Парные распределения.
Обработка социологических данных с помощью одномерных частотных распределений, как правило, является исходным этапом анализа собранной информации. Вместе с тем наиболее интересные для социологов вопросы связаны с одновременным анализом значений более одной переменной. Процесс анализа собранных данных предполагает формирование гипотез типа: «социальные группы с разным уровнем образования (дохода, должностью, местом жительства и т.д.) отличаются по электоральным предпочтениям (степенью удовлетворенности жизнью и т.д.)». Другими словами, допускается, что существует переменная (такая как «принадлежность к определенной социальной группе»), которая объясняет поведение других переменных. Таким образом, есть объясняющие переменные, которые называются независимыми, и объяснимые переменные – зависимые. Корреляционный анализ основан на расчете отклонения значений изучаемого признака от линии регрессии (от лат. regression – возврат, в данном случае – возврат к средней) – условной линии, к которой эти значения тяготеют. Чем меньше разброс значений, тем сильнее связи.
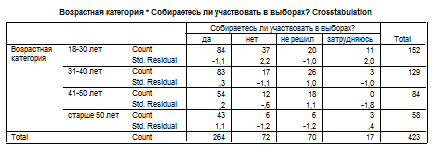
Наиболее частыми инструментами изучения взаимосвязи двух переменных являются двумерные методы анализа таблицы сопряженности. При анализе зависимостей двух переменных важнейшим является вопрос о том, какую из переменных считать зависимой, то есть подверженной влиянию, а какую – независимой, то есть влияющей. Например, примем переменную «возраст» как независимую переменную, а переменную «электоральная активность» как зависимую. По гипотезе исследования возраст респондента оказывает влияние на готовность прийти на выборы. В таблице сопряженности (парном распределении) данные будут выглядеть следующим образом.
По данным в таблице можно увидеть, что действительно есть прямая зависимость возраста респондента и его электоральной активности. Среди респондентов старше 50 лет подавляющее большинство – 74,1% - готово голосовать на выборах, что свидетельствует о высокой электоральной активности людей старшей возрастной категории. Среди молодых респондентов в возрасте до 30 лет готовность голосовать на выборах продемонстрировали всего лишь 55,3% респондентов, почти четверть из них – 24,3% - заявили, что не будут участвовать в голосовании. Таким образом, чем старше возраст респондентов, тем выше их электоральная активность.
Если же принять переменную «электоральная активность» за независимую, а переменную «возраст» за зависимую, то можно получить несколько другие данные таблицы, где нормирование можно провести не от сумм по строкам, а от сумм по колонкам.
В этом случае распределения необходимо сравнивать по разным колонкам таблицы, а не по строкам. Из тех респондентов, кто не собирается голосовать на выборах, большинство составляет молодежь в возрасте до 30 лет (51,4%), респондентов в возрасте 50 лет среди них всего 8,3%. Таким образом, низкая электоральная активность в большей степени характерна для молодых людей, чем для старшего поколения.
Исследуем эту зависимость чуть более детально; для этого нам понадобится точно ответить на следующие вопросы:
Для создания таблицы с переменными «возраст» и «готовность голосовать», нужно сначала выделить переменную «возраст» и с помощью кнопки с треугольником переместить в список Row(s) (Строки), а переменную «готовность голосовать» в список Column(s) (Столбцы). Раздел Layer 1 of 1 диалогового окна позволяет построить таблицу сопряженности для трех и более переменных. Для получения данных в процентах нужно щелкнуть на кнопке Cells (Ячейки), открыть диалоговое окно Crosstabs: Cells Display.
По умолчанию установлен флажок Observed (Наблюдаемые) в группе Counts (Значения), так как наблюдаемые частоты являются главной вычисляемой величиной. При установке флажка Expected (Ожидаемые) в группе Counts (Значения) отображается значение ожидаемой частоты для каждой ячейки. Ожидаемая частота – количество респондентов, которые должны быть в ячейках таблицы в случае независимости переменных. Сопоставляя эти ожидаемые частоты с наблюдаемыми частотами мы можем судить о том, действительно ли два номинальных признака независимы. Чем больше расхождение наблюдаемых и ожидаемых частот, тем эти два признака сильнее связаны друг с другом. При установке флажка Unstandardized (Нестандартизированные) в группе Residuals (Остатки) отображается разность между наблюдаемой и ожидаемой частотами.
