Лингвистические неопределенности и вычисление значений лингвистической переменной
В общем случае значение лингвистической переменной есть составной терм 1. первичные термы, которые являются символами нечетких подмножеств области рассуждения (например, молодой, старый); 2. отрицание не и союзы и, или; 3. лингвистические неопределенности типа очень, много, слабо, более или менее и т.д., которые дают возможность модифицировать значения элементарных и составных терминов и служат для увеличения области значений лингвистической переменной; 4. маркеры, такие, как скобки, вводные слова. Основная проблема, которая возникает в связи с использованием лингвистических переменных, заключается в следующем: пусть дано значение каждого элементарного термина в составном терме Рассмотрим вначале вычисление значения составного терма в виде t = hu, где h - неопределенность, а u - терм с фиксированным значением, например, h = очень, а u = высокий. Неопределенности выполняют функцию генерации большого множества значений для лингвистической переменной из небольшого набора первичных терминов. Поэтому неопределенность h можно рассматривать как нелинейный оператор, который переводит нечеткое множество М(u), представляющее значение u, в нечеткое множество М(hu) и таким образом преобразует смысл соответствующих термов. Хотя в повседневном использовании неопределенность очень не имеет четко определенного значения, в сущности она действует как усилитель, генерируя подмножество того множества, к которому она применяется. Простая операция, которая имеет это свойство, - операция концентрации:
В результате применения этой операции к множеству А уменьшаются степени принадлежности элементов этому множеству, причем для элементов с высокой степенью принадлежности это уменьшение относительно мало, а для элементов с малой степенью принадлежности - относительно велико.
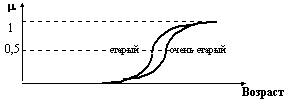
Рис. 4.7. Графическое представление терминов старый и очень старый. Например, если терм старый определен как (2), то очень старый = Другой простой пример: если терм маленький = 1/1 + 0,8/2 + 0,6/3 + 0,4/4 + 0,2/5, то очень маленький = (маленький)2 = 1/1 + 0,64/2 + 0,36/3 + 0,16/4 + 0,04/5. Вычисление значения более сложного составного терма, который может включать кроме неопределенности h термины не, или, и, является задачей, сходной с задачей вычисления значения булевского выражения. Рассмотрим, например, вычисление составного терма t = не очень маленький. Учитывая, что операция дополнения соответствует отрицанию, получаем: не очень маленький = u (не очень маленький) = 0,36/2 + 0,64/3 + 0,84/4 + 0,96/5 Возьмем для примера более сложный терм: t = не очень большой и не очень маленький. Если терм большой = 0,2/1 + 0,4/2 + 0,6/3 + 0,8/4 + 1/5, то очень большой = (большой)2 = 0,04/1 + 0,16/2 + 0,36/3 + 0,64/4 + 1/5 и не очень большой = u (не очень большой) = 0,96/1+ 0,84/2 + 0,64/3 + 0,36/4. Следовательно, не очень большой и не очень маленький = = (0,96/1+ 0,84/2 + 0,64/3 + 0,36/4) C (0,36/2 + 0,64/3 + 0,84/4 + 0,96/5)= = 0,36/2 + 0,64/3 + 0,36/4 При вычислении значения составного терма используются обычные правила предшествования, действующие при преобразовании булевских выражений. С добавлением неопределенностей эти правила выражаются следующим образом: 1. h, не, 2. и, 3. или. Для изменения порядка предшествования можно использовать скобки. Рассматриваемый подход можно применять к вычислению значений лингвистической переменной, при условии, что составные термы, представляющие эти значения, могут быть генерированы лишенной контекста грамматикой. Чтобы вычислить значения составного терма t, необходимо провести синтаксический анализ t в терминах определенной грамматики. Тогда, зная синтаксическое дерево t, можно использовать соотношения, порождаемые правилами вывода, для составления системы уравнений, решением которой является значение t. В общем случае число элементов множества Т может быть бесконечным, и тогда как для порождения элементов множества Т, так и для вычисления их смысла необходимо применять некоторый алгоритм. Говорят, что лингвистическая переменная N структурирована, если ее терм-множество Т и функцию М, которая ставит в соответствие каждому элементу терм-множества его смысл, можно задать алгоритмически. В качестве простого примера рассмотрим лингвистическую переменную Возраст. Допустим, что терм-множество этой переменной можно записать в виде: Т (Возраст) = старый + очень старый + очень очень старый +... В этом случае каждый терм множества Т имеет вид старый или очень... очень старый. Чтобы вывести это правило в более общем виде, можно рассматривать данное представление для Т (Возраст) как решение уравнения Т = старый + очень Т, (4) которое означает, что множество Т состоит из терма старый и термов, состоящих из слова очень и некоторого терма из Т. Данное уравнение (4) можно решать итеративным способом, используя рекуррентное соотношение Тi+1 = старый + очень Тi, i = 0,1,2,... (5) Взяв пустое множество Т0 = Т1 = старый, Т2 = старый + очень старый, Т3 = старый + очень старый + очень очень старый,. ... Т.