Корреляционные зависимости
а — переменные x и у не коррелируют; б — слабая отрицательная корреляция; в — сильная положительная линейная корреляция т. е. направление «облачка» (см. рис. выше). Распространенный способ решения этой задачи — метод наименьших квадратов отклонений наблюдаемых значений у от рассчитываемых по формуле корреляционного уравнения. Особенно широко применяется К. а. в теории производственных функций, в разработке разного рода нормативов на производстве, а также в анализе спроса и потребления. Корреляция [correlation] — величина, характеризующая взаимную зависимость двух случайныхвеличин Х и У — безразлично, определяется ли она некоторой причинной связью или просто случайным совпадением (ложной корреляцией). Для того, чтобы определить эту зависимость, рассмотрим новую случайную величину — произведение отклонения значений х от его среднего Мх и отклонения у от своего среднего My. Можно вычислить среднее значение новой случайной величины: rxy = М{(х - Мх)(у - Му)}. Это среднее получило название корреляционной функции или ковариации. На ее основе (делением на корень произведения дисперсий sx 2 sy 2, т. е. на произведение стандартных отклонений) строится коэффициент корреляции: rxy Rxy =-------- sx sy
При нелинейной зависимости аналогичный показатель носит название индекса корреляции. Если x и у — независимы, то Rxy = 0. Если же х и у - зависимы, то обычно Rxy ¹ 0. Причем в тех случаях, когда зависимость полная, то либо Rxy = 1 (x и у растут или уменьшаются одновременно), либо Rxy= - 1 (при увеличении одной из них другая — уменьшается). Следовательно, коэффициент корреляции может изменяться от -1 до + 1. К. используется для выявления статистической зависимости величин при обработке данных. Наряду с указанной формулой используется ряд формул эмпирического определения тесноты корреляционной связи между наблюдаемыми признаками исследуемых величин.
Л Лаг [lag, time—lag ], временной Л., запаздывание — экономический показатель, отражающий отставание или опережение во времени одного экономического явления по сравнению с другим, связанным с ним явлением. Капиталовложения в промышленность, например, дают отдачу не сразу, а через несколько лет, когдa будут построены и освоены новые производства. Поэтому, изучая влияние капиталовложений на развитие хозяйства, приходится относить это влияние не на ближайший год, а на третий, четвертый и т. д. Подобные явления отражаются в экономико-математических моделях в машинной имитации через так называемые распределенные Л. различных видов. В модели с распределенным Л. результат рассматривается не как функция затрат некоторого определенного года, а как функция затрат последовательного ряда лет прошлого периода: t yt = å wixt-i + ut, t = 0 где yt — результат в году t; xt-i — затраты в году t — i; t — максимальный срок запаздывания; ut — ошибка уравнения (помехи); wi — весовые коэффициенты, характеризующие сравнительное значение отдельных лет для результата. Наиболее явно выделяются Л. при анализе циклических, в том числе сезонных колебаний. Важными видами Л. являются инвестиционный Л., характеризующий время оборота всех производственных капиталовложений (включая вложения в оборудование), и строительный Л., характеризующий средний срок строительства производственного объекта, а также запаздывание предложения товаров от их производства, запаздывание спроса от предложения товаров, запаздывание потребления от спроса, запаздывание выпуска кадров от начала их обучения, и т. д. В эконометрических моделях выделяются три группы запаздываний: а) когда значение эндогенной переменной в данный момент времени зависит от значении той же переменной в предшествующие моменты времени; б) когда данная эндогенная переменная может влиять на другую (или другие) эндогенную переменную только по истечении какого-то периода времени; в) когда значение эндогенной переменной определяется значением экзогенной переменной более раннего времени. В общей модели распределенного Л. последовательность коэффициентов wi (t = 0, 1, 2,...) называется структурой Л.
