Создание и заполнение баз ТМ
Входной и выходной языки задаются на этапе создания базы Translation Memory и не могут быть изменены в дальнейшем. Если создаваемая база ТМ предназначена для подключения к переводу в лингвистическом редакторе PROMT Editor или в других приложениях системы PROMT 8.0, имеющих функции перевода, диалект входного (выходного) языка не имеет значения.
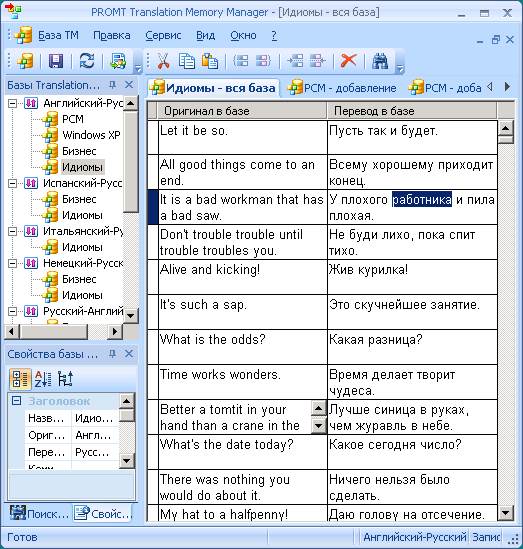
Текст, добавляемый в базу ТМ, разбивается на фрагменты в соответствии с определенными правилами, называемыми правилами сегментации. Сегменты выделяются по знакам препинания, обозначающим конец предложения или смыслового фрагмента текста: точка, вопросительный и восклицательный знаки, знак абзаца, двоеточие. Аббревиатура с точкой не считается границей сегмента. Для входного и выходного языков устанавливаются разные правила сегментации.
Рис. 16. Фрагмент текста, сохраненный в базе Translation Memory
Правила сегментации бывают двух типов: • Правило — позволяет задать условия, при которых определенные символы (например, точка в конце предложения) являются границами сегментов; • Исключение — позволяет задать условия, при которых определенные символы (например, точка в конструкции "в т. ч.") не являются границами сегментов.
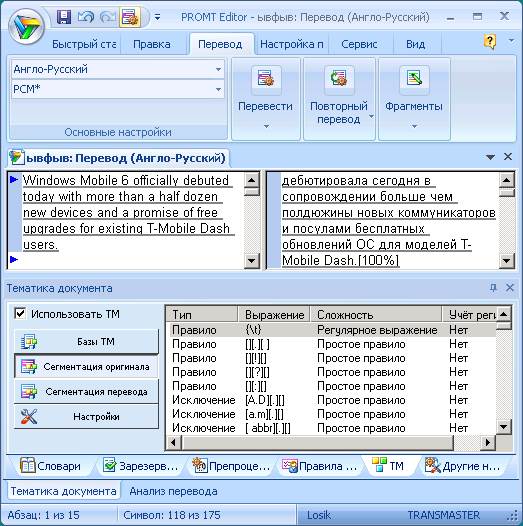
Для каждого языка имеется базовый набор правил сегментации и исключений. Кроме того, существует возможность настройки правил сегментации оригинала и перевода при добавлении в базу ТМ из приложения PROMT Editor, а также при импорте параллельных текстов в базу ТМ. Существуют простые правила сегментации и регулярные выражения. Алгоритм построения простых правил и регулярных выражений подробно описан в справочной системе. Если один и тот же набор символов входит и в правило, и в исключение, приоритет имеет правило.
Рис. 17. Правила сегментации текста
|