функціями. З матриці видно, що у цьому прикладі не спостерігається випадків неправильної класифікації.
Рис. 32. Матриця класифікацій
Класифікацію елементів можна одержати, натиснувши на кнопку Classification of cases. Якщо у стовпці Cases не виявиться елементів, позначених „зірочкою”, то це свідчить про коректну класифікацію і гарну апроксимацію дискримінантних функцій. Для того, щоб класифікувати нові об’єкти (підприємства), НЕ ЗАКРИВАЮЧИ АНАЛІЗ, вводимо у вихідну таблицю значення тих об’єктів, які потрібно віднести до певної групи. Потім у вікні аналізу результатів ініціюємо кнопку Posterior Probabilities – Апостеріорні ймовірності. В результаті одержимо таблицю класифікацій, за якою визначаємо, у який клас увійшли нові об’єкти (рис. 33). Так підприємства 18 і 20 увійшли в групу а, а підприємство 19 – у групу b. (Дивіться значення ймовірності попадання об'єкта в ту або іншу групу. Для якої групи ймовірність вища, до тієї групи і відноситься об'єкт).
Рис. 33. Апостеріорні ймовірності
Завдання. Самостійно ознайомтеся з іншими можливостями модуля Дискримінантного аналізу. Проведіть покроковий дискримінантний аналіз, змінюючи початкові установки. Порівняйте результати, отримані різними методами.
Рекомендована література
|