Линейная модель [linear model] — модель, отображающая состояние или функционирование системы таким образом, что все взаимозависимости в ней принимаются линейными. Соответственно, она может формулироваться в виде одного линейного уравнения или системы линейных уравнений. Причем, в ряде случаев нелинейность взаимозависимостей может приводиться к линейной форме путем математических преобразований переменных: например, в нелинейных соотношениях: у = aebx, у = axb, у = a + b ----. x В первом и втором случаях логарифмирование обеих частей уравнений обеспечивает связь линейную в логарифмах: ln y = lna + bx; y = lna + b lnx; a в третьем — линейно зависимы у и I/ х. Л. м., учитывающую стохастику, в общей форме можно записать так: уi = ai + bxi + ui В этой «регрессионной линейной модели» следующие обозначения: - свободный член a и вектор b — параметры, и — случайная ошибка, математическое ожидание которой равно нулю; - xi — вектор переменных, идентифицированных как оказывающих воздействия на переменную у (т. е. управляющих переменных). Соответственно, Л. м. в виде системы уравнений в общей форме записывается: уi = ai + Bxi + ui, где: уi –i-я зависимая переменная; B = [ bij ] — матрица параметров модели; xi - вектор управляющих переменных в i -м уравнении.
Линейная функция [linear function] — функция вида ах +b = у. Основное ее свойство: приращение функции пропорционально приращению аргумента: Л. ф. изображается на графике прямой линией. Если b=0 функция называется однородной, причем однородная Л. ф. многих переменных описывается линейной формой. Линейные уравнения [linear equations] — уравнения, в которые неизвестные входят в 1-й степени (линейно) и нет членов, содержащих произведения неизвестных или экспоненты. Система линейных уравнений может иметь либо единственное решение, либо бесконечное множество решений (неопределенная система), либо ни одного решения (несовместная система). Общий вид системы Л. у.: a11x1 + a12x2 + … + a1nxn = b1 a 21 x 1 + a 22 x 2 + … + a 2n x n = b 2 ………………………………………… am 1 x 1 + am 2 x 2 +… + amnxn = bm . Здесь aij, bi, i = 1, 2 … n; j = 1, 2, …, m - произвольные числовые коэффициенты, числа bi обычно называют свободными членами. В случае, если все bi = 0, систему называют однородной. При решении системы уравнений широко применяются определители, составленные из коэффициентов aij при неизвестных. В векторно-матричной записи n å aij ixij = bi, , А х = b j=1 Здесь A = [ aij ] — матрица, состоящая из коэффициентов при неизвестных системы («м а т р и ц а с и с т е м ы»).
Логистическая функция [logistic function] — функция, кривая которой сначала растет медленно, потом быстро, а затем снова замедляет свои рост, стремясь к какому-то пределу. Л. ф. часто применяются в анализе спроса на товары, обладающие способностью достигать некоторого уровня насыщения. М Макроподход и микроподход [macro- and microapproach] — противоположные подходы, зависящие главным образом от того, с какой позиции наблюдается объект. При макроподходе объект (будь это такая сложная система, как народное хозяйство, или такая сложная его подсистема, как промышленность, или более простой объект — предприятие, участок) рассматривается, так сказать, снаружи, как единое целое. Это означает, что внутренние связи, внутреннее устройство объекта игнорируются, а изучаются только входы и выходы, их взаимная зависимость. В кибернетике такой подход связывают с понятием «черного ящика»). В экономике он означает изучение обобщающих показателей функционирования экономической системы, безотносительно к тому, продуктом каких взаимодействий составляющих ее элементов являются эти показатели. При микроподходе же объект рассматривается как бы изнутри. Изучаются внутренняя структура, внутренние связи между его элементами. Микроподход вовсе не означает «микроскопический», мелкий: при изучении народного хозяйства страны микроподход может означать и анализ взаимосвязей между такими гигантскими элементами, как промышленность и сельское хозяйство, производство и потребление и т. д. Одна из кардинальных и еще далеко не решенных задач экономической науки — проблема соединения микроанализа и макроанализа реальных экономических систем разных типов, т. е. выведения из закономерностей экономического поведения и взаимодействий отдельных элементов системы макроэкономических характеристик ее поведения в целом (задача, аналогичная известной задаче физики: установить связь между движением отдельных атомов газа и его общими характеристиками, т. е. температурой, объемом, давлением). Различные математические подходы к такому соединению (иногда его называют «а г р е г и р о в а н и е м микротеории») исследуются в рамках ряда экономико-математических направлений. Различие между рассматриваемыми терминами проводится не всегда строго. Приставка «макро», в частности, привилась к экономической дисциплине — «макроэкономике», которая оперирует такими понятиями, как «м а к р о м о д е л и р о в а н и е» (укрупненное моделирование экономических процессов всего народного хозяйства), «макроэкономическая модель» даже «макропоказатели» (такие, например, как совокупный общественный продукт, национальный доход и др.). При этом макроэкономисты, вопреки указанному выше разделению, рассматривают экономику не только как одно целое, что естественно для макроподхода, но и членят ее обычно на ряд отраслей или секторов, изучая их взаимозависимости и связи.