е. решение уравнения (4) имеет вид Т = старый + очень старый + очень очень старый +... (6) Таким образом, для данного примера синтаксическое правило выражается уравнением (4.) и его решением (6). Эквивалентное представление для синтаксического правила можно охарактеризовать следующей системой подстановок: Т ® старый, (7) Т ® очень Т, (8) для которой уравнения (4) играет роль алгебраического представления. В этом случае терм в Т может быть порожден процедурой, включающей в себя последовательное применение правил (7) и (8), начиная с символа Т. Таким образом, если Т заменить на очень Т и затем Т заменить на старый, получаем терм очень старый. Аналогично терм очень очень старый можно получить из Т по следующей цепочке подстановок: Т ® очень Т ® очень очень Т ® очень очень старый. Обращаясь к семантическому правилу, отметим, что для вычисления смысла такого терма требуется знать смысл терма старый и модификатора очень. Терм старый играет роль первичного терма, т.е. терма, смысл которого должен быть задан заранее с тем, чтобы можно было вычислять смысл составных термов в Т. Терм очень действует как лингвистическая неопределенность, т.е. как модификатор смысла следующего за ним терма. Пусть теперь лингвистическая переменная Возраст имеет терм-множество вида: Т (Возраст) = молодой + старый + не молодой + не старый + + не молодой и не старый + очень молодой + очень старый +... (9) Если отождествить союз и с операцией пересечения, или - с операцией объединения, отрицание не с операцией взятия дополнения и модификатор очень - с операцией концентрации, то можно записать смысл типичного значения переменной Возраст. Например: М (не молодой) = М (не очень молодой) = М (не очень молодой и не очень старый) = Эти уравнения выражают, по сути дела, смысл составного терма как функцию смысла составляющих его первичных термов. Более общий подход базируется на определении семантики контекстно-свободных языков. Например, можно проверить, что терм-множество (9) порождается контекстно-свободной грамматикой VN = T + A + B + C + D + E, (11) в то время как множество терминальных символов (компоненты термов в Т) выражаются в виде VT = молодой + старый + очень + не + и + или + (), (12) а система подстановок P имеет вид Т ® A, Т ® T или A, A ® B, A ® A и B, B ® C, B ® не C, C ® (T), C ® D, C ® E, D ® очень D, E ® очень E, D ® молодой, E ® старый. (13) Систему P можно представить алгебраически в виде следующей системы уравнений: Т = A + Т или A, A = B + A и B, B = C + не С, (4..31) C = (T) + D + E, D = очень D + молодой, E = очень E + старый. Решение этой системы уравнений относительно Т является терм-множество Т, описываемое выражением (9). Решение системы (13) можно получить итеративно, используя соответствующие рекуррентные соотношения. Итерирование порождает все больше и больше термов в каждой из синтаксических категорий (T,A,B,C,D,E). В более общепринятой процедуре терм в Т, скажем, не молодой и не старый порождается грамматикой G путем последовательных замен (подстановок) с использованием системы P, причем каждая цепочка подстановок начинается с Т и заканчивается этим термом: T ® A ® A и B ® B и B ® не C и B ® не C и не C ® не D и не C ® ® не D и не E® не молодой и не E ® не молодой и не старый. (14) Эту цепочку можно получить, используя синтаксическое дерево (рис. 15), представляющее структуру терма не молодой и не старый с использованием синтаксических категорий T,A,B,C,D,E. Описанная процедура порождения термов в Т грамматикой G в сущности составляет синтаксическое правило для переменной Возраст. Семантическое правило для переменной Возраст индуцируется описанным выше синтаксическим правилом, так как смысл терма в Т частично определяется его синтаксическим деревом. В частности, каждому правилу подстановки ставится в соответствие некоторое отношение между нечеткими множествами, обозначенные определенными терминальными и нетерминальными символами. Эта двойственная система подстановок и связанных с ней уравнений типа (10) используется для вычисления смысла составных термов из Т следующим образом.
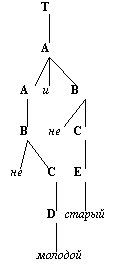
Рис. 15. Синтаксическое дерево для значения не молодой и не старый. 1. Рассматриваемый терм подвергается грамматическому разбору, в результате чего получается синтаксическое дерево. Конечными вершинами этого дерева являются: а) первичные термы, смысл которых определяется априори, б) названия модификаторов (т.е. лингвистических неопределенностей, союзов, отрицания и т.п.), в) маркеры, такие, как скобки, которые облегчают грамматический разбор. 2. Первичным термам на конечных вершинах дерева назначается их смысл и затем с помощью системы подстановок Р и соответствующих уравнений вычисляется смысл ближайших к ним нетерминальных символов. 3. После этого дерево урезают так, чтобы вычисленные терминальные символы оказались конечными вершинами оставшегося поддерева. Этот процесс повторяется до тех пор, пока не будет вычислен смысл терма, соответствующего корню исходного синтаксического дерева. Основное назначение описанной процедуры состоит в том, чтобы связать смысл составного терма со смыслом составляющих его первичных термов посредством системы уравнений, определяемой грамматикой, порождающей термы в Т.
|
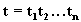 , который представляет собой сочетание элементарных термов
, который представляет собой сочетание элементарных термов 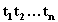 . Эти элементарные термы можно разбить на 4 категории:
. Эти элементарные термы можно разбить на 4 категории: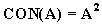
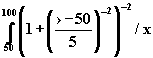 ,
, в качестве начального значения, получаем
в качестве начального значения, получаем молодой,
молодой,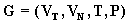 , в которой нетерминальные символы (синтаксические категории) обозначаются
, в которой нетерминальные символы (синтаксические категории) обозначаются