Выполнение. Загрузим файл данных. Проведем простейший кластерный анализ имеющихся данных
Загрузим файл данных. Проведем простейший кластерный анализ имеющихся данных. Для этого построим диаграмму рассеяния. · Выберем в меню «Визуализация – Интерактив – Диаграмма рассеяния». Появится диалоговое окно «Диаграмма рассеяния» (рис. 2.8.1). Выбираем «Простой» – «Определ.».
Рис. 2.8.1 Вид диалогового окна «Диаграмма рассеяния»
Появится диалоговое окно «Простой график рассеяния» (рис. 2.8.2).
Рис. 2.8.2 Вид диалогового окна «Простой график рассеяния»
· Переменную Белок поместим в поле оси X, а переменную Крахмал в поле оси Y. · Ничего больше не меняя, начнем расчёт нажатием ОК. Получим диаграмму рассеяния, представленную на рис. 2.8.3. При помощи диаграммы рассеяния для двух переменных: Крахмал и Белок, был проведен самый простой кластерный анализ. Был выбран такой вид графического представления, с помощью которого можно отчётливо распознать группирование в кластеры. В рассматриваемом случае по виду диаграммы можно увидеть, что наблюдения сгруппировались в четыре кластера. Далее будем проводить иерархический кластерный анализ. В иерархических методах каждое наблюдение образовывает сначала свой отдельный кластер. На первом шаге два соседних кластера объединяются в один; этот процесс может продолжаться до тех пор, пока не останутся только два кластера.
Рис. 2.8.3. Диаграмма рассеяния переменных Крахмал и Белок
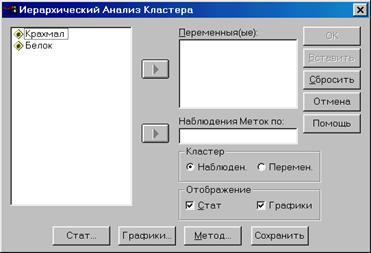
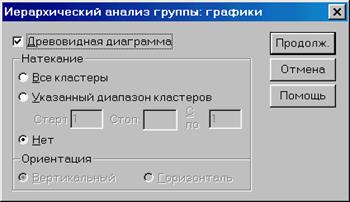
Соберём имеющиеся 20 сортов картофеля в кластеры, используя имеющиеся параметры Крахмал и Белок. Выберем в меню Анализ – Классификация – Иерархический кластерный анализ. Появится диалоговое окно «Иерархический Анализ Кластера» (см. рис. 2.8.4). Переменные Крахмал и Белок поместите в поле «Переменные». · Щелчком по выключателю «Статистика» откроем диалоговое окно «Иерархический кластерный анализ: Статистика» (рис. 2.8.5). Оставим флажок напротив опции «Режим накопления». Активируем опцию «Диапазон решений» и введем числа 3 и 5 в качестве границ области. (Хотя на основании графического представления на диаграмме рассеяния (рис. 2.8.3) и ожидается результат в виде четырёх кластеров, но не можем быть полностью уверены в достижении этого результата). · Вернувшись в главное диалоговое окно, щёлкните по выключателю «Графики». В появившемся диалоговом окне (рис. 2.8.6) активируем опцию вывода «Древовидной диаграммы» и посредством опции «Нет» отмените вывод ориентации графика. · С помощью кнопки «Метод» возможно выбрать метод образования кластеров, а также метод расчета дистанционной меры и меры подобия соответственно. Здесь (рис. 2.8.7) в поле «Преобразование значений» установите «Множества–z (стандартизацию) значений». · Вернемся назад в главное диалоговое окно и начните расчёт нажатием ОК.
Рис. 2.8.4. Вид диалогового окна «Иерархический кластерный анализ»
Рис. 2.8.5. Вид диалогового окна «Иерархический кластерный анализ: Статистики»
Рис. 2.8.6. Вид диалогового окна «Иерархический кластерный анализ: Диаграммы»
Рис. 2.8.7. Вид диалогового окна «Иерархический кластерный анализ: Метод»
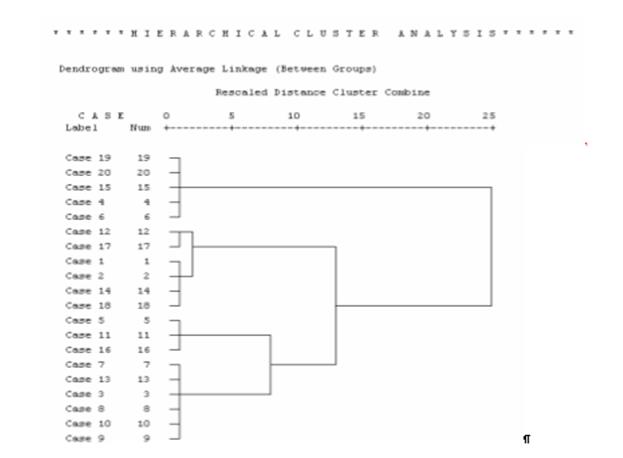
Вывод основных результатов расчета выглядит следующим образом (рис. 2.8.8). В таблице Agglomeration Schedule (Порядок агломерации) можно выяснить очерёдность построения кластеров, а также их оптимальное количество. По двум колонкам, расположенным под общей шапкой Cluster Combined (Объединение в кластеры), можно увидеть, что на первом шаге были объединены наблюдения 19 и 20. Эти два сорта картофеля максимально похожи друг на друга и отдалены друг от друга очень малое расстояние. Эти два наблюдения образовывают кластер с номером 1, в то время как кластер 20 в обзорной таблице больше не появляется. На следующем шаге происходит объединение наблюдений 5 и 11, затем 3 и 8 и т.д. Под этим коэффициентом подразумевается расстояние между двумя кластерами, определенное на основании выбранной дистанционной меры с учётом предусмотренного преобразования значений. В нашем случае это квадрат евклидового расстояния, определенный с использованием стандартизованных значений (в примере использовалось Множество–z). На этом этапе, где эта мера расстояния между двумя кластерами увеличивается скачкообразно, процесс объединения в новые кластеры необходимо остановить, так как в противном случае были бы объединены уже кластеры, находящиеся на относительно большом расстоянии друг от друга.
Рис. 2.8.8. Результат выполнения процедуры Для определения, какое количество кластеров следовало бы считать оптимальным, решающее значение имеет показатель, выводимый под заголовком Coefficients (Коэффициент). В приведенном примере – это скачок с 0,33 до 2,013. Это означает, что после образования четырех кластеров мы больше не должны производить никаких последующих объединений, а результат с четырьмя кластерами является оптимальным. Оптимальным считается число кластеров равное разности количества наблюдений (здесь: 20) и количества шагов, после которого коэффициент увеличивается скачкообразно (здесь: 16). В таблице Cluster Membership (Принадлежность к кластеру) приведена информация о принадлежности каждого наблюдения кластеру, для результатов расчёта содержащих 5, 4 и 3 кластеров. В заключение приводится затребованная нами древовидная диаграмма, которая визуализирует процесс слияния, приведенный в обзорной таблице порядка агломерации. Она идентифицирует объединённые кластеры и значения коэффициентов на каждом шаге. При этом отображаются не исходные значения коэффициентов, а значения, приведенные к шкале от 0 до 25.
|