
Дискриминантный анализ
Если критериальный показатель z измерен в номинальной шкале или связь этого показателя с исходными признаками является нелинейной и носит неизвестный характер, для определения параметров диагностической модели используются методы дискриминантного анализа. В этом случае испытуемые, результаты обследования которых представлены в ТЭД, в соответствии с внешним критерием разбиваются на группы (классы), а эффективность диагностической модели рассматривается под углом зрения ее способности разделять (дискриминировать) диагностируемые классы. Большая группа методов дискриминантного анализа в той или иной мере основана на байесовской схеме принятия решения о принадлежности объектов диагностическим классам. Байесовский подход базируется на предположении, что задача сформулирована в терминах теории вероятностей и известны все представляющие интерес величины: априорные вероятности P(ωi) для классов ωi(i=1,K) и условные плотности распределения значений вектора признаков Р(х/ωi). Правило Байеса заключается в нахождении апостериорной вероятности Р(ωi/х), которая вычисляется следующим образом
Решение о принадлежности объекта хk к классу ωj принимается при выполнении условия, обеспечивающего минимум средней вероятности ошибки классификации.
Если рассматриваются два диагностических класса ω1 и ω2, то в соответствии с этим правилом принимается решение ω1 при Р (ω1/х)>Р(ω2/х) и ω2 при P(ω2/x)>Р(ω1/x). Величину Р(ωi/х) в правиле Байеса часто называют правдоподобием ωi при данном х и принятие решения осуществляется через отношение правдоподобия или через его логарифм
Для дихотомических признаков, с которыми во многих случаях приходится иметь дело при конструировании психодиагностических тестов, р-мерный вектор признаков х может принимать одно из n=2р дискретных значений v1,...,vn. Функция плотности Р(х/ωi) становится сингулярной и заменяется на Р(vk/ωi) — условную вероятность того, что х=vk при условии класса ωi. На практике в дискретном случае, как и в непрерывном, когда число исходных признаков xi велико, определение условных вероятностей встречает значительные трудности и зачастую не может быть осуществлено. Это связано, с одной стороны, с нереальностью даже простого просмотра всех точек дискретного пространства дихотомических признаков. Так, например, если использовать в качестве исходных признаков для построения диагностического правила утверждения тест-опросника MMPI, то р=550 и тем самым n=2550. С другой стороны, даже при гораздо меньшем количестве признаков для достоверной оценки условных вероятностей необходимо иметь результаты обследования весьма большого количества испытуемых. Распространённым приемом преодоления указанных трудностей служит модель, в основе которой лежит допущение о независимости исходных дихотомических признаков. Пусть для определенности компоненты вектора х принимают значения 1 либо 0. Обозначим pi=Р(xi=1/ωi) — вероятность того, что признак xi равен 1 при условии извлечения объектов из диагностического класса ω1, и qi=Р(xi=1/(ω2) — вероятность равенства 1 признака xi в классе ω2. В случае pi>qi следует ожидать, что z-й признак будет чаще принимать значение 1 в классе ω1, нежели в ω2. В предположении о независимости признаков можно представить Р(х/ωi) в виде произведения вероятностей
Логарифм отношения правдоподобия в этом случае определяется следующим образом
Видно, что данное уравнение линейно относительно признаков xi. Поэтому можно записать
где весовые коэффициенты
а величина порога
Если L(xk)>0, то принимается решение о принадлежности объекта хk к диагностическому классу ω1, а если L(xk)<0, то ω2. Приведенный результат аналогичен рассмотренным выше схемам лцнейного регрессионного анализа для независимых признаков. Можно выразить значения рi и qi с помощью обозначений, принятых для элементов таблицы сопряженности дихотомических признаков (см. табл. 2) Здесь в качестве одного из двух дихотомических признаков будет выступать индекс диагностического класса ωi. Подставив эти обозначения в логарифм, получим wi=log(bc/ad). To есть выражение для вычисления весовых коэффициентов в байесовской решающей функции для независимых признаков дает значения wi, монотонно связанные с коэффициентом Пирсона φ, который в ряде случаев может использоваться при определении коэффициентов уравнения линейной регрессии. Результаты дискриминантного и регрессионного анализа для случая двух классов во многом совпадают. Различия проистекают в основном из-за применения разных критериев эффективности диагностической модели. Если интегральным показателем качества регрессионного уравнения служит квадрат коэффициента множественной корреляции с внешним критерием, то в дискриминантном анализе этот показатель, как правило, сформулирован относительно вероятности ошибочной классификации (ВОК) исследуемых объектов. В свою очередь, для вскрытия взаимосвязи ВОК со структурой экспериментальных данных в дискриминантном анализе широко используются геометрические представления о разделении диагностируемых классов в пространстве признаков. Воспользуемся этими представлениями для описания других, отличных от байесовского, подходов дискриминантного анализа. Совокупность объектов, относящихся к одному классу ωi, образует «облако» в р-мерном пространстве Rp, задаваемом исходными признаками. Для успешной классификации необходимо, чтобы /Енюков И. С., 1986/: а) облако из ωi в основном было сконцентрировано в некоторой области Di пространства Rp; б) в область Di попала незначительная часть «облаков» объектов, соответствующих остальным классам. Построение решающего правила можно рассматривать как задачу поиска К непересекающихся областей Di(i=l,K), удовлетворяющих условиям а) и б). Дискриминантные функции (ДФ) дают определение этих областей путем задания их границ в многомерном пространстве Rp. Если объект х попадает в область Di, то будем считать, что принимается решение о принадлежности объекта к ωi. Обозначим Р (ωi/ωj) — вероятность того, что объект из класса ωj ошибочно попадает в область Di, соответствующую классу ωi. Тогда критерием правильного определения областей А будет
где Р(ωi — априорная вероятность появления объекта из ωi. Критерий Q называется критерием средней вероятности ошибочной классификации. Минимум Q достигается при использовании, в частности, рассмотренного выше байесовского подхода, который, однако, может быть практически реализован только при справедливости очень сильного допущения о независимости исходных признаков и в этом случае дает оптимальную линейную диагностическую модель. Большое количество других подходов также использует линейные дискриминантные функции, но при этом на структуру данных накладываются менее жесткие ограничения. Рассмотрим основные из этих подходов. Для случая двух классов ω1 и ω2 методы построения линейной дискриминантной функции (ЛДФ) опираются на два предположения. Первое состоит в том, что области D1 и D2, в которых концентрируются объекты из диагностируемых классов ω1 и ω2, могут быть разделены (р-1)-мерной гиперплоскостью у(х)+wo=w1x1+w2x2+...+wpxp+w0=0. Коэффициенты wi в данном случае интерпретируются как параметры, характеризующие наклон гиперплоскости к координатным осям, a wo называется порогом и соответствует расстоянию от гиперплоскости до начала координат. Преимущественное расположение объектов одного класса, например ω1, по одну сторону гиперплоскости выражается в том, что для них, большей частью, будет выполняться условие у(х)<0, а для объектов другого класса ω2 — обратное условие у(х)>0. Второе предположение касается критерия качества разделения областей D1 и D2 гиперплоскостью у(х)+wo=0. Наиболее часто предполагается, что разделение будет тем лучше, чем дальше отстоят друг от друга средние значения случайных величин m1=Е{у(х)}, х є ω1 и m2=Е{у(х)},х є ω2 где Е{ •} — оператор усреднения. В простейшем случае полагают, что классы ω1 и ω2 имеют одинаковые ковариационные матрицы S1=S2=S. Тогда вектор оптимальных весовых коэффициентов w определяется следующим образом /Андерсон Т., 1963/
где μi — вектор средних значений признаков для класса ωi. Весовые коэффициенты обеспечивают максимум критерия
где σ2у — дисперсия у(х), полагаемая одинаковой для обоих классов. Максимальное значение h2(w) носит название расстояния Махаланобиса между классами ω1 и ω2 и равно
Для определения величины порога wo вводят предположение о виде законов распределения объектов. Если объекты каждого класса имеют многомерное нормальное распределение с одинаковой ковариационной матрицей S и векторами средних значений μi, то пороговое значение wo, минимизирующее критерий Q, будет
Верно следующее утверждение об оптимальности ЛДФ: если объекты из ωi(i=l,2) распределены согласно многомерному нормальному закону с одинаковой ковариационной матрицей, то решающее правило w'x>w0, параметры которого определены, является наилучшим в смысле критерия средней вероятности ошибочной классификации. Для случая, когда число классов больше двух (К>2), обычно определяется К дискриминантных весовых векторов (направлений)
и пороговые величины
Объект х относится к классу ωi, если выполняется условие
где gj(x) = wj'/x—woj. В формулы вычисления пороговых значений wo и woi входят величины априорных вероятностей Р(ωi). Априорная вероятность Р(ωi) соответствует доле объектов, относящихся к классу ωi в большой серии наблюдений, проводящейся в некоторых стационарных условиях. Обычно Р(ωi) неизвестны. Поэтому при решении практических задач, не меняя дискриминантных весовых векторов, эти значения задаются на основании субъективных оценок исследователя. Также нередко полагают эти значения равными или пропорциональными объемам обучающих выборок из рассматриваемых диагностических классов. Другой подход к определению параметров линейных дискриминантных функций использует в качестве критерия соотношение внутриклассовой дисперсии проекций объектов на направление у(х)=w'x с общей дисперсией проекций объединенной выборки. Обычно используются те же предположения, что и в предыдущем случае. А именно, классы ωi(i=l,K) представлены совокупностями нормально распределенных в р-мерном пространстве объектов с одинаковыми ковариационными матрицами S и векторами средних значений μi. Обозначим С — ковариационную матрицу объединенной совокупности объектов объема