Как показывают данные в таблице реальные частоты Count и ожидаемые частоты Expected Count разные в большинстве ячеек таблицы. Следовательно, можно сделать вывод о том, что независимость переменных не подтверждается.
Установление соответствия между наблюдаемыми и ожидаемыми значениями возможно при применении критерия независимости χ2 (хи-квадрат), величина которого определяется, как сумма отношений суммы квадратов отклонений наблюдаемой величины ʄо от ожидаемой величины ʄе к ожидаемой величине в каждой ячейке.
Для того, чтобы провести тест хи-квадрат с помощью SPSS, нужно выполнить следующие действия: · выбрать в меню команды Analyze (Анализ) Descriptive Statistics (Дескриптивные статистики) Crosstabs... (Таблицы сопряженности) · кнопкой Reset (Сброс) удалите возможные настройки. · перенести переменную «возраст» в список строк, а переменную «готовность голосовать» — в список столбцов. · щелкнуть на кнопке Cells... (Ячейки). В диалоговом окне установить, кроме предлагаемого по умолчанию флажка Observed, еще флажки Expected и Standardized. Подтвердить выбор кнопкой Continue. · щелкнуть на кнопке Statistics... (Статистика).
Откроется описанное выше диалоговое окно Crosstabs: Statistics. · установить флажок Chi-square (Хи-квадрат). Щелкнуть на кнопке Continue, а в главном диалоговом окне — на ОК. Получится следующая таблица сопряженности.
(2 ячейки (12,5%) имеют ожидаемую величину менее 5. Минимальная ожидаемая величина 2,33.)
Принимаются во внимание абсолютные значения остатков, превышающие 1,65. Это служит индикатором существования значимой статистической зависимости между изучаемыми признаками. Знак «плюс» в стандартизированных остатках свидетельствует о том, что реальное количество наблюдений больше ожидаемого, знак «минус» - о том, что оно меньше ожидаемого. Следует учитывать, что величина стандартизированных остатков указывает лишь на вероятность наличия линейной зависимости между изучаемыми переменными, но не на направление и интенсивность этой зависимости.
Для вычисления критерия хи-квадрат применяются три различных подхода: формула Пирсона (Pearson Chi-Square), поправка на правдоподобие (Likelihood Ratio) и тест «линейно-линейная связь» (Linear-by-Linear Association). Если таблица сопряженности имеет четыре поля и ожидаемая вероятность менее 5, дополнительно выполняется точный тест Фишера (Fishers Exact Test). Df (Ст.св.) – степени свободы, произведение количеств градаций переменных, уменьшенных на 1. Это количество ячеек таблицы, которые могут быть заполнены числами, прежде чем содержание всех остальных ячеек станет постоянным. Asymp.Sig. (Асимт. значимость) – вероятность случайности связи или р -уровень значимости. Чем меньше эта величина, тем выше статистическая значимость (достоверность) связи. При р -уровне значимости р>0,05 считается, что различия между наблюдаемыми и ожидаемыми значениями незначительны.
|
 Корреляция (от лат. correlatio - соотношение) – это статистическая взаимозависимость между признаками изучаемого явления. Корреляционный анализ представляет собой математическую процедуру, с помощью которой изучается эта взаимозависимость.
Корреляция (от лат. correlatio - соотношение) – это статистическая взаимозависимость между признаками изучаемого явления. Корреляционный анализ представляет собой математическую процедуру, с помощью которой изучается эта взаимозависимость.

 Для работы с таблицами сопряженности в программе SPSS используется команды Analyze – Descriptive Statistics - Crosstabs (Таблицы сопряженности). Например, нам нужно выяснить есть ли зависимость готовности голосовать на выборах от возраста респондентов.
Для работы с таблицами сопряженности в программе SPSS используется команды Analyze – Descriptive Statistics - Crosstabs (Таблицы сопряженности). Например, нам нужно выяснить есть ли зависимость готовности голосовать на выборах от возраста респондентов. Например, нужно установить, существует ли на самом деле статистическая зависимость двух переменных – «возраст» и «готовность голосовать на выборах».
Например, нужно установить, существует ли на самом деле статистическая зависимость двух переменных – «возраст» и «готовность голосовать на выборах».