Макроэкономическая модель [macroeconomic model] то же: м а к р о м о д е л ь, агрегированная, агрегатная модель, — экономике-математическая модель, отражающая функционирование народного хозяйства как единого целого. Макромодели оперируют крупноагрегированными, как правило, стоимостными показателями (например, национальный доход, валовые капиталовложения и др.). Четкого отграничения макромоделей от микромоделей пока нет. Безусловно лишь, что к первым относятся наиболее обобщенные глобальные модели. Что же касается моделей, в которых учитывается членение народного хозяйства на крупные подсисте мы, например, секторы (подразделения общественного производства), отрасли и регионы, то одни авторы относят их к микромоделям, другие — к макромоделям. Макромодели используются для теоретического анализа наиболее общих закономерностей функционирования и развития народного хозяйства. (Например, агрегированные теоретико-аналитические модели теории экономического роста ). М. М. может служить также основной моделью в системе моделей планирования и управления народным хозяйством. Определяемые в ней наиболее общие показатели конкретизируются в частных моделях следующих уровней, уточняясь в свою очередь, по результатам этих расчетов. По характеру зависимостей макромодели (как и всякие модели) могут быть детерминированными и вероятностными(стохастическими), по роли временного фактора — статическими и динамическими, по представлению переменных (включая переменную времени)— дискретными и непрерывными. Математическая статистика [ mathematical statistics] — раздел математики, посвященный методам и правилам обработкии анализа статистических данных (т. е. сведений о числе объектов, обладающих определенными признаками в какой-либо более или менее обширной совокупност и). Сами методы и правила строятся безотносительно к тому, какие статистические данные обрабатываются (физические, экономические и др.), однако обращение с ними требует обязательного понимания сущности явления, изучаемого с помощью этих правил. К экономике М. с. применима по той причине, что экономические данные всегда представляют собой статистические сведения, т. е. сведения об однородных совокупностях объектов и явлений. Такими однородными совокупностями могут быть выпускаемые промышленностью изделия, персонал промышленности, данные о прибылях предприятий и т. д. В настоящее время существуют разные определения сущности М. с., и не следует удивляться, если вы увидите в одной книге, вопреки сказанному выше, утверждение, что М. с, — это наука о принятии решений в условиях неопределенности, а в другой — что это «наука, объясняющая данные статистических наблюдений при помощи вероятностных моделей». Некоторые авторы считают, что она — раздел теории вероятностей, а другие, — что она лишь связана с этой теорией, представляя собой отдельную от нее науку. Наконец, распространено расширенное понимание предмета М. с. как охватывающей не только вероятностные аспекты, но и так называемую прикладную статистику(«анализ данных»). В общем случае, анализ статистических данных методами М. с. позволяет сделать два вывода: либо вынести искомое суждение о характере и свойствах этих данных или взаимосвязей между ними, либо доказать, что собранных данных недостаточно для такого суждения. Причем выводы могут делаться не из сплошного рассмотрения всей совокупности данных, а из ее выборки, как правило, случайной (последнее означает, что каждая единица, включенная в выборку, могла быть с равными шансами, т. е. с равной вероятностью, заменена любой другой). Центральное понятие М. с. — случайная величина — всякая наблюдаемая величина, изменяющаяся при повторениях общего комплекса условий, в которых она возникает. Если сам по себе набор, перечень значении этой величины неудобен для их изучения (поскольку их много). М. с. дает возможность получить необходимые сведения о случайной величине с существенно меньшим количеством чисел. Это объясняется тем, что статистические данные подчиняются таким законам распределения (или приводятся к ним порою искусственными приемами), которые характеризуются всего лишь несколькими параметрами, т. е. характеристиками. Зная их, можно получить столь же полное представление о значениях случайной величины, какое дается их подробным перечислением в очень длинной таблице. (Характеристиками распределения являются среднее, медиана, мода, дисперсия и т. д.). Если изучаются взаимосвязи между значениями разных случайных величин, то необходимые сведения для этого дают коэффициенты корреляции между ними. Когда совокупность анализируется по одному признаку, имеем дело с так называемой одномерной статистикой, когда же рассматривается несколько признаков — с многомерными статистическими методами. М. с. охватывает широкий круг одномерных и многомерных методов и правил обработки статистических данных: от простых приемов статистического описания (выведение средней, а также степени и характера разброса исследуемых признаков вокруг нее, группировка данных по классам и сопоставление их характеристик и т. д.), правил отбора фактов при выборочном их рассмотрении до сложных методов исследования зависимостей между случайными величинами: выявление связей между ними — корреляционный анализ, оценка величины случайной переменной, если величина другой или других известна — регрессионный анализ, выявление наиболее важных скрытых факторов, влияющих на изучаемые величины, — факторный анализ, определение степени влияния отдельных неколичественных факторов на общие результаты их действия (например, в научном эксперименте) — дисперсионный анализ. Перечисленные области составляют основные дисциплины, входящие в М.с. К ним примыкают также быстро развивающиеся упоминавшиеся выше методы " анализа данных", не основанные на традиционной для М.с. предпосылке вероятностной природы обрабатываемых данных. Для экономических исследований большое значение имеет также анализ стохастических процессов, в том числе " марковских процессов". Задачи М.с. в экономике можно разделить на пять основных типов: первый - оценка статистических данных; второй - сравнение этих данных с каким-то стандартом и между собой (это имеет особое значение при эксперименте или, например, в контроле качества на предприятиях); третий - исследование связей между статистическими данными и их группами. Эти три типа позволяют вынести суждение описательного характера об изучаемых явлениях, подверженных по каким-то причинам искажающим случайным воздействиям. Следующий, четвертый тип задач связан с нахождением наилучшего варианта измерения изучаемых данных. И, наконец, пятый тип задач связан с проблемами предвидения и развития, здесь важной место занимают задачи анализа временных рядов. Для экономики особенно ценно то, что М. с. позволяет на основании анализа течения событий в прошлом, т. е. изучения выбранных на определенные даты сведений о характерных чертах системы предсказать вероятное развитие изучаемого явления в будущем (если не изменятся существенно внешние или внутренние условия). В управлении хозяйственными и производственными процессами применяются различные математико-статистические методы. На них основаны многие методы исследования операций, в том числе — методы теории массового обслуживания, позволяющие наиболее эффективно организовывать ряд процессов производства и обслуживания населения; теории расписаний, предназначенной для выработки оптимальной последовательности производственных, транспортных и других операций; теории решений; теории управления запасами, а также теории планирования экспериментаи выборочного контроля качества продукции; сетевые методы планированияи управления. В эконометрических исследованиях на основе математико-статистической обработки данных строятся экономико-математические (экономико-статистические) модели экономических процессов, проводятся экономические и технико-экономические прогнозы. Широкое распространение математико-статистических методов в общественном производстве, а также в других областях социально-экономической жизни общества (здравоохранение, экология, естественные науки) опирается на развитие электронно-вычислительной техники. Для решения типовых задач математико-статистической обработки данных созданы и применяются многочисленные стандартные прикладные программы для ЭВМ.
Математическая экономия [mathematical economics] — наука, изучающая те же вопросы, что эконометрика, только без статистической конкретизации экономических параметров, в виде общих математических зависимостей. На ее основе разработан разнообразный и мощный математический аппарат, основанный на методах функционального анализа, топологии, теории дифференциальных уравнений и др., охватывая своим анализом проблемы экономического роста, равновесия, oптимального управления и т. д.
Математическое ожидание (или среднее значение) – [expected value] — для дискретной случайной величины Х равно сумме произведений возможных значений этой величины на их вероятности SxР (x), а для непрерывной случайной величины — интегралу: ò xP(x)dx (хÎ А). Обозначается обычно: Мх или Ех. Матрица [matrix] — система элементов (чисел, функций и других величин), расположенных в виде прямоугольной таблицы, над которой можно производить определенные действия. Таблица имеет следующий вид:
a21 a22 … a2n A =... ... ... am1 am2 … amn
В экономике применяются действительные числа, соответственно М. из таких чисел называется действительной. В показанной М. т строк и п столбцов, следовательно, это — М. размера m х n. При m = n имеем квадратнуюМ. (такова М. межотраслевого баланса (МОБ) в стоимостном выражении). В этом случае число т=п называется порядком М. При т¹ п это просто М. (ею может быть, например, натуральный межотраслевой баланс). Э л е м е н т М. в общем виде обозначается aij — это показывает, что мы имеем число, расположенное на пересечении i- й строки и j -го столбца (разумеется, i и j можно заменить любой другой буквой, но такое обозначение — наиболее распространенное). Соответственно, М. А может обозначаться [ аi j]. М. размера m x 1 называется вектор-столбец, а размера 1х п — вектор-строка. Над М. можно производить ряд математических действий (с помощью операцийнад ихэлементами): сложение, умножениена скаляр, умножениенаМ., обращение, транспонирование идр.. М., транспонированная по отношению к A =[ ij ], есть М. того же размера, у которой столбцы поменялись местами со строками. Иначе говоря, это М. [ аji ]. Обратные и транспонированные М. имеют очень большое применение в моделях МОБ. В них также широко применяется разбиение М. на меньшие подматрицы (б л о к и). М. коэффициентов систем уравнений — инструмент решения задач математического программирования, задач линейной алгебры и др.
Метод Монте-Карло [Monte— Carlo technique] (статистических испытаний) — один из методов статистического моделирования, основанный на кибернетической идее " черного ящика ";. Он применяется в тех случаях, когда построение аналитической модели явления трудно или вовсе неосуществимо, например, при решении сложных задач теории массового обслуживания и ряда других задач исследования операций, связанных с изучением случайных процессов. Применение М. М.-К. можно проиллюстрировать примером из области теории очередей. Предположим, надо определить, как часто и как долго придется ждать покупателям в очереди в магазине при заданной его пропускной способности (допустим, для того, чтобы принять решение, следует ли расширять магазин). Подход покупателей носит случайный характер, распределение времени подхода может быть установлено из имеющейся информации. Время обслуживания покупателей тоже носит случайный характер и его распределение тоже может быть выявлено. Таким образом, имеются два стохастических или случайных процесса, взаимодействие которых и создает очередь. Теперь, если наугад перебирать все возможности (например, число покупателей, приходящих за час), сохраняя те же характеристики распределения, можно искусственно воссоздать картину этого процесса. Повторяя такую картину многократно, каждый раз меняя условия (число подходящих покупателей), можно изучать получаемые статистические данные так, как если бы они были получены при наблюдении над реальным потоком покупателей. Точно так же можно воссоздать искусственную картину работы самого магазина: здесь распределение будет повторять распределение времени обслуживания отдельного покупателя. Получаются опять два стохастических процесса. Их взаимодействие даст " очередь" с примерно такими же характеристиками (например, средней длиной очереди или средним временем ожидания), какими обладает реальная очередь. Таким образом, смысл М. М.-К. состоит в том, что исследуемый процесс моделируется путем многократных повторений его случайных реализаций. Единичные реализации называются статистическими испытаниями — отсюда второе название метода. Остается определить что такое выбор вариантов наугад (или механизм случайного выбора). В простых случаях для этого можно применять бросание игральной кости (классический учебный прием), но на практике используют таблицы случайных чисел либо вырабатывают (генерируют) случайные числа на ЭВМ, для чего имеются специальные, которые называются.
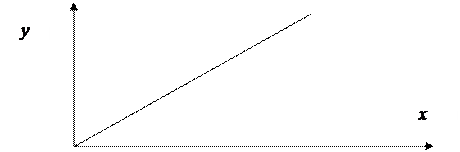
Метод наименьших квадратов [least—square technique] — математический (математико-статистический) прием, служащий для выравнивания динамических рядов, выявления формы корреляционной связи между случайными величинами и др. Состоит в том, что функция, описывающая данное явление, аппроксимируется более простой функцией (или линейной комбинацией таких функций). Причем, последняя подбирается с таким расчетом, чтобы средне-квадратичное отклонение фактических уровней функции в наблюдаемых точках от выровненных было наименьшим. В качестве аппроксимирующих функций применяются линейная (выравнивание по прямой линии), параболическая, экспоненциальная и др. Пример выравнивания динамического ряда по прямой см. на нижеприведенном рисунке.
Микроэкономическая модель [ microeconomic model] — экономико-математическая модель, отражающая функционирование и структуру звена хозяйственной системы, взаимодействие его составных частей (см. Макроподход и микроподход). Четкого отграничения микромоделей от макромоделей пока нет. Как правило, этот термин относят, однако, к изучению деятельности таких ведущих звеньев экономики, как предприятие и объединение. Кроме того, к микромоделям относят некоторые модели, связанные с социально-экономическими процессами (например, модели спроса и предложения).Их отличия от макромоделей: большая зависимость от внешней среды, дезагрегация показателей. Так же как и макроэкономические модели, микромодели могут быть статическими и динамическими, детерминированными и вероятностными, дискретными и непрерывными. Многомерный статистический анализ [multidimensional, multivariate statistical analysis] — раздел математической статистики, посвященный математическим методам построения оптимальных планов сбора, систематизации и обработки многомерных статистических данных, направленным на выявление характера и структуры взаимосвязей между компонентами исследуемого многомерного признака и предназначенным для получения научных и практических выводов. Включает дискриминантн ы й а н а л и з, кластерный анализ и другие математико-статистические методы, как правило, не опирающиеся на предпосылку о вероятностном характере исследуемых зависимостей. В частности, дискриминантный анализ предназначен для решения задач, связанных с разделением совокупностей наблюдений (элементарных д а н- н ы х). Если у исследователя имеется по одной выборке из каждой неизвестной ему генеральной совокупности (такую выборку называют «обучающей»), то с помощью методов дискриминантного анализа удается приписать некоторый новый элемент (наблюдение х) к своей генеральной совокупности. Кластер-анализ позволяет разбивать исследуемую совокупность элементов (координатыкоторых известны) таким образом, чтобы элементы одного класса находились на небольшом расстоянии друг от друга, в то время как разные классы были бы на достаточном удалении друг от друга и не разбивались бы на столь же взаимоудаленные части. Методы многомерного анализа сложны с вычислительной точки зрения и потому реализуются, как правило, на ЭВМ, для которых созданы необходимые типовые программы. Модель [model] — логическое или математическое описание компонентов и функций, отображающих существенные свойства моделируемого объекта или процесса (обычно рассматриваемых как системы или элементы системы). М. используется как условный образ, сконструированный для упрощения их исследования. Природа моделей может быть различной (общепризнанной единой классификации моделей в настоящее время не существует): материальные или вещественные модели (например, модель самолета в аэродинамической трубе); з н а к о в ы е модели двух типов: графические (чертеж, географическая карта) и математические (формула, описывающая гравитационное вааимодействие двух тел); материально идеальные (" деловая игра"); словесное описание объекта (явления, процесса) можно также рассматривать как его модель. В управлении хозяйственными процессами наибольшее значение имеют математические, прежде всего, экономико-математические модели, часто объединяемые в комплексы моделей и системы моделей. Н Нормальное распределение [normal distribution], или распределение Гаусса, — распределение вероятностей случайной величины X, возникающее обычно, когда Х представляет собой сумму большого числа независимых случайных величин, каждая из которых играет в образовании всей суммы незначительную роль. Н. р. унимодально описывается колоколообразной (симметричной) кривой; его средняя (математическое ожидание) совпадает с модой. Н. р. чрезвычайно широко используется в математической статистике. В частности, в моделях регрессии ошибка принимается распределенной по этому закону. Предпосылка Н. р. учитывается и в большинстве критериев статистической проверки гипотез. О Обращение матрицы [matrix inversion] — операция получения матрицы, обратной к заданной. Если задана матрица А, то обратная ей матрица обозначается А -1 и вычисляется в общем виде так: [ Aji ] А -1 = [ aij ] –1 = --------- det A Здесь det A — детерминант (определитель) этой матрицы, [ Aji ] — транспонированная матрица алгебраических дополнений. При больших размерах матрицы вычисление по этой формуле элементов матрицы А -1 требует очень громоздких расчетов. Поэтому изыскиваются различные более эффективные методы О.м. на ЭВМ. С помощью обратной матрицы определяются в межотраслевом балансе валовые выпуски продукции, необходимые для получения заданных компонентов конечного продукта (т. е. осуществляется решение уравнений МОБ)
Определитель матрицы, детерминант [determinant] — число, соответствующее квадратной матрице и полученное путем ее преобразования по определенному правилу. Обычное обозначение det A. Например, определитель (второго порядка) матрицы:
Обозначается
и вычисляется следующим образом: det А = а11а22 — а12а21 0пределитель, в котором вычеркнуты произвольная строка, например i -ая и произвольный столбец, например j -ый, называется минором. Он имеет (n - 1)-й порядок, т. е. порядок на 1 меньше, нежели исходный определитель. Определители используются при обращении матриц, при решении систем линейных уравнений, в частности при решении задач межотраслевого баланса.
Оценка параметров модели (ее параметризация) [parameter estimation] — 1. Этап построения экономико-математической модели, например эконометрической модели, заключается в определении численных значений существенных параметров модели, выявленных на предварительных этапах анализа исследуемого объекта или процесса. Параметры модели численно оцениваются по данным, полученным путем экономического эксперимента и статистического наблюдения - чаще всего методом наименьших квадратов, методом максимального правдоподобия, а также некоторыми другими статистическими методами. На этой основе можно производить различные операции над моделью, например, строить прогнозы поведения системы. 2. Количественное значение оцененных параметров
Ошибка [error, deviation]— 1.В экономико-математическом моделировании — элемент модели, отражающий суммарный эффект не учтенных в ней непосредственно (т. е. не признанных существенными) систематических и случайных факторов, воздействующих на экзогенные переменные. 2. В математической статистике то же, что отклонение или разброс около истинного значения рассматриваемой случайной величины. Ошибки в наблюдениях [observation bias] — в выборочных методах возникают тогда, когда пропускают то, что в действительности имеет место (например, при наблюдении экономических явлений, в задачах поиска). Ошибки в прогнозировании [ forecasting bias] — расхождения между данными прогноза и действительными (фактическими) данными. Закономерности О. п. изучаются математико-статистическими методами. Различаются четыре вида ошибок: исходных данных, модели прогноза, согласования, стратегии. Ошибки исходных данных связаны, главным образом, с неточностью экономических измерений, не качественностью выборки, искажением данных приих агрегировании и т. д. Ошибки модели прогноза возникают вследствие упрощения и несовершенстватеоретических построений, экспертных оценок и т. д. Правильность моделипрогноза(в том числе оценки ее параметров)проверяется ретроспективным расчетом, который можно сопоставить с действительным ходом исследуемого процесса. Однако и это не дает полной гарантии качества прогноза на будущее, так как условия могут измениться. Ошибки согласования часто происходят из-за того, что статистические данные в народном хозяйстве подготавливаются разными организациями, которые применяют различную методологию расчетов. Ошибки стратегии — результат, главным образом, неудачного выбора оптимистического или пессимистического, вариантов прогноза.
П Пассивный (безусловный) статистический прогноз [passive forecast] — прогноз развития, основанный на изучении статистических данных за прошлый период и переносе выявленных закономерностей на будущее. При этом внешние факторы, воздействующие на систему, принимаются неизменными и считается, что ее развитие основывается только на собственных, внутренних тенденциях. Примером пассивного прогноза является экстраполяция сложившихся темпов роста того или иного показателя. Допустим, в среднем за десять лет национальный доход страны рос на 5 % в год. Делаем вывод (экстраполируем): значит, и следующие несколько лет темпы останутся прежними. Ясно, что такой прогноз реален только на очень короткий срок и далеко не для всех экономических показателей, а лишь для наиболее инерционных, устойчивых.
Переменная модели [variable] — переменная величина, включенная в модель и принимающая различные значения в процессе решения экономико-математической задачи. Независимые переменные принимают значения координат моделируемой системы; они могут быть управляемыми или сопутствующими. Зависимые переменные (функции) вы
|