Дисперсия проекций всей совокупности объектов на направление у(х) составит c2у=w'Cw, а внутриклассовая дисперсия будет S2y=w'Sw. Таким образом, критерий оптимальности выбранного направления у(х) для разделения классов ωi запишется в следующем виде:
Это отношение показывает, во сколько раз суммарная дисперсия, которая обусловлена как внутриклассовым разбросом, так и различиями между классами, больше дисперсии, обусловленной только внутриклассовым разбросом. Весовой вектор w, удовлетворяющий данному уравнению, исходя из рассмотренной ранее геометрической интерпретации линейной диагностической модели, задает новую координатную ось в р-мерном пространстве y(x)=w'x (||w||=1) с максимальной неоднородностью исследуемой совокупности объектов. Новой переменной у(х)=w'x соответствует, no-существу, первая главная компонента объединенной совокупности объектов, полученная с учетом дополнительной обучающей информации о принадлежности объектов диагностическим классам ωi. Весовой вектор w, при котором достигается максимальное значение критерия оптимальности выбранного направления, определяется в результате решения обобщенной задачи на собственные значения
Всего существует р собственных векторов, удовлетворяющих приведенному уравнению. Эти векторы упорядочивают по величине собственных чисел l1>l2>...>lp и получают систему ортогональных канонических направлений w1,..., wp. Минимальное значение отношения
равно 1 и означает, что для выбранного направления w весь имеющийся разброс переменной у(х) объясняется только внутриклассовым разбросом и не несет никакой информации о различии между классами ωi. Для случая К=2 оценка весового дискриминантного вектора wF=S-1(μ1-μ2) является собственным вектором для (C-1S)w=0 с собственным числом lF=T2+1. Любой вектор, ортогональный wF, будет также решением (C-1S)w=0 с собственным значением равным единице. Поэтому для ответа на вопрос, какое число n<р канонических направлений необходимо учесть при К>2, чтобы не потерять информацию о межклассовых различиях, проверяют гипотезу Hо о равенстве единице последних р-n собственных чисел. Процедура такой проверки изложена, например, в /Енюков И. С., 1986/. Там же достаточно подробно для практического применения рассматриваются некоторые другие аспекты дискриминантного анализа. Рассмотренные выше методы определения дискриминантных весовых векторов приводят к оптимальным результатам при соблюдении достаточно жестких условий нормальности распределений объектов внутри классов и равенства ковариационных матриц Si. В практике психодиагностических исследований эти условия, как правило. не выполняются. Но отклонения реальных распределений объектов от нормального и различия ковариационных матриц, которые в отдельных случаях хорошо теоретически изучены, не являются главными причинами ограниченного применения классических формул дискриминантного анализа. Здесь, как и при построении регрессионных психодиагностических моделей, качественный и дихотомический характер признаков, их большое количество и наличие групп связанных признаков обусловливают применение «грубых» алгоритмов нахождения дискриминантных функций. Данные алгоритмы также в основном сводятся к отбору информативных признаков с помощью эвристических процедур k — лучших признаков и последовательного увеличения и уменьшения группы признаков. Отличие указанных процедур заключается в иных критериях оптимальности признаков, чем при построении регрессионных моделей. Такие критерии в дискриминантном анализе формулируются относительно средней вероятности ошибочной классификации и часто мерой информативности признака при его добавлении в группу признаков или исключения из группы, не зависящей от объема группы, служит /Енюков И. С., 1986/
где Т2 — расстояние Махаланобиса между двумя диагностируемыми классами ω1 и ω2; с-1=N1-1+N2-1, В целом можно заключить, что для двух классов методы дискриминантного анализа во многом аналогичны методам регрессионного анализа. Расширением по отношению к регрессионной схеме в дискриминантном анализе служит представление о разделяющих границах диагностируемых классов, которое может приводить к более изощренным формам этих границ и процедурам их нахождения.
|


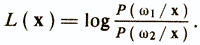











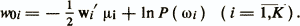

 , a μ0 — вектор средних значений этой совокупности. Выражение С через S и дается следующей формулой:
, a μ0 — вектор средних значений этой совокупности. Выражение С через S и дается следующей формулой:






