
Основные теоретические сведения. В общем случае регрессия – функциональная зависимость между объясняющими переменными Хj и объясняемой переменной Y
В общем случае регрессия – функциональная зависимость между объясняющими переменными Хj и объясняемой переменной Y, которая строится с целью прогнозирования среднего значения Y при заданных значениях Хj =xj, Различают уравнения регрессии I и II рода. Уравнением регрессии первого рода называют уравнение вида:
Если уравнение (1.1) представляет собой уравнение связи двух случайных величин Y и Х, то это уравнение представляет собой уравнение парной регрессии. В предположении нормального распределения случайной величины (Y, Х) парную регрессию называют линейной парной регрессией, т.к. в этом случае условное математическое ожидание (1.1) представляет собой уравнение прямой линии Y = M (Y / x) = Для точного описания уравнения регрессии необходимо знать условный закон распределения зависимой переменной Y при условии, что переменная Х примет значение х. В связи с тем, что реальные значения переменной Y не всегда совпадают с ее средним значением M (Y / x), то в уравнение регрессии вводится случайная составляющая Y* = M (Y / x) +
или для конкретных наблюдений (у i, x i):
Уравнение (1.4) называют теоретической линейной моделью. Возмущения 1. Математическое ожидание возмущения
или
2. Дисперсия возмущения
3. Возмущения
4. Возмущения Обычно исследователь имеет дело с исходными данными выборки объемом n, где каждое наблюдение – есть точка (Y, Х) в (m +1) – мерном пространстве. Здесь m – число объясняющих переменных. В случае парной регрессии имеется выборка объемом n двумерной случайной величины (Y, Х). Уравнением регрессии второго рода называют эмпирическое уравнение регрессии, которое строится на основе данных выборки. Рассматривается парная линейная регрессия, когда уравнение регрессии второго рода имеет вид
С учетом уравнения (1.3) эмпирическую линейную модель связи переменных Y и Х запишем в виде: yi = b 0 + b 1 xi + ei, (1.6)
где Построение уравнения регрессии начинается с построения корреляционного поля, представляющего собой графическую зависимость в виде точек случайной величины (Y, Х) на плоскости y 0 x. По расположению эмпирических точек делается вывод о наличии линейной корреляционной зависимости между переменными Y и Х. Дальнейшее построение уравнения регрессии сводится к оценке ее параметров, используя метод наименьших квадратов (МНК). В этом случае неизвестные параметры b 0 и b 1 выбираются так, чтобы сумма квадратов отклонений эмпирических значений yi от значений
Применение МНК обусловлено тем, что он позволяет получить несмещенные оценки с минимальной дисперсией, в условиях, когда В результате операции МНК оценка выборочного коэффициента регрессии b 1 определяется выражением: b 1 = Cov (X, Y) / а коэффициента b 0: b 0 = где
Точность оценок коэффициентов линейного уравнения регрессии первого рода характеризуется их выборочными дисперсиями, которые вычисляются по формулам:
Здесь S 2 – дисперсия регрессии – оценка дисперсии Проверка качества уравнения регрессии осуществляется по ряду позиций. Оценка статистической значимости коэффициентов регрессии заключается в проверке основной гипотезы Н0 о значимости отличия коэффициентов b0 и b1 от нуля. С этой целью используется критерий Стьюдента. Вычисляются, и сравниваются с tкрит. Результатом сравнения является вывод о значимости коэффициентов b0 и b1. 2. Интервальные оценки коэффициентов уравнения регрессии. Так как объем выборки ограничен, то b 0 и b 1 – случайные величины, поэтому желательно найти доверительные интервалы для истинных значений
которая имеет t – распределение Стьюдента с
с надежностью р = 1- 3. Проверка значимости уравнения регрессии в целом. Позволяет установить, соответствует ли математическая модель экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных для описания зависимой переменной. Проверка значимости уравнения регрессии производится на основе дисперсионного анализа. Мерой общего качества уравнения регрессии является коэффициент детерминации R2: R 2 = 1 - Выражение (1.11) вытекает из соотношения:
где
Из соотношений (1.11) и (1.12) следует, что коэффициент детерминации R 2 есть не что иное, как:
R 2 =
Таким образом, коэффициент детерминации можно вычислить по (1.11) или по (1.13). Основная цель использования уравнения регрессии - прогноз значений зависимой переменной. Здесь речь идет о возможных значениях Yр при определенных значениях объясняющей переменной Хр. Так как задача решается в условиях неопределенности то прогноз удобнее всего давать на основе интервальных оценок, построенных с заданной надежностью Причем здесь возможно два подхода: 1) предсказание среднего значения, т.е. M (Y / Х = xр); 2) предсказание индивидуальных значений Y / Х = xр. Интервальный прогноз для среднего значения вычисляется следующим образом:
где Интервальный прогноз для индивидуального значения вычисляется по формуле:
|
 или для анализа влияния отдельных переменных Хj,
или для анализа влияния отдельных переменных Хj,  . (1.1)
. (1.1) 0 +
0 +  . Тогда уравнение (1.2) можно записать в виде:
. Тогда уравнение (1.2) можно записать в виде: =
=  i,
i,  . (1.4)
. (1.4)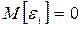

 ,
,  .
.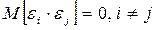 .
. i = М [ Y/X=x ] = b 0 + b 1 xi,
i = М [ Y/X=x ] = b 0 + b 1 xi,  min.
min.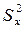 , (1.7)
, (1.7) , (1.8)
, (1.8) =
=  уi / n;
уi / n;  =
=  ;
;  .
. , (1.9)
, (1.9) . (1.10)
. (1.10)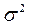 , определяемая по формулам: S 2 =
, определяемая по формулам: S 2 =  0,
0, 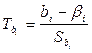 , i = 0, 1,
, i = 0, 1, степенями свободы. Интервальные оценки параметров
степенями свободы. Интервальные оценки параметров 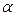 имеют вид
имеют вид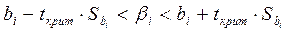 , i = 0, 1,
, i = 0, 1, еi 2 /
еi 2 /  (yi -
(yi -  ki 2 +
ki 2 +  ei 2, (1.12)
ei 2, (1.12) i -
i -  ki 2 /
ki 2 /  .
. р
р 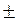 tкр S
tкр S  , (1.14)
, (1.14) р = b 0 + b 1 xр; t кр – критическое значение, полученное по распределению Стьюдента при количестве степеней свободы
р = b 0 + b 1 xр; t кр – критическое значение, полученное по распределению Стьюдента при количестве степеней свободы 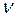 = n – 2 и заданной вероятности
= n – 2 и заданной вероятности  /2.
/2. . (1.15)
. (1.